C++ 面试高频问题手册 #
本文整理C++的非常高频的相关面试题。
C 和 C++ 之间的区别是什么? #
C 和 C++ 是两种广泛使用的编程语言,二者既有联系也存在诸多区别.
语言范式 #
C 语言:是一种面向过程的编程语言。它主要关注解决问题的步骤和过程,通过函数将不同的任务模块化。
程序的执行流程是按照函数的调用顺序依次进行。
比如,我们编写一个计算两个数之和的程序,会定义一个求和函数,然后在主函数中调用该函数完成计算。
#include <stdio.h>
// 定义求和函数
int add(int a, int b) {
return a + b;
}
int main() {
int num1 = 3, num2 = 5;
int result = add(num1, num2);
printf("两数之和为: %d\n", result);
return 0;
}
C++ 语言:是一种多范式编程语言,支持面向过程、面向对象和泛型编程。面向对象编程是 C++ 的重要特性,它将数据和操作数据的方法封装在类中,通过类的实例(对象)来实现程序的功能。
泛型编程则允许编写与数据类型无关的代码,提高代码的复用性。例如,使用 C++ 的类来实现上述求和功能:
#include <iostream>
// 定义一个求和类
class Adder {
public:
int add(int a, int b) {
return a + b;
}
};
int main() {
Adder adder;
int num1 = 3, num2 = 5;
int result = adder.add(num1, num2);
std::cout << "两数之和为: " << result << std::endl;
return 0;
}
数据抽象和封装 #
C 语言:没有内置的机制来实现数据抽象和封装。虽然可以使用结构体来组织数据,但结构体中的成员通常是公开的,外部代码可以直接访问和修改这些成员,这可能导致数据的不一致性和安全性问题。
#include <stdio.h>
// 定义一个结构体
struct Point {
int x;
int y;
};
int main() {
struct Point p;
p.x = 10;
p.y = 20;
printf("点的坐标为: (%d, %d)\n", p.x, p.y);
return 0;
}
C++ 语言:通过类和访问修饰符(如 private、protected、public)实现了数据抽象和封装。类中的私有成员只能通过类的公有成员函数来访问和修改,从而隐藏了数据的实现细节。
#include <iostream>
// 定义一个类
class Point {
private:
int x;
int y;
public:
void setCoordinates(int a, int b) {
x = a;
y = b;
}
void printCoordinates() {
std::cout << "点的坐标为: (" << x << ", " << y << ")" << std::endl;
}
};
int main() {
Point p;
p.setCoordinates(10, 20);
p.printCoordinates();
return 0;
}
继承和多态 #
- C 语言:不支持继承和多态的概念。继承是指一个类可以继承另一个类的属性和方法,多态是指不同的对象可以对同一消息做出不同的响应。
- C++ 语言:支持继承和多态。通过继承,子类可以复用父类的代码,并且可以添加自己的特性。多态可以通过虚函数和指针或引用实现,使得程序在运行时能够根据对象的实际类型来调用相应的函数。
#include <iostream>
// 定义基类
class Shape {
public:
virtual void draw() {
std::cout << "绘制形状" << std::endl;
}
};
// 定义派生类
class Circle : public Shape {
public:
void draw() override {
std::cout << "绘制圆形" << std::endl;
}
};
int main() {
Shape* shape = new Circle();
shape->draw();
delete shape;
return 0;
}
标准库 #
- C 语言:标准库主要提供了一些基本的输入输出、字符串处理、数学运算等函数,如
printf、scanf、strlen、sqrt等。这些函数以头文件的形式提供,使用时需要包含相应的头文件。
#include <stdio.h>
#include <math.h>
int main() {
double num = 16.0;
double result = sqrt(num);
printf("16的平方根是: %f\n", result);
return 0;
}
- C++ 语言:除了兼容 C 语言的标准库外,还拥有自己的标准模板库(STL)。STL 提供了丰富的容器(如
vector、list、map等)、算法(如sort、find等)和迭代器,大大提高了开发效率。
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {3, 1, 4, 1, 5, 9};
std::sort(numbers.begin(), numbers.end());
for (int num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
错误处理 #
- C 语言:通常使用返回错误码的方式来处理错误。函数在执行过程中如果出现错误,会返回一个特定的错误码,调用者需要根据这个错误码来判断函数的执行情况。这种方式比较繁琐,容易出错。
#include <stdio.h>
#include <errno.h>
int divide(int a, int b, int* result) {
if (b == 0) {
errno = EDOM;
return -1;
}
*result = a / b;
return 0;
}
int main() {
int num1 = 10, num2 = 0;
int result;
if (divide(num1, num2, &result) == -1) {
perror("除法运算出错");
} else {
printf("结果为: %d\n", result);
}
return 0;
}
- C++ 语言:引入了异常处理机制,使用
try、catch和throw关键字来处理异常。当程序出现异常时,可以抛出一个异常对象,调用者可以在catch块中捕获并处理这个异常,使错误处理更加清晰和灵活。(但,平时编程中,还是建议使用错误码方式)
#include <iostream>
int divide(int a, int b) {
if (b == 0) {
throw std::runtime_error("除数不能为零");
}
return a / b;
}
int main() {
int num1 = 10, num2 = 0;
try {
int result = divide(num1, num2);
std::cout << "结果为: " << result << std::endl;
} catch (const std::runtime_error& e) {
std::cerr << "错误: " << e.what() << std::endl;
}
return 0;
}
C 与 C++ 核心区别对比 #
C++ 中有哪些不同的数据类型? #
基本数据类型 #
整数类型:用于存储整数数值,有不同的长度和符号属性。
int:最常用的整数类型,一般占 32 位,可存储范围约为 -21 亿到 21 亿,适合存储日常使用的整数。short:通常为 16 位,存储范围较小,适用于存储数值范围明确且较小的整数,能节省内存。long:一般为 32 位或 64 位,存储范围比int更大,用于存储较大的整数。long long:通常占 64 位,可存储非常大的整数,适用于处理大数值计算。- 这些类型都有对应的无符号版本(如
unsigned int),只能存储非负整数,存储的正数范围比有符号类型更大。
浮点类型:用于存储小数。
float:单精度浮点型,占 32 位,精度相对较低,适用于对精度要求不高的计算场景。double:双精度浮点型,占 64 位,精度比float高,是处理浮点运算时更常用的类型。long double:扩展精度浮点型,精度更高,占用位数因编译器而异,用于对精度要求极高的科学计算等场景。
字符类型:用于存储单个字符。
char:通常占 1 个字节,可表示 ASCII 字符集里的字符,是最常用的字符类型。wchar_t:宽字符类型,用于表示宽字符集,如 Unicode 字符,可处理多种语言的字符。char16_t和char32_t:分别用于表示 16 位和 32 位的字符,常用于处理 UTF - 16 和 UTF - 32 编码的字符。
布尔类型:只有两个取值,
true(真)和false(假),常用于逻辑判断。bool:占一个字节,让代码中的逻辑表达更清晰。
派生数据类型 #
数组:由相同类型元素组成的集合,元素存储在连续的内存位置。
- 例如:
int arr[5];定义了一个包含 5 个整数的数组,可通过下标访问每个元素。
- 例如:
指针:存储变量的内存地址,通过指针可以间接访问和操作内存中的数据。
- 例如:
int* ptr;定义了一个指向整数的指针,可用于动态内存分配和操作。
- 例如:
引用:变量的别名,对引用的操作等同于对被引用变量的操作。
- 例如:
int num = 10; int& ref = num;这里ref就是num的引用,改变ref的值,num的值也会改变。
- 例如:
函数:实现特定功能的代码块,可通过参数传递数据,执行相应操作并返回结果。
- 例如:
int add(int a, int b) { return a + b; }定义了一个返回两个整数之和的函数。
- 例如:
用户自定义数据类型 #
- 结构体:可以包含不同类型的数据成员,将相关的数据组织在一起。
- 例如:
struct Person {
std::string name;
int age;
};
这里定义了一个Person结构体,包含姓名和年龄两个成员。
- 类:面向对象编程的核心,类中可包含数据成员和成员函数,用于实现数据的封装和操作。例如:
class Rectangle {
private:
int length;
int width;
public:
Rectangle(int l, int w) : length(l), width(w) {}
int area() { return length * width; }
};
定义了一个Rectangle类,有长和宽两个私有成员,以及计算面积的成员函数。
- 枚举:定义了一组命名的整数常量,使代码更具可读性。例如:
enum Color { RED, GREEN, BLUE };
定义了一个Color枚举,包含红、绿、蓝三种颜色的常量。
C++ 中的引用是什么? #
在 C++ 中,引用是为另一个变量创建别名的另一种方式。
引用作为变量的同义词,允许你直接访问变量而不需要任何额外的语法。
它们必须在创建时初始化,并且之后不能改变以引用另一个变量。这个特性使得在函数中操作变量时避免了复制大对象的开销。
引用变量前面有一个 & 符号。
语法:
int tmp = 10;
// 引用变量
int& ref = tmp;
C++ 中值传递和引用传递的区别? #
回答重点 #
1)值传递:在函数调用时,会触发一次参数的拷贝动作,所以对参数的修改不会影响原始的值。如果是较大的对象,复制整个对象,效率较低。
2)引用传递:函数调用时,函数接收的就是参数的引用,不会触发参数的拷贝动作,效率较高,但对参数的修改会直接作用于原始的值。
扩展知识 #
看两种传递方式的示例代码:
值传递
void modify_value(int value) {
value = 100; // 只会修改函数内部的副本,不会影响原始变量
}
int main() {
int a = 20;
modify_value(a);
std::cout << a; // 20,没变
return 0;
}
引用传递
void modify_value(int& value) {
value = 100; // 修改引用指向的原始变量
}
int main() {
int a = 20;
modify_value(a);
std::cout << a; // 100,因为是引用传递,所以这里已经改为了100
return 0;
}
深入理解 #
什么场景下使用引用传递? #
- 避免不必要的数据拷贝:对于比较大的对象参数(比如 std::vector、std::string、std::list),因为拷贝会导致大量的内存和时间开销。而引用传递可以避免这些开销。
- 允许函数修改实参原始值:有时候,我们就是希望函数能够直接修改传入的变量值,这时使用引用传递很合理。
什么场景下使用值传递? #
- 小型数据结构:对于 int、char、double、float 这种基础数据类型,可以直接简单的使用值传递。
- 不希望函数修改实参:有时候,我们需要修改变量数据,但是又不希望修改原始值,可以考虑使用值传递。
值定义和引用定义 #
栈和链表,是在栈上分配内存还是堆上分配内存呢?两种情况都有可能,如果我们是在函数内直接创建的话,则是栈分配内存,如果是通过指针创建的话,则是在堆上分配内存,并且需要手动删除
栈上分配
#include<iostream>
int main() {
int arr[5] = {1, 2, 3, 4, 5}; // 在栈上分配一个包含 5 个整数的数组
for (int i = 0; i < 5; ++i) {
std::cout<< arr[i] << " ";
}
return 0;
}
堆上分配
#include<iostream>
int main() {
int* arr = new int[5]{1, 2, 3, 4, 5}; // 在堆上分配一个包含 5 个整数的数组
for (int i = 0; i < 5; ++i) {
std::cout<< arr[i] << " ";
}
delete[] arr; // 释放堆上分配的数组内存
return 0;
}
当然链表也可以这样,无论是结构体还是类,都有两种定义方式,值定义和引用定义,值定义则是栈分配内存,引用定义则是堆分配内存。
#include<iostream>
struct MyStruct {
int x;
};
class MyClass {
public:
int x;
};
int main() {
// 结构体的值定义
MyStruct structVar1{42};
// 结构体的引用定义
MyStruct* structVar2 = new MyStruct{42};
// 类的值定义
MyClass classVar1{42};
// 类的引用定义
MyClass* classVar2 = new MyClass{42};
// 释放堆上分配的内存
delete structVar2;
delete classVar2;
return 0;
}
C++ 值传递 vs 引用传递对比 #
🌟C++ 中 static 的作用?什么场景下用到 static? #
谈到 C++ 的 static,可以重点回答以下几个方面:
1)修饰局部变量:当 static 用于修饰局部变量时,这个变量的存储位置会在程序执行期间保持不变,且只在程序执行到该变量的声明处时初始化一次。
即使函数被多次调用,static 局部变量也只在第一次调用时初始化,之后的调用将不会重新初始化它。
2)修饰全局变量或函数:当 static 用于修饰全局变量或函数时,限制了这些变量或函数的作用域,它们只能在定义它们的文件内部访问。有助于避免在不同文件之间的命名冲突。
3)修饰类的成员变量或函数:在类内部,static 成员变量或函数属于类本身,而不是类的任何特定对象。这意味着所有对象共享同一个 static 成员变量,无需每个对象都存储一份拷贝。static 成员函数可以在没有类实例的情况下调用。
static 的用法 #
static局部变量
#include <iostream>
using namespace std;
void func() {
static int count = 0; // 只在第一次调用func时初始化
cout << "Count is: " << count << endl;
count++;
}
int main() {
for(int i = 0; i < 5; i++) {
func(); // 每次调用都会显示增加的count值
}
return 0;
}
static全局变量或函数
// file1.cpp
static int count = 10; // count变量只能在file1.cpp中访问
static void func() { // func函数只能在file1.cpp中访问
cout << "Function in file1" << endl;
}
// file2.cpp
extern int count; // 这里会导致编译错误,因为count是static的,不能在file2.cpp中访问
void anotherFunc() {
func(); // 这里也会导致编译错误,因为func是static的,不能在file2.cpp中访问
}
static类的成员变量或函数
#include <iostream>
using namespace std;
class MyClass {
public:
static int staticValue; // 静态成员变量
static void staticFunction() { // 静态成员函数
cout << "Static function called" << endl;
}
};
int MyClass::staticValue = 10; // 静态成员变量的初始化
int main() {
MyClass::staticFunction(); // 调用静态成员函数
cout << MyClass::staticValue << endl; // 访问静态成员变量
return 0;
}
使用场景总结 #
static局部变量:当你需要在函数的多次调用之间保持某个变量的值时。static全局变量或函数:当你想要限制变量或函数的作用域,防止它们在其他文件中被访问时。static类的成员变量或函数:当你想要类的所有对象共享某个变量或函数时,或者当你想要在没有类实例的情况下访问某个函数时。
static 线程安全吗 #
static 局部变量在 C++11 及之后的初始化是线程安全的,在 C++11 之前非线程安全,需要手动加锁。
static 的全局变量在程序启动前(main 之前)完成的,默认就是线程安全的。
而无论初始化是否安全,多线程访问 static 变量都不是线程安全的,都需要显式的处理同步问题。
🌟C++ 中 const 的作用?谈谈你对 const 的理解? #
回答重点 #
const 最主要的作用就是声明一个变量为常量,即这个变量的值在初始化之后就不能被修改。
但 const 不仅可以用作普通常量,还可以用于指针、引用、成员函数、成员变量等。
具体作用如下:
1)定义普通常量:当修饰基本数据类型的变量时,表示常量含义,对应的值不能被修改。
const int MAX_SIZE = 100; // MAX_SIZE是一个常量,其值不能被修改
2)修饰指针:这里分多种情况,比如指针本身是常量,指针指向的数据是常量,或者指针本身和其指向的数据都是常量。
3)修饰引用:const 修饰引用时,一般用作函数参数,表示函数不会修改传递的参数值。
void func(const int& a) { // a是一个对常量的引用,不能通过a修改其值
// ...
}
4)修饰类成员函数:const 修饰成员函数,表示函数不会修改类的任何成员变量,除非这些成员变量被声明为 mutable。
class MyClass {
public:
void myFunc() const { // myFunc是一个const成员函数,它不会修改类的任何成员变量
// ...
}
};
5)修饰类成员变量:const 修饰成员变量,表示生命期内不可改动此值。
class MyClass {
public:
const int a = 5;
};
扩展知识 #
const 修饰指针时,可以分多种情况:
1)指向常量的指针:指针指向的内容是常量,不能通过该指针修改其所指向的值。
const intptr = &x; // ptr是一个指向常量的指针,不能通过ptr修改x的值
2)指针常量:指针本身是常量,指针的值(即指向的地址)不能被修改,但可以通过该指针修改其所指向的值(如果所指向的不是常量)。
int* const ptr = &x; // ptr是一个常量,ptr的值(地址)不能被修改,但x的值可以被修改
3)指向常量的常量指针:指针本身是常量,且指针指向的内容也是常量。
const int* const ptr = &x; // ptr的值和ptr指向的值都不能被修改
解释 C++ 中的构造函数。 #
C++ 中的构造函数是一种特殊的成员函数,与类同名,无返回类型,用于在创建对象时,对对象进行初始化,有默认、带参、拷贝等多种类型,保证对象创建后处于有效状态。
C++ 中的析构函数是什么? #
析构函数是 C++ 里的一种特殊成员函数,它和类同名,不过前面得加个波浪线 ~,没有返回值,也不能有参数。
它的主要作用是在对象的生命周期结束时,做一些清理工作,像释放对象占用的动态内存、关闭打开的文件之类的。
当对象离开作用域或者用 delete 删除动态分配的对象时,析构函数就会自动被调用,保证资源能被正确释放,避免内存泄漏等问题。就好比你离开房间的时候,要把房间里的东西收拾好,把灯关掉一样。
什么是虚析构函数? #
虚析构函数就是在基类里用 virtual 关键字声明的析构函数。当用基类指针指向派生类对象,且通过该指针删除对象时,若基类析构函数不是虚拟的,那就只会调用基类析构函数,派生类析构函数不会被调用,可能造成资源泄漏;但如果基类析构函数是虚拟的,程序在运行时会先调用派生类析构函数,再调用基类析构函数,确保派生类对象能被完整地销毁。
析构函数重载是否可能?如果可以,那么解释;如果不可以,那么为什么? #
答案是不可以,我们不能重载析构函数。每个类中只能有一个析构函数。同样需要提到的是,析构函数既不接受参数,也没有可能帮助重载的参数。
🌟C++ 中都有哪些构造函数? #
回答重点 #
- 默认构造函数:这就是普通的构造函数,如果没有构建的话,则会默认帮你创建
- 参数构造函数:带有参数的构造函数,允许创建对象时传递参数,以便根据这些参数初始化对象
- 拷贝构造函数:拷贝构造函数用于通过已有对象初始化新对象,接收一个同类型对象的引用作为参数,可以理解为拷贝了一个情况相同的对象,但是分别位于不同的内存块,修改新对象的状态不会影响源对象,反之亦然。
- 委托构造函数:允许在一个构造函数内部调用另一个构造函数,从而减少代码重复,这通过在构造函数的初始化列表中使用 this 指针调用另一个构造函数来实现
扩展知识 #
直接看代码,方便我们理解:
#include<iostream>
class MyClass {
public:
// 默认构造函数
MyClass() {
std::cout << "Default constructor called."<< std::endl;
}
// 参数化构造函数
MyClass(int a) : x(a) {
std::cout << "Parameterized constructor called."<< std::endl;
}
// 拷贝构造函数
MyClass(const MyClass& other) {
x = other.x;
std::cout << "Copy constructor called."<< std::endl;
}
// 委托构造函数
MyClass() : MyClass(0) {
std::cout << "Delegating constructor called."<< std::endl;
}
MyClass(int a) : x(a) {
std::cout << "Parameterized constructor called."<< std::endl;
}
private:
int x;
};
int main() {
// 使用默认构造函数创建对象
MyClass obj1;
// 使用参数化构造函数创建对象
MyClass obj2(42);
// 使用拷贝构造函数创建对象
MyClass obj3(obj2);
// 使用委托构造函数创建对象
MyClass obj4;
return 0;
}
哪些操作允许在指针上进行? #
在 C++ 里,指针允许进行下面这些操作:
赋值操作 #
可以把一个变量的地址赋给指针,或者让一个指针指向另一个指针所指向的地址。比如:
int num = 10;
int* ptr = # // 把num的地址赋给ptr
int* anotherPtr = ptr; // anotherPtr指向ptr所指向的地址
解引用操作 #
使用解引用操作符 * 能访问指针所指向的变量的值。例如:
int num = 10;
int* ptr = #
cout << *ptr; // 输出10
指针算术运算 #
- 指针加整数:可以让指针向后移动若干个元素的位置。假设
ptr是指向数组元素的指针,ptr + n就表示向后移动n个元素。
int arr[5] = {1, 2, 3, 4, 5};
int* ptr = arr;
int* newPtr = ptr + 2; // newPtr指向arr[2]
- 指针减整数:和加整数相反,是让指针向前移动若干个元素的位置。
- 指针减指针:两个指向同一个数组元素的指针相减,得到的是它们之间元素的个数。
比较操作 #
可以对指针进行比较,比如判断两个指针是否指向同一个地址,或者一个指针是否大于、小于另一个指针。
int arr[5] = {1, 2, 3, 4, 5};
int* ptr1 = &arr[0];
int* ptr2 = &arr[2];
if (ptr1 < ptr2) {
cout << "ptr1在ptr2前面";
}
类型转换 #
能把指针从一种类型转换为另一种类型,但要注意这样做可能会带来风险,得谨慎使用。
int num = 10;
int* intPtr = #
char* charPtr = reinterpret_cast<char*>(intPtr); // 强制类型转换
delete 运算符的目的是什么? #
delete 运算符用于释放通过 new 运算符在堆上动态分配的内存,调用对象的析构函数完成资源清理,防止内存泄漏。
delete []与 delete 的区别是什么? #
delete 用于释放单个由 new 分配的对象的内存并调用其析构函数,而 delete [] 用于释放由 new[] 分配的数组对象的内存,会依次调用数组中每个对象的析构函数。
C++ 中 char*、const char*、char* const、const char* const 的区别? #
回答重点 #
一个小技巧,从后往前读:
1)char*:这是一个指向 char 类型数据的指针,指针以及它指向的数据都是可变的。可以改变指针的指向和指向的数据。
2)const char*:*指向 const char,这是一个指向 const char 类型数据的指针。指针本身是可变的,但指针指向的数据是不可变的。简单来说,可以改变指针的指向,但不能改变它指向的数据内容。
3)char* const:const 修饰 char*,这是一个指向 char 类型数据的常量指针。指向的数据是可变的,但指针本身是不可变的。也就是说,不能改变指针的指向,但能修改指向的数据。
4)const char* const:这是一个指向 const char 类型数据的常量指针。指针和指向的数据都是不可变的,也就是既不能改变指针的指向,也不能修改指针指向的数据。
扩展知识 #
看一些代码示例。
1)char*:
char data[] = "Hello";
char* p = data;
p[0] = 'h'; // 修改数据内容,是允许的
p = nullptr; // 改变指针指向,是允许的
2)const char*:
const char* p = "Hello";
p[0] = 'h'; // 错误:不能修改数据内容
p = "World"; // 允许:改变指针指向
3)char* const:
char data[] = "Hello";
char* const p = data;
p[0] = 'h'; // 允许:修改数据内容
p = nullptr; // 错误:不能改变指针指向
4)const char* const:
const char* const p = "Hello";
p[0] = 'h'; // 错误:不能修改数据内容
p = "World"; // 错误:不能改变指针指向
除了这些类型修饰符,理解指针和引用在函数参数中的应用也很重要。
比如在接口设计中,通过使用 const char* 可以保证函数不会修改传入的字符串数据,从而提高代码的安全性。
合理使用 const 也有助于避免潜在的错误。例如,较为复杂的类和对象也可以通过 const 修饰,来确保在调用成员函数时不会意外修改对象的状态。
🌟C++ 中数组和指针的区别? #
回答重点 #
主要的区别可以总结为以下几点:
1)内存分配:
- 数组:编译器会在栈上为数组的所有元素分配连续的内存空间。
- 指针:指针本身只占用一个内存单元(通常是 4 或 8 字节),它存储的是一个地址。初始化指针之后,可以通过动态内存分配(例如使用
new或malloc)来分配内存。
2)固定与动态大小:
- 数组:数组的大小在声明时就确定了,数组的大小需要是常量,无法在运行时改变。
- 指针:指针比较灵活,它指向的内存如果是堆内存,可以在运行时动态分配和释放内存,灵活性更好。
3)类型安全性:
- 数组:数组在声明时绑定了具体的类型,编译器在访问数组时可以进行类型检查。
- 指针:指针声明时也有类型,但指针所指向的内存地址可以重新赋值,容易引起类型不匹配的问题,可能导致运行时错误,特别是指针类型经常转换的场景,比如
int*转void*等等。
4)运算操作:
- 数组:数组名可以看作是数组首元素的常量指针,但不能直接进行算术运算(如
++或--)。 - 指针:指针变量可以直接进行算术运算,比如递增、递减操作,从而访问不同的位置。
扩展知识 #
我们可以从几个方面进一步探讨:
1)数组和指针的转换:
- 在表达式中,数组名会被自动转换为指向数组首元素的地址。例如,假设
int arr[5],则arr会被转换为&arr[0]。
2)动态数组:
- 动态数组的实现需要使用指针。例如,
int* arr = new int[5];这种方式在运行时分配的内存可以随意调整大小。
3)内存管理:
- 编程时需要注意内存泄漏问题。使用指针分配的内存(例如使用
new)需要显式地释放(例如使用delete或delete[]),否则会导致内存泄漏。
4)多维数组与指针:
- 多维数组在内存中是按行优先顺序存储的,理解这一点有助于使用指针遍历多维数组。
5)高效代码:
- 在写高性能代码时,指针有时可以比数组更高效,因为指针的算术运算更加灵活。
🌟C++ 中 sizeof 和 strlen 的区别? #
回答重点 #
两者的功能其实有很大区别:
1)sizeof 是一个编译时运算符,用于获取一个类型或者对象的大小(以字节为单位)。sizeof 在编译时计算结果,不涉及实际内容。
2)strlen 是一个库函数,用于计算 C 风格字符串的长度(不包括终止字符’\0’)。strlen 是在运行时计算结果的,因为它需要遍历字符串内容。
扩展知识 #
1)sizeof 的应用:
- 用于计算基础类型的大小,比如
sizeof(int)。 - 用来计算结构体或类的内存占用,比如
sizeof(MyClass)。 - 对于静态数组,可以获取整个数组的内存大小,比如
sizeof(arr),其中arr是一个静态数组。
注意,对于指针,sizeof 返回的是指针本身的大小,而不是指针所指向的内存区域的大小。例如:
int *p = new int[10];
std::cout << sizeof(p); // 这会返回指针的大小,通常是4或8个字节,具体取决于系统架构。
2)strlen 的应用:
- 常用于计算 C 风格字符串的长度。注意,
strlen是不包括字符串末尾的终止符’\0’的。 - 对于一些特定字符数组,
strlen非常有用,比如char arr[] = "Hello";,strlen(arr)返回的是 5。
注意,strlen 不能用于未以 \0 结尾的字符数组,否则会导致未定义行为。例如:
char arr[5] = {'H', 'e', 'l', 'l', 'o'};
std::cout << strlen(arr); // 这会导致未定义行为,因为没有终止符'\0'。
3)获取动态分配内存的大小:
对于使用 new 动态分配的内存,sizeof 不能直接获取分配的内存大小。在这种情况下,需要在分配内存时显式记录内存大小。
int main() {
int n = 10;
int* arr = new int[n];
// std::cout << "Size of dynamic array: "<< sizeof(arr) << " bytes"<< std::endl; // 错误:这将输出指针的大小,而不是数组的大小
std::cout << "Size of dynamic array: " << n * sizeof(int) << " bytes"<< std::endl; // 正确:手动计算数组大小
delete[] arr;
return 0;
}
4)空类的大小
即使是一个空类(不包含任何数据成员和成员函数的类),sizeof 返回的值也至少为一个字节。这是为了确保在不同的编译器和平台上,空类的对象具有唯一标识。
class EmptyClass {};
int main() {
std::cout << "Size of EmptyClass: "<< sizeof(EmptyClass) << " bytes"<< std::endl;
return 0;
}
总结,sizeof 和 strlen 有其各自的用途和使用场景,一个用于计算类型大小,一个用于计算字符串长度。
🌟C++ 中四种类型转换的使用场景? #
回答重点 #
在 C++ 中,有四种常用的类型转换:
1)static_cast:用于在有明确定义的类型之间进行转换,如基本数据类型之间的转换以及指针或引用的上行转换(从派生类到基类)。
2)dynamic_cast:主要用于多态类型的指针或引用转换,特别适用于需要安全地执行下行转换(从基类到派生类)。
3)const_cast:用于移除对象的 const 或添加 const 属性,这在需要更改常量数据时非常有用。
4)reinterpret_cast:提供了一种最底层的转换方式,类似于 C 语言中的强转,通常用于指针类型之间的转换。
扩展知识 #
我们详细地讨论下每种类型转换的更多细节和注意事项。
1)static_cast:
- 用法:主要用于已知类型之间的转换,比如
int转换为float或者从派生类指针转换为基类指针。 - 示例:
int a = 10;
float b = static_cast<float>(a); // 将 int 转换为 float
- 注意事项:
static_cast进行的类型转换在编译时检查,但不会进行运行时检查。
2)dynamic_cast:
- 用法:主要用于多态基类,能够基于运行时类型信息将基类指针或引用转换为派生类指针或引用。
- 示例:
Base* basePtr = new Derived();
Derived* derivedPtr = dynamic_cast<Derived*>(basePtr); // 运行时检查并转换
- 注意事项:只有在类包含虚函数时才能使用
dynamic_cast,而如果转换失败,指针会返回nullptr,引用则会抛出std::bad_cast异常。
3)const_cast:
- 用法:移除或者添加常量修饰,通常在需要修改被标记为
const的数据时使用。 - 示例:
const int a = 10;
int *b = const_cast<int*>(&a); // 移除 const 属性
*b = 20; // 修改原本为 const 的值
- 注意事项:
const_cast仅影响底层 const 属性,而并不影响顶层 const。同样,修改原本为 const 的变量可能会引发未定义行为,应该谨慎使用。
4)reinterpret_cast:
- 用法:主要用于在几乎无关的类型之间进行转换,比如将指针类型转换为整型,或相反。这通常用于底层操作,比如硬件编程,或某些预期内的操作。
- 示例:
long p = 0x12345678;
inti = reinterpret_cast<int*>(p); // 将 long 转换为 int 指针
- 注意事项:这种转换不会进行类型安全检查,可能会改变位模式,应尽量避免使用,除非确实需要进行底层操作。
C++ 中 struct 和 class 的区别? #
回答重点 #
在 C++ 中,struct 和 class 的主要区别就在于它们的默认访问级别:
1)struct 的默认成员访问级别是 public。
2)class 的默认成员访问级别是 private。
扩展知识 #
虽然默认访问级别是 struct 和 class 之间的主要区别,但在实际编程中,还有一些方面也值得注意:
1)内存布局和性能:
- 在大多数情况下,
struct和class的内存布局是一样的,因为它们本质上除了访问级别之外,其他都是相同的。 - 在访问级别相同的情况下,二者的性能并无区别。
2)习惯用法:
struct一般用于表示简单的数据结构或POD(Plain Old Data)类型。POD 类是所有非静态数据成员共享相同访问级别、没有虚函数、没有继承的类。class一般用于表示复杂的数据类型,特别是在对象需要封装和抽象,以及需要使用功能性的成员函数时。
3)继承模型:
- 类可以有继承关系,通过
private、protected和public指定继承的访问级别,默认是private继承。 - 结构体同样可以有继承关系,默认是
public继承。 - 上述特指在 C++ 中,在 C 语言中的
struct是没有继承能力的。
4)编程风格:
- 代码风格和团队规范可能对
struct和class的使用有明确的指示。例如,在一个面向对象的项目中,使用class定义所有对象可能更为规范,而struct则更多地用于数据传输对象(DTO)。
5)友元函数:
- 友元函数或友元类在
struct和class中都适用,用法完全一样,唯一的区别是,如果你在struct里通常不需要那么多封装,在这种情况下友元可能用的不多。
🌟C++ 中 new 和 malloc 的区别?delete 和 free 的区别? #
回答重点 #
在 C++ 中,new 和 malloc 以及 delete 和 free 是内存管理的两对主要操作符和函数。它们虽然都有分配和释放内存的功能,但在很多方面都有区别。
newvsmalloc:new是 C++ 的操作符,而malloc是 C 标准库的函数。new分配内存并调用构造函数,而malloc仅仅分配内存,不调用构造函数。new返回一个类型安全的指针,而malloc返回void*,需要显式类型转换。new在分配失败时抛出std::bad_alloc异常,而malloc返回NULL。
deletevsfree:delete是 C++ 的操作符,而free是 C 标准库的函数。delete销毁对象并调用析构函数,然后释放内存,而free仅仅释放内存,不调用析构函数。delete必须与new配对使用,而free必须与malloc配对使用。delete和delete[]是不同的,前者用于单一对象,后者用于数组。free没有这种区分。
扩展知识 #
更多关于new和malloc的不同:
- 异常处理: 在
new语句中,如果内存分配失败,会抛出std::bad_alloc异常,你可以使用try-catch块处理这个异常。相比之下,malloc返回NULL值,需要程序员手动检查并处理。 - 类型兼容:
new更适合 C++ 中的类对象,因为它自动调用构造函数进行初始化,而malloc更适合简单的数据类型或 C 风格编程。
- 异常处理: 在
更多关于delete和free的不同:
- 使用安全性: 使用
delete时,不会像free那样导致未定义行为,因为它会调用析构函数来清理对象。在涉及复杂对象管理时,这种自动调用析构函数的特性非常有用。 - 灵活性和匹配: 使用不同类型的
delete操作符(delete和delete[])来区分释放单个对象和对象数组。free函数则没有这种灵活性。
- 使用安全性: 使用
开发建议:
- 建议尽量使用智能指针(如
std::unique_ptr和std::shared_ptr),它们可以自动管理内存,减少内存泄漏和其他潜在的内存管理问题。
- 建议尽量使用智能指针(如
🌟 左值和右值的区别? #
回答重点 #
什么是左值?什么是右值?
- 左值:可以出现在赋值运算符的左边,并且可以被取地址,通常是有名字的变量
- 右值:不能出现在赋值运算符的左边,不可以被取地址,表示一个具体的数据值,通常是常量、临时变量
一般可以从两个方向区分左值和右值。
方向 1:
- 左值:可以放到等号左边的东西叫左值。
- 右值:不可以放到等号左边的东西就叫右值。
方向 2:
- 左值:可以取地址并且有名字的东西就是左值。
- 右值:不能取地址的没有名字的东西就是右值。
示例:
int a = b + c;
a 是左值,有变量名,可以取地址,也可以放到等号左边, 表达式 b+c 的返回值是右值,没有名字且不能取地址,&(b+c)不能通过编译,而且也不能放到等号左边。
int a = 4; // a是左值,4作为普通字面量是右值
扩展知识 #
左值引用 #
可以理解为是对左值的引用。对于左值引用,等号右边的值必须可以取地址,如果不能取地址,则会编译失败,或者可以使用 const 引用形式,但这样就只能通过引用来读取输出,不能修改数组,因为是常量引用。
示例代码:
int a = 5;
int &b = a; // b是左值引用
b = 4;
int &c = 10; // error,10无法取地址,无法进行引用
const int &d = 10; // ok,因为是常引用,引用常量数字,这个常量数字会存储在内存中,可以取地址
右值引用 #
可以理解为是对右值的引用。即对一个临时对象或者即将销毁的对象的引用,开发者可以利用这些临时对象,却不需要复制它们。
如果使用右值引用,那表达式等号右边的值需要是右值,可以使用 std::move 函数强制把左值转换为右值。
int a = 4;
int &&b = a; // error, a是左值
int &&c = std::move(a); // ok
左值引用和右值引用的使用场景 #
- 左值引用:当你需要修改对象的值,或者需要引用一个持久对象时使用。
- 右值引用:当你需要处理一个临时对象,并且想要避免复制,或者实现移动语义时使用。
纯右值 #
纯右值属于右值。运算表达式产生的临时变量、不和对象关联的原始字面量、非引用返回的临时变量、lambda 表达式等都是纯右值。
举例:
- 除字符串字面值外的字面值
- 返回非引用类型的函数调用
- 后置自增自减表达式 i++、i–
- 算术表达式(a+b, a*b, a&&b, a==b 等)
- 取地址表达式等(&a)
介绍下移动语义与完美转发 #
回答重点 #
移动语义和完美转发都是 C++11 引入的新特性。
移动语义 #
一种优化资源管理的机制。常规的资源管理是拷贝别人的资源。而移动语义是转移所有权,转移了资源而不是拷贝资源,性能会更好。
移动语义通常用于那些比较大的对象,搭配移动构造函数或移动赋值运算符来使用。
示例代码:
class A {
public:
A(int size) : size_(size) {
data_ = new int[size];
}
A(){}
A(const A& a) {
size_ = a.size_;
data_ = new int[size_];
cout << "copy " << endl;
}
A(A&& a) {
this->data_ = a.data_;
a.data_ = nullptr;
cout << "move " << endl;
}
~A() {
if (data_ != nullptr) {
delete[] data_;
}
}
int *data_;
int size_;
};
int main() {
A a(10);
A b = a;
A c = std::move(a); // 调用移动构造函数
return 0;
}
如果不使用 std::move,会有很大的拷贝代价,使用移动语义可以避免很多无用的拷贝,提供程序性能,C++ 所有的 STL 都实现了移动语义,方便我们使用。例如:
std::vector<string> vecs;
...
std::vector<string> vecm = std::move(vecs); // 免去很多拷贝
完美转发 #
完美转发指可以写一个接受任意实参的函数模板,并转发到其它函数,目标函数会收到与转发函数完全相同的实参,转发函数实参是左值那目标函数实参也是左值,转发函数实参是右值那目标函数实参也是右值。
那如何实现完美转发呢?答案是使用 ``std::forward,可参考以下代码:
void PrintV(int &t) {
cout << "lvalue" << endl;
}
void PrintV(int &&t) {
cout << "rvalue" << endl;
}
template<typename T>
void Test(T &&t) {
PrintV(t);
PrintV(std::forward<T>(t));
PrintV(std::move(t));
}
int main() {
Test(1); // lvalue rvalue rvalue
int a = 1;
Test(a); // lvalue lvalue rvalue
Test(std::forward<int>(a)); // lvalue rvalue rvalue
Test(std::forward<int&>(a)); // lvalue lvalue rvalue
Test(std::forward<int&&>(a)); // lvalue rvalue rvalue
return 0;
}
分析:
- Test(1):1 是右值,模板中 T &&t 这种为万能引用,右值 1 传到 Test 函数中变成了右值引用,但是调用 PrintV() 时候, t 变成了左值,因为它变成了一个拥有名字的变量,所以打印 lvalue ,而 PrintV(std::forward(t)) 时候,会进行完美转发,按照原来的类型转发,所以打印 rvalue , PrintV(std::move(t)) 毫无疑问会打印 rvalue 。
- Test(a):a 是左值,模板中 T && 这种为万能引用,左值 a 传到 Test 函数中变成了左值引用,所以有代码中打印。
- Test(std::forward(a)):转发为左值还是右值,依赖于 T,T 是左值那就转发为左值,T 是右值那就转发为右值。
扩展知识 #
深拷贝与浅拷贝
示例代码:
class A {
public:
A(int size) : size_(size) {
data_ = new int[size];
}
A(){}
A(const A& a) {
size_ = a.size_;
data_ = a.data_;
cout << "copy " << endl;
}
~A() {
delete[] data_;
}
int *data_;
int size_;
};
int main() {
A a(10);
A b = a;
cout << "b " << b.data_ << endl;
cout << "a " << a.data_ << endl;
return 0;
}
上面代码中,两个输出的是相同的地址,a 和 b 的 data_ 指针指向了同一块内存,这就是浅拷贝,只是数据的简单赋值,那在析构时 data_ 内存会被释放两次,如何消除这种隐患呢,可以使用如下深拷贝:
class A {
public:
A(int size) : size_(size) {
data_ = new int[size];
}
A(){}
A(const A& a) {
size_ = a.size_;
data_ = new int[size_];
cout << "copy " << endl;
}
~A() {
delete[] data_;
}
int *data_;
int size_;
};
int main() {
A a(10);
A b = a;
cout << "b " << b.data_ << endl;
cout << "a " << a.data_ << endl;
return 0;
}
深拷贝就是在拷贝对象时,如果被拷贝对象内部还有指针引用指向其它资源,自己需要重新开辟一块新内存存储资源,而不是简单的赋值。
🌟C++ 中 move 有什么作用?它的原理是什么? #
回答重点 #
move 是 C++11 引入的一个新特性,用来实现移动语义。它的主要作用是将对象的资源从一个对象转移到另一个对象,而无需进行深拷贝,减少了资源内存的分配,可提高性能。
它的原理很简单,我们直接看它的源码实现:
// move
template <class T>
LIBC_INLINE constexpr cpp::remove_reference_t<T> &&move(T &&t) {
return static_cast<typename cpp::remove_reference_t<T> &&>(t);
}
从源码中你可以看到,std::move 的作用只有一个,无论输入参数是左值还是右值,都强制转成右值。
扩展知识 #
1)move 转成右值有什么好处?
这就涉及到移动语义的概念,右值可以触发移动语义,那什么是移动语义?我们可以理解为在对象转换的时候,通过右值可以触发到类的移动构造函数或者移动赋值函数。
因为触发了移动构造函数 或者 移动赋值函数,我们就默认,原对象后面已经不会再使用了(包括内部的某些内存),这样我们就可以在新对象中直接使用原对象的那部分内存,减少了数据的拷贝操作,昂贵的拷贝转为了廉价的移动,提升了程序的性能。
2)是不是 std::move 后的对象就没法使用了?
其实不是,还是取决于搭配的移动构造函数 和 移动赋值函数是如何实现的。
如果在移动构造函数 + 移动赋值函数中,还是使用了拷贝动作,那原对象还是可以使用的,见下面示例。
#include <chrono>
#include <functional>
#include <future>
#include <iostream>
#include <string>
class A {
public:
A() {
std::cout << "A() \n";
}
~A() {
std::cout << "~A() \n";
}
A(const A& a) {
count_ = a.count_;
std::cout << "A copy \n";
}
A& operator=(const A& a) {
count_ = a.count_;
std::cout << "A = \n";
return *this;
}
A(A&& a) {
count_ = a.count_;
std::cout << "A move \n";
}
A& operator=(A&& a) {
count_ = a.count_;
std::cout << "A move = \n";
return *this;
}
std::string count_;
};
int main() {
A a;
a.count_ = "12345";
A b = std::move(a);
std::cout << a.count_ << std::endl;
std::cout << b.count_ << std::endl;
return 0;
}
如果我们在移动构造函数 + 移动赋值函数中,将原对象内部内存废弃掉,新对象使用原对象内存,那原对象的内存就不可以用了,示例代码如下:
#include <chrono>
#include <functional>
#include <future>
#include <iostream>
#include <string>
class A {
public:
A() {
std::cout << "A() \n";
}
~A() {
std::cout << "~A() \n";
}
A(const A& a) {
count_ = a.count_;
std::cout << "A copy \n";
}
A& operator=(const A& a) {
count_ = a.count_;
std::cout << "A = \n";
return *this;
}
A(A&& a) {
count_ = std::move(a.count_);
std::cout << "A move \n";
}
A& operator=(A&& a) {
count_ = std::move(a.count_);
std::cout << "A move = \n";
return *this;
}
std::string count_;
};
int main() {
A a;
a.count_ = "12345";
A b = std::move(a);
std::cout << a.count_ << std::endl;
std::cout << b.count_ << std::endl;
return 0;
}
总结:
- std::move 函数的作用是将参数强制转换为右值。而且,只是转换为右值,并不会对对象进行任何操作。
- 转换为右值可以触发移动语义,减少数据的拷贝操作,提升程序的性能。
- 在使用 std::move 函数后,原对象是否可以继续使用取决于移动构造函数和移动赋值函数的实现。
介绍 C++ 中三种智能指针的使用场景? #
回答重点 #
C++ 中的智能指针主要用于管理动态分配的内存,避免内存泄漏。
C++11 标准引入了三种主要的智能指针:std::unique_ptr、std::shared_ptr 和 std::weak_ptr:
1. std::unique_ptr
#
std::unique_ptr 是一种独占所有权的智能指针,意味着同一时间内只能有一个 unique_ptr 指向一个特定的对象。当 unique_ptr 被销毁时,它所指向的对象也会被销毁。
使用场景:
- 当你需要确保一个对象只被一个指针所拥有时。
- 当你需要自动管理资源,如文件句柄或互斥锁时。
示例代码:
#include <iostream>
#include <memory>
class Test {
public:
Test() { std::cout << "Test::Test()"; }
~Test() { std::cout << "Test::~Test()"; }
void test() { std::cout << "Test::test()"; }
};
int main() {
std::unique_ptr<Test>
ptr(new Test());
ptr->test();
// 当ptr离开作用域时,它指向的对象会被自动销毁return 0;
}
2. std::shared_ptr
#
std::shared_ptr 是一种共享所有权的智能指针,多个 shared_ptr 可以指向同一个对象。内部使用引用计数来确保只有当最后一个指向对象的 shared_ptr 被销毁时,对象才会被销毁。
使用场景:
- 当你需要在多个所有者之间共享对象时。
- 当你需要通过复制构造函数或赋值操作符来复制智能指针时。
示例代码:
#include <iostream>
#include <memory>
class Test {
public:
Test() { std::cout << "Test::Test()"; }
~Test() { std::cout << "Test::~Test()"; }
void test() { std::cout << "Test::test()"; }
};
int main() {
std::shared_ptr<Test> ptr1(new Test());
std::shared_ptr<Test> ptr2 = ptr1;
ptr1->test();
// 当ptr1和ptr2离开作用域时,它们指向的对象会被自动销毁
return 0;
}
3. std::weak_ptr
#
std::weak_ptr 是一种不拥有对象所有权的智能指针,它指向一个由 std::shared_ptr 管理的对象。weak_ptr 用于解决 shared_ptr 之间的循环引用问题。
是另外一种智能指针,它是对 shared_ptr 的补充,std::weak_ptr 是一种弱引用智能指针,用于观察 std::shared_ptr 指向的对象,而不影响引用计数。它主要用于解决循环引用问题,从而避免内存泄漏,另外如果需要追踪指向某个对象的第一个指针,则可以使用 weak_ptr。
可以考虑在对象本身中维护一个指向第一个 shared_ptr 的弱引用(std::weak_ptr)。当创建对象的第一个 shared_ptr 时,将这个 shared_ptr 赋值给对象的 weak_ptr 成员。这样,在需要时,可以通过检查对象的 weak_ptr 成员来获取指向对象的第一个 shared_ptr(如果仍然存在的话).
使用场景:
- 当你需要访问但不拥有由
shared_ptr管理的对象时。 - 当你需要解决
shared_ptr之间的循环引用问题时。 - 注意
weak_ptr肯定要和shared_ptr搭配使用。
示例代码:
#include <iostream>
#include <memory>
class Test {
public:
Test() { std::cout << "Test::Test()"; }
~Test() { std::cout << "Test::~Test()"; }
void test() { std::cout << "Test::test()"; }
};
int main() {
std::shared_ptr<Test> sharedPtr(new Test());
std::weak_ptr<Test> weakPtr = sharedPtr;
if (auto lockedSharedPtr = weakPtr.lock()) {
lockedSharedPtr->test();
}// 当sharedPtr离开作用域时,它指向的对象会被自动销毁
return 0;
}
这三种智能指针各有其用途,选择哪一种取决于你的具体需求。
扩展知识 #
1)智能指针方面的建议:
- 尽量使用智能指针,而非裸指针来管理内存,很多时候利用
RAII机制管理内存肯定更靠谱安全的多。 - 如果没有多个所有者共享对象的需求,建议优先使用
unique_ptr管理内存,它相对shared_ptr会更轻量一些。 - 在使用
shared_ptr时,一定要注意是否有循环引用的问题,因为这会导致内存泄漏。 shared_ptr的引用计数是安全的,但是里面的对象不是线程安全的,这点要区别开。
2)为什么 std::unique_ptr 可以做到不可复制,只可移动?
因为把拷贝构造函数和赋值运算符标记为了 delete,见源码:
template <typename _Tp, typename _Tp_Deleter = default_delete<_Tp> >
class unique_ptr {
// Disable copy from lvalue.
unique_ptr(const unique_ptr&) = delete;
template<typename _Up, typename _Up_Deleter>
unique_ptr(const unique_ptr<_Up, _Up_Deleter>&) = delete;
unique_ptr& operator=(const unique_ptr&) = delete;
template<typename _Up, typename _Up_Deleter>
unique_ptr& operator=(const unique_ptr<_Up, _Up_Deleter>&) = delete;
};
3)shared_ptr 的原理:
每个 std::shared_ptr 对象包含两个成员变量:一个指向被管理对象的原始指针,一个指向引用计数块的指针(control block pointer)。
引用计数块是一个单独的内存块,引用计数块允许多个 std::shared_ptr 对象共享相同的引用计数,从而实现共享所有权。
当创建一个新的 std::shared_ptr 时,引用计数初始化为 1,表示对象当前被一个 shared_ptr 管理。
- 拷贝 std::shared_ptr:当用一个 shared_ptr 拷贝出另一个 shared_ptr 时,需要拷贝两个成员变量(被管理对象的原始指针和引用计数块的指针),并同时将引用计数值加 1。这样,多个 shared_ptr 对象可以共享相同的引用计数。
- 析构 std::shared_ptr:当 shared_ptr 对象析构时,引用计数值减 1。然后检测引用计数是否为 0。如果引用计数为 0,说明没有其他 shared_ptr 对象指向该资源,因此需要同时删除原始对象(通过调用自定义删除器,如果有的话)。
4)智能指针的缺点
- 性能开销,需要额外的内存来存储他们的控制块,控制块包括引用计数,以及运行时的原子操作来增加或减少引用技术,这可能导致裸指针的性能下降。
- 循环引用问题,如果两个对象通过成员变量
shared_ptr相互引用,并且没有其他指针指向这两个对象中的任何一个,那么这两个对象的内存将永远不会被释放,导致内存泄露。
#include<iostream>
#include<memory>
class B; // 前向声明
class A {
public:
std::shared_ptr<B> b_ptr;
~A() {
std::cout << "A has been destroyed."<< std::endl;
}
};
class B {
public:
std::shared_ptr<A> a_ptr;
~B() {
std::cout << "B has been destroyed."<< std::endl;
}
};
int main() {
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->b_ptr = b; // A 引用 B
b->a_ptr = a; // B 引用 A
// 由于存在循环引用,A 和 B 的析构函数将不会被调用,从而导致内存泄漏
return 0;
}
- 不一定适用于所有场景:有一些容器类,内部实现依赖于裸指针,另外在考虑某些性能关键场景下,使用裸指针可能更合适。
🌟C++11 中有哪些常用的新特性? #
回答重点 #
C++11 新特性几乎是面试必问的一个话题,可以主要回答以下几个特性:
- auto 类型推导
- 智能指针
- RAII lock
- std::thread
- 左值右值
- std::function 和 lambda 表达式
auto 类型推导 #
auto 可以让编译器在编译时就推导出变量的类型,看代码:
auto a = 10; // 10是int型,可以自动推导出a是int
int i = 10;
auto b = i; // b是int型
auto d = 2.0; // d是double型
auto f = { // f是啥类型?直接用auto就行
return std::string("d");
}
利用 auto 可以通过=右边的类型推导出变量的类型。
什么时候使用 auto 呢?简单类型其实没必要使用 auto,某些复杂类型就有必要使用 auto,比如 lambda 表达式的类型,async 函数的类型等,例如:
auto func = [&] {
cout << "xxx";
}; // 对于func你难道不使用auto吗,反正我是不关心lambda表达式究竟是什么类型。
auto asyncfunc = std::async(std::launch::async, func);
智能指针 #
C++11 新特性中主要有两种智能指针 std::shared_ptr 和 std::unique_ptr。
那什么时候使用 std::shared_ptr,什么时候使用 std::unique_ptr 呢?
- 当所有权不明晰的情况,有可能多个对象共同管理同一块内存时,要使用
std::shared_ptr; - 而
std::unique_ptr强调的是独占,同一时刻只能有一个对象占用这块内存,不支持多个对象共同管理同一块内存。
两类智能指针使用方式类似,拿 std::unique_ptr 举例:
using namespace std;
struct A {
~A() {
cout << "A delete" << endl;
}
void Print() {
cout << "A" << endl;
}
};
int main() {
auto ptr = std::unique_ptr<A>(new A);
auto tptr = std::make_unique<A>(); // error, c++11还不行,需要c++14
std::unique_ptr<A> tem = ptr; // error, unique_ptr不允许移动,编译失败
ptr->Print();
return 0;
}
RAII lock #
C++11 提供了两种锁封装,通过 RAII 方式可动态的释放锁资源,防止编码失误导致始终持有锁。
这两种封装是 std::lock_guard 和 std::unique_lock,使用方式类似,看下面的代码:
#include <iostream>
#include <mutex>
#include <thread>
#include <chrono>
using namespace std;
std::mutex mutex_;
int main() {
auto func1 = [](int k) {
// std::lock_guard<std::mutex> lock(mutex_);
std::unique_lock<std::mutex> lock(mutex_);
for (int i = 0; i < k; ++i) {
cout << i << " ";
}
cout << endl;
};
std::thread threads[5];
for (int i = 0; i < 5; ++i) {
threads[i] = std::thread(func1, 200);
}
for (auto& th : threads) {
th.join();
}
return 0;
}
普通情况下建议使用 std::lock_guard,因为 std::lock_guard 更加轻量级,但如果用在条件变量的 wait 中环境中,必须使用 std::unique_lock。
std::thread #
什么是多线程这里就不过多介绍,新特性关于多线程最主要的就是 std::thread 的使用,它的使用也很简单,看代码:
#include <iostream>
#include <thread>
using namespace std;
int main() {
auto func = {
for (int i = 0; i < 10; ++i) {
cout << i << " ";
}
cout << endl;
};
std::thread t(func);
if (t.joinable()) {
t.detach();
}
auto func1 = [](int k) {
for (int i = 0; i < k; ++i) {
cout << i << " ";
}
cout << endl;
};
std::thread tt(func1, 20);
if (tt.joinable()) { // 检查线程可否被join
tt.join();
}
return 0;
}
这里记住,std::thread 在其对象生命周期结束时必须要调用 join() 或者 detach(),否则程序会 terminate(),这个问题在 C++20 中的 std::jthread 得到解决,但是 C++20 现在多数编译器还没有完全支持所有特性,先暂时了解下即可,项目中没必要着急使用。
左值右值 #
关于左值和右值,有两种方式理解:
概念 1:
左值:可以放到等号左边的东西叫左值。
右值:不可以放到等号左边的东西就叫右值。
概念 2:
左值:可以取地址并且有名字的东西就是左值。
右值:不能取地址的没有名字的东西就是右值。
std::function 和 lambda 表达式 #
这两个可以说是很常用的特性,使用它们会让函数的调用相当方便。使用 std::function 可以完全替代以前那种繁琐的函数指针形式。
还可以结合 std::bind 一起使用,直接看一段示例代码:
std::function<void(int)> f; // 这里表示function的对象f的参数是int,返回值是void
#include <functional>
#include <iostream>
struct Foo {
Foo(int num) : num_(num) {}
void print_add(int i) const { std::cout << num_ + i << '\n'; }
int num_;
};
void print_num(int i) { std::cout << i << '\n'; }
struct PrintNum {
void operator()(int i) const { std::cout << i << '\n'; }
};
int main() {
// 存储自由函数
std::function<void(int)> f_display = print_num;
f_display(-9);
// 存储 lambda
std::function<void()> f_display_42 = { print_num(42); };
f_display_42();
// 存储到 std::bind 调用的结果
std::function<void()> f_display_31337 = std::bind(print_num, 31337);
f_display_31337();
// 存储到成员函数的调用
std::function<void(const Foo&, int)> f_add_display = &Foo::print_add;const Foo foo(314159);
f_add_display(foo, 1);
f_add_display(314159, 1);
// 存储到数据成员访问器的调用
std::function<int>(Foo const&)> f_num = &Foo::num_;std::cout << "num_: " << f_num(foo) << '\n';
// 存储到成员函数及对象的调用
using std::placeholders::_1;std::function<void(int)> f_add_display2 = std::bind(&Foo::print_add, foo, _1);
f_add_display2(2);
// 存储到成员函数和对象指针的调用
std::function<void(int)> f_add_display3 = std::bind(&Foo::print_add, &foo, _1);
f_add_display3(3);
// 存储到函数对象的调用
std::function<void(int)> f_display_obj = PrintNum();
f_display_obj(18);
}
从上面可以看到 std::function 的使用方法,当给 std::function 填入合适的参数表和返回值后,它就变成了可以容纳所有这一类调用方式的函数封装器。std::function 还可以用作回调函数,或者在 C++ 里如果需要使用回调那就一定要使用 std::function,特别方便。
lambda 表达式可以说是 C++11 引入的最重要的特性之一,它定义了一个匿名函数,可以捕获一定范围的变量在函数内部使用,一般有如下语法形式:
auto func = [capture] (params) opt -> ret { func_body; };
其中 func 是可以当作 lambda 表达式的名字,作为一个函数使用,capture 是捕获列表,params 是参数表,opt 是函数选项(mutable 之类), ret 是返回值类型,func_body 是函数体。
看下面这段使用 lambda 表达式的示例:
auto func1 = [](int a) -> int { return a + 1; };
auto func2 = [](int a) { return a + 2; };
cout << func1(1) << " " << func2(2) << endl;
std::function 和 std::bind 使得我们平时编程过程中封装函数更加的方便,而 lambda 表达式将这种方便发挥到了极致,可以在需要的时间就地定义匿名函数,不再需要定义类或者函数等,在自定义 STL 规则时候也非常方便,让代码更简洁,更灵活,提高开发效率。
扩展知识 #
std::chrono #
chrono 很强大,平时的打印函数耗时,休眠某段时间等,都可使用 chrono。
在 C++11 中引入了 duration、time_point 和 clocks,在 C++20 中还进一步支持了日期和时区。这里简要介绍下 C++11 中的这几个新特性。
duration
std::chrono::duration 表示一段时间,常见的单位有 s、ms 等,示例代码:
// 拿休眠一段时间举例,这里表示休眠100ms
std::this_thread::sleep_for(std::chrono::milliseconds(100));
sleep_for 里面其实就是 std::chrono::duration,表示一段时间,实际是这样:
typedef duration<int64_t, milli> milliseconds;
typedef duration<int64_tseconds;
duration 具体模板如下:
template <class Rep, class Period = ratio<1> > class duration;
Rep 表示一种数值类型,用来表示 Period 的数量,比如 int、float、double,Period 是 ratio 类型,用来表示【用秒表示的时间单位】比如 second,常用的 duration 已经定义好了,在 std::chrono::duration 下:
- ratio<3600, 1>:hours
- ratio<60, 1>:minutes
- ratio<1, 1>:seconds
- ratio<1, 1000>:microseconds
- ratio<1, 1000000>:microseconds
- ratio<1, 1000000000>:nanosecons
ratio 的具体模板如下:
template <intmax_t N, intmax_t D = 1class ratio;
N 代表分子,D 代表分母,所以 ratio 表示一个分数,我们可以自定义 Period,比如 ratio<2, 1> 表示单位时间是 2 秒。
time_point
表示一个具体时间点,如 2020 年 5 月 10 日 10 点 10 分 10 秒,拿获取当前时间举例:
std::chrono::time_point<std::chrono::high_resolution_clock> Now() {return std::chrono::high_resolution_clock::now();
}
// std::chrono::high_resolution_clock为高精度时钟,下面会提到
clocks
时钟,chrono 里面提供了三种时钟:
1)steady_clock
稳定的时间间隔,表示相对时间,相对于系统开机启动的时间,无论系统时间如何被更改,后一次调用 now()肯定比前一次调用 now()的数值大,可用于计时。
2)system_clock
表示当前的系统时钟,可以用于获取当前时间:
int main() {
using std::chrono::system_clock;
system_clock::time_point today = system_clock::now();
std::time_t tt = system_clock::to_time_t(today);
std::cout << "today is: " << ctime(&tt);
return 0;
}
// today is: Sun May 10 09:48:36 2020
3)high_resolution_clock
high_resolution_clock 表示系统可用的最高精度的时钟,实际上就是 system_clock 或者 steady_clock 其中一种的定义,官方没有说明具体是哪个,不同系统可能不一样,之前看 gcc chrono 源码中 high_resolution_clock 是 steady_clock 的 typedef。
条件变量 #
条件变量是 C++11 引入的一种同步机制,它可以阻塞一个线程或多个线程,直到有线程通知或者超时才会唤醒正在阻塞的线程,条件变量需要和锁配合使用,这里的锁就是上面介绍的 std::unique_lock。
这里使用条件变量实现一个 CountDownLatch:
class CountDownLatch {
public:
explicit CountDownLatch(uint32_t count) : count_(count);
void CountDown() {
std::unique_lock<std::mutex> lock(mutex_);
--count_;
if (count_ == 0) {
cv_.notify_all();
}
}
void Await(uint32_t time_ms = 0) {std::unique_lock<std::mutex> lock(mutex_);while (count_ > 0) {if (time_ms > 0) {
cv_.wait_for(lock, std::chrono::milliseconds(time_ms));
} else {
cv_.wait(lock);
}
}
}
uint32_t GetCount() const {
std::unique_lock<std::mutex> lock(mutex_);
return count_;
}
private:
std::condition_variable cv_;
mutable std::mutex mutex_;
uint32_t count_ = 0;
};
🌟C++ 中 inline 的作用?它有什么优缺点? #
回答重点 #
inline 的作用是建议编译器将函数调用替换为函数体,以减少函数调用的开销,和宏比较类似。
使用 inline 函数的目的一定是希望可以提高程序的运行效率,特别是那些频繁调用的小函数。
优点:
- 降低函数调用的开销,原理就是因为省去了调用和返回的指令开销。
- 如果函数体较小,可以提高代码执行的效率。
缺点:
- 容易导致代码膨胀,整个可执行程序体积变大,特别是当
inline函数体较大且被多次调用时。 - 内联是一种建议,编译器可以选择忽略
inline关键字。
扩展知识 #
下面深入了解下 inline 函数。
内联函数的典型应用场景:
- 内联函数不仅适用于短小的函数,例如简单的 getter 和 setter,它还适合一些占用时间较短的算法,很多算法都会在语言层面考虑内联来提升性能。
- 需要频繁调用而且内联能显著提高性能的地方。
内联函数与宏的区别:宏是在预处理阶段进行文本替换,而内联函数是在编译阶段展开。内联函数有类型安全和作用域控制,宏没有这一特性。内联函数可以更好地报告调试信息,相对来说调试比较方便。
在优化级别较高时,即使未加
inline关键字,编译器也可能自动将频繁调用的小函数设为内联。inline的作用不仅仅是优先内联,它逐渐演变成了允许多重定义的含义。
C++ 中 explicit 的作用? #
回答重点 #
关键字 explicit 的主要作用是防止构造函数或转换函数在不合适的情况下被隐式调用。
例如,如果有一个只有一个参数的构造函数,加上 explicit 关键字后,编译器就不会自动用该构造函数进行隐式转换。这可以避免由于意外的隐式转换导致的难以调试的行为。
class Foo {
public:
explicit Foo(int x) : value(x) {}
private:
int value;
};
void func(Foo f) {
// ...
}
int main() {
Foo foo = 10; // 错误,必须使用 Foo foo(10) 或 Foo foo = Foo(10)
func(10); // 错误,必须使用 func(Foo(10))
}
如果没有 explicit 关键字,Foo foo = 10; 以及 func(10); 这样的代码是可以通过编译的,这会导致一些意想不到的隐式转换。
扩展知识 #
1)历史背景
explicit 关键字在 C++98 标准中引入,用来增强类型安全,防止不经意的隐式转换。从 C++11 开始,explicit 可以用于 conversion operator。
2)使用场景
- 防止单参数构造函数隐式转换
- 如果一个类的构造函数接受一个参数,而你并不希望通过隐式转换来创建这个类的实例,就应该在构造函数前加
explicit。这也是它最主要的作用。
class Bar {
public:
explicit Bar(int x) : value(x) {}
private:
int value;
};
Bar bar = 10; // 错误,无法隐式转换
- 防止 conversion operator 隐式转换
- 类中有时会定义一些转换操作符,但有些转换是需要显式调用的,这时也可以使用
explicit。
class Double {
public:
explicit operator int() const {
return static_cast<int>(value);
}
private:
double value;
};
Double d;
int i = d; // 错误,无法隐式转换
int j = static_cast<int>(d); // 正确,显式转换
3)复杂构造函数
对于那些带有默认参数的复杂构造函数,explicit 尤其重要,它们可能会被意外地调用。
class Widget {
public:explicit Widget(int x = 0, bool flag = true) : value(x), flag(flag) {}
private:int value;bool flag;
};
这种情况下,如果不加 explicit,没有任何参数传递给构造函数也可能会进行隐式转换,引发难以察觉的错误。
🌟C++ 中野指针和悬挂指针的区别? #
回答重点 #
两者都可能导致程序产生不可预测的行为。但它们有明显的区别:
1)野指针:一种未被初始化的指针,通常会指向一个随机的内存地址。这个地址不可控,使用它可能会导致程序崩溃或数据损坏。
int *p;
std::cout<< *p << std::endl;
2)悬挂指针:一个原本合法的指针,但指向的内存已被释放或重新分配。当访问此指针指向的内存时,会导致未定义行为,因为那块内存数据可能已经不是期望的数据了。
int main(void) {
int * p = nullptr;
int* p2 = new int;
p = p2;
delete p2;
}
扩展知识 #
展开说一说,弄清楚这两个概念不难,但如何避免和处理它们才是关键,这直接关系到写出更健壮的代码。
1)如何避免野指针
- 初始化指针:在声明一个指针时,立即赋予它一个明确的数值,可以是一个有效的地址,也可以是 nullptr。
int *ptr = nullptr; // 初始化
- 使用智能指针:C++ 中的智能指针(如
std::unique_ptr和std::shared_ptr)可以帮助自动管理指针的生命周期,减少手动管理的错误。
std::unique_ptr<int> ptr(new int(10));
2)如何避免悬挂指针
- 在删除对象后,将指针设置为 nullptr,确保指针不再指向已经释放的内存。
delete ptr;
ptr = nullptr;
- 尽量使用智能指针,它们会自动处理指针的生命周期,减少悬挂指针的产生。
std::shared_ptr<int> ptr1 = std::make_shared<int>(10);
{
std::shared_ptr<int> ptr2 = ptr1;
// 当 ptr2 离开作用域后,资源仍然被 ptr1 管理
}
// 仍然可以使用 ptr1
3)检测工具
- 静态分析工具(如 Clang-Tidy、cppcheck)和动态分析工具(Valgrind、AddressSanitizer)可以帮助检测这些错误,确保代码质量。
🌟 什么是内存对齐?为什么要内存对齐? #
回答重点 #
内存对齐是指计算机在访问内存时,会根据一些规则来为数据指定一个合适的起始地址。
计算机的内存是以字节为基本单位进行编址,但是不同类型的数据所占据的内存空间大小是不一样的,在 C++ 语言中可以用 sizeof()来获得对应数据类型的字节数,一些计算机硬件平台要求存储在内存中的变量按照自然边界对齐,也就是说必须使数据存储的起始地址可以整除数据实际占据内存的字节数,这叫做内存对齐。
通常,这些地址是固定数字的整数倍。这样做,可以提高 CPU 的访问效率,尤其是在读取和写入数据时。
为什么要内存对齐?主要有以下几个原因:
1)性能提升:对齐的数据操作可以让 CPU 在一次内存周期内更高效地读取和写入,减少内存访问次数。通过内存布局优化技术,可以提高程序的运行效率和可靠性,这是因为可以减少 CPU 访问内存的次数,提高计算机新能,计算机在每次访问内存的时候,每次读取到的一定长度,就是操作系统的默认对齐系数,或者其系数的整数倍。
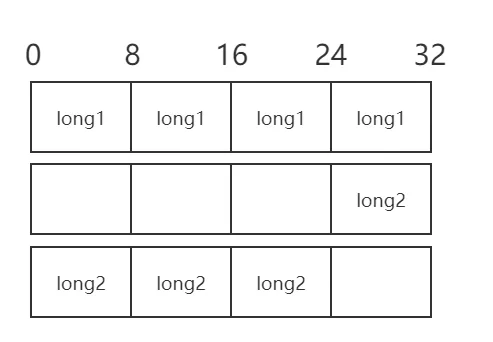
以 32 位 Intel CPU 为例(16 和 64 位类同),一次可以对一个 32 位的数进行运算,它的数据总线的宽度是 32 位,即 CPU 字长为 32 位。
假设 long1 和 long2 变量内存分配结构如下: long1,long2 类型都为 long,long1 在内存中的位置正好与内存字边界对齐,CPU 存取这个数只需访问内存 1 次,而 long2 在内存中跨越字边界,导致 CPU 存取这个数则需访问内存 2 次。由此可以看出,字节对齐主要提高 CPU 访问内存的效率。内存对齐之后,存取 long2 ,一次访问即可。
2)硬件限制:某些架构要求数据必须对齐,否则可能会引发硬件异常或需要额外的处理时间。有些 CPU 可以访问任意地址上的任意数据,而有些 CPU 只能在特定地址访问数据,因此不同硬件平台具有差异性,这样的代码就不具有移植性。
3)可移植性:代码在不同架构上运行时,遵从内存对齐规则可以减少潜在的问题。
扩展知识 #
内存对齐虽然看起来只是一个约定或者优化策略,其实背后还是有不少细致的讲究的:
1)对齐要求:不同的数据类型有不同的对齐要求。例如,在大多数 32 位系统中,int 通常要求 4 字节对齐,而 double 可能要求 8 字节对齐。编译器会根据这些对齐要求调整结构体或类的成员变量的布局。
2)填充字节:为了确保对齐,编译器有时会在数据成员之间插入一些“填充字节”(padding bytes),这些字节本身不保存有用的数据,只是为了使下一个成员变量满足对齐要求。例如,如果一个结构体的成员变量有 int 和 char,编译器可能会在 char 后面插入几个字节的填充,以确保下一个 int 的对齐。
3)控制内存对齐:在 C/C++ 中,我们可以使用编译器提供的关键字或扩展来控制数据的对齐方式,例如通过 #pragma pack 控制。
4)与缓存一致性相关:内存对齐有时候还与缓存一致性联系在一起。CPU 有自己的缓存系统,合理的内存对齐往往能使缓存更高效地工作,减少 cache miss 的概率。
结构体内存对齐 #
例子 1:假设 32 位系统,long 占 4 个字节。
struct AlignA
{
char a;
long b;
int c;
}
该结构体,占用内存为 4+ 4+ 4 =12 个字节,这就是内存对齐的原因。

例子 2
struct AlignB
{
int b;
char c[10];
double a;
}

成员变量布局调整 #
通过上面了解了结构体的内存对齐,是不是就可以想到,如果修改了结构体内变量的位置,就可以减少结构体的大小了。
C++ 中静态多态,动态多态是什么? #
静态多态也叫编译时多态,它是在编译阶段就确定要调用哪个函数。
实现方式主要有函数重载和模板,函数重载就是在一个类或者同一个作用域里有好几个同名函数,但它们的参数列表不同,编译器会根据你调用函数时传的实参类型和数量,在编译的时候就选好要调用哪个函数。
模板则是可以创建通用的函数或者类,根据不同的模板参数,编译器在编译时生成不同的代码,静态多态的优点是速度快,因为编译时就确定了调用,没有额外的运行时开销。
动态多态也叫运行时多态,它是在程序运行的时候才确定要调用哪个函数。主要通过虚函数和继承来实现。在基类里把函数声明成虚函数,派生类可以重写这个虚函数。
当用基类的指针或者引用去调用这个虚函数时,程序在运行时会根据指针或者引用实际指向的对象类型,来决定调用基类的函数还是派生类重写后的函数。动态多态的好处是灵活性高,能让代码更有扩展性,但因为要在运行时做判断,会有一些额外的开销。
打个比方,静态多态就像你出门前就根据天气决定穿什么衣服;动态多态就像你出门了,到地方才根据实际情况换衣服。
🌟C++ 中虚函数的原理? #
回答重点 #
虚函数是 C++ 中实现多态的一个关键机制。简单来说,虚函数允许你在基类里通过 virtual 声明一个函数,然后在派生类里对其进行重新定义。
通过使用虚函数,C++ 可以根据对象的实际类型(而不是引用或指针的静态类型)调用派生类的函数实现。实现虚函数的关键在于虚函数表(vtable)和虚函数表指针(vptr)。
每个含有虚函数的类都有一张虚函数表,表中存有该类的虚函数的地址。每个对象都有一个虚函数表指针,指向这个类的虚函数表。当调用虚函数时,程序会通过对象的虚函数表指针找到相应的虚函数地址,然后进行函数调用。
扩展知识 #
1)虚函数的实现原理:
- 虚函数表(vtable):是一个存储虚函数地址的数组。每个包含虚函数的类会有一个虚函数表。表里存有该类或者基类中重写虚函数的实际地址。
- 虚函数表指针(vptr):每个对象在内存布局中会有一个指向虚函数表的指针。编译器会自动管理这个指针的初始化和赋值。
2)多态的实现:
虚函数是实现多态的一种手段,允许程序在运行时决定调用哪个类的函数,实现动态绑定。当基类指针或引用指向派生类对象时,调用虚函数会根据实际对象类型选择合适的函数实现,下面是示例代码:
class Base {
public:virtual void show() {
cout << "Base class show" << endl;
}
};
class Derived : public Base {
public:
void show() override {
cout << "Derived class show" << endl;
}
};
// 用例
Base *b;
Derived d;
b = &d;
b->show(); // 将会调用 Derived 的 show 方法
3)注意点:
- 虚函数的调用比普通函数多了一个 vtable 查找过程,运行时略有开销。
- 析构函数如果需要在派生类中被正确的调用,应该声明为虚函数。
4)虚函数和纯虚函数:
- 如果类中包含纯虚函数,那么这个类就是一个抽象类,不能实例化,只能被继承。
class Abstract {
public:virtual void pure_virtual_func() = 0; // 纯虚函数
};
5)常见误区:
- 静态绑定的成员函数(static 关键字)不能是虚函数。
🌟C++ 中构造函数可以是虚函数吗? #
回答重点 #
构造函数不能是虚函数。
虚函数的机制依赖于虚函数表,而虚表对象的建立需要在调用构造函数之后才能完成。因为构造函数是用来初始化对象的,而在对象的初始化阶段虚表对象还没有被建立,如果构造函数是虚函数,就会导致对象初始化和多态机制的矛盾,因此,构造函数不能是虚函数。
扩展知识 #
1) 析构函数可以是虚函数
虽然构造函数不能是虚函数,但是析构函数应当是虚函数,特别是在基类中。这样做的目的是为了确保在删除一个指向派生类对象的基类指针时,能正确调用派生类对象的析构函数,从而避免资源泄露。
2) 其他特殊成员函数也不是虚函数
除了构造函数外,静态成员函数和友元函数也不能是虚函数。静态成员函数与类而不是与某个对象相关联,而友元函数则不属于类的成员函数,它们不具备多态性所需的对象上下文。
3) 解决方案
如果需要在对象创建时实现多态性,可以考虑工厂模式等设计模式来间接实现多态性。这些设计模式可以通过一些间接的手段,在对象创建过程中提供多态行为。
🌟C++ 中析构函数一定要是虚函数吗? #
回答重点 #
C++ 中析构函数并不一定要是虚函数,但在多态条件下,我是建议一定将其声明为虚函数。
如果一个类可能会被继承,并且你需要在删除指向派生类对象的基类指针时确保正确调用派生类的析构函数,那么基类的析构函数必须是虚函数。如果没有这样做,可能会导致资源泄漏或者未能正确释放派生类对象的资源。
扩展知识 #
1)虚函数的机制及其应用场景
当一个类的成员函数被声明为虚函数时,C++ 会为该类生成一个虚函数表,这个表存储指向虚函数的指针。在运行时,基于当前对象的实际类型,虚函数表指针用于动态绑定,调用正确的函数版本。
场景:假设有一个基类 Base 和一个派生类 Derived:
class Base {
public:
virtual ~Base() { std::cout << "Base destructor" << std::endl; }
};
class Derived : public Base {
public:
~Derived() { std::cout << "Derived destructor" << std::endl; }
};
如果基类的析构函数不是虚函数,那么以下代码可能会产生问题:
Base *obj = new Derived();
delete obj; // 只调用了 Base 的析构函数,可能导致内存泄漏或未释放资源
2)默认情况下析构函数的行为
如果基类的析构函数不是虚函数,当你通过基类指针删除派生类对象时,只会调用基类的析构函数,而不会调用派生类的析构函数。这种情况下,派生类中分配的资源可能不会及时释放,导致资源泄漏。
3)什么时候不需要虚析构函数
如果一个类不设计为基类,或者不会通过基类指针删除派生类对象,那么就不需要将析构函数声明为虚函数。
深入理解 #
首先我们先来理解一下什么是多态,多态性允许我们通过基类指针或引用来操作派生类对象。
这使得我们可以编写更通用、可扩展的代码,因为我们可以将派生类对象视为基类对象,并使用相同的接口处理它们。多态性主要通过虚函数实现。
将析构函数设计为虚函数主要是保证多态性,当我们使用基类指针或引用操作派生类对象时,如果基类的析构函数不是虚函数,此时则只会调用基类的析构函数,这样则有可能会导致未定义行为或者内存泄露。
但是当我们设置成虚函数时,并 override 之后,销毁派生类对象时,将自动调用相应的派生类析构函数,已实现派生类资源的释放。
#include<iostream>
class Base {
public:
Base() {
std::cout << "Base constructor"<< std::endl;
}
virtual ~Base() {
std::cout << "Base destructor"<< std::endl;
}
};
class Derived : public Base {
public:
Derived() {
std::cout << "Derived constructor"<< std::endl;
}
~Derived() {
std::cout << "Derived destructor"<< std::endl;
}
};
int main() {
Base* basePtr = new Derived(); // 使用基类指针操作派生类对象
delete basePtr; // 销毁对象时调用正确的派生类析构函数
return 0;
}
🌟 什么是 C++ 的函数重载?它的优点是什么?和重写有什么区别? #
回答重点 #
在 C++ 中,函数重载是指在同一个作用域内允许存在多个同名函数,它们的参数个数不同或者参数类型不同,注意函数的返回类型不同不能算作重载。
函数重载的优点是:
- 增强了代码的可读性。使用同名的函数,而不用为不同的功能选择完全不同的函数名,程序员可以更直观地理解代码。
- 改善了程序的可维护性。函数重载让我们可以定义一个通用接口,让同名函数实现不同的功能,减轻了函数命名的负担。
函数重载和函数重写(覆盖)的区别:
- 函数重载可以发生在同一个类中,而函数重写发生在继承关系的子类中。
- 函数重载要求参数列表必须不同,而函数重写要求方法签名(包括参数列表和返回类型)必须与父类方法一致。
- 函数重载在编译时决定调用哪个函数(静态绑定),而函数重写在运行时决定调用哪个函数(动态绑定)。
扩展知识 #
下面是函数重载的实例代码:
#include <iostream>
#include <string>
// 重载print函数以打印整数
void print(int i) {
std::cout << "Printing int: " << i << std::endl;
}
// 重载print函数以打印浮点数
void print(double f) {
std::cout << "Printing float: " << f << std::endl;
}
// 重载print函数以打印字符串
void print(const std::string& s) {
std::cout << "Printing string: " << s << std::endl;
}
// 重载print函数以打印字符
void print(char c) {
std::cout << "Printing char: " << c << std::endl;
}
int main() {
print(5); // 调用打印整数的print
print(500.263); // 调用打印浮点数的print
print("Hello"); // 调用打印字符串的print
print('A'); // 调用打印字符的print
return 0;
}
函数重载在实际应用中非常广泛,比如标准库中的 std::cout 就是很多重载的运算符 << 实现的,使我们可以打印不同类型的变量。而且,C++ STL(标准模板库)中的许多算法和容器类方法如 std::sort 和 std::vector 也采用了重载函数,以此来处理不同类型的输入。
除了函数重载和重写外,C++ 还支持运算符重载,允许对用户自定义的类型重载内置运算符,从而使自定义类型的使用和内置类型一样直观便捷。这个特性在实现复杂数据结构(如矩阵、复数等)时特别有用,使代码更易读、更自然。
🌟C++ 中 using 和 typedef 的区别? #
回答重点 #
using 在 C++11 中引入,using 和 typedef 都可以用来为已有的类型定义一个新的名称。最主要的区别在于,using 可以用来定义模板别名,而 typedef 不能。
1)typedef 主要用于给类型定义别名,但是它不能用于模板别名。
typedef unsigned long ulong;
typedef int (*FuncPtr)(double);
2)using 可以取代 typedef 的功能,语法相对简洁。
using ulong = unsigned long;
using FuncPtr = int (*)(double);
3)对于模板别名,using 显得非常强大且直观。
template<typename T>
using Vec = std::vector<T>;
总之,更推荐使用 using,尤其是当你处理模板时。
扩展知识 #
1)模板别名(Template Aliases):using 在处理模板时,如定义容器模板别名,非常方便。假如我们需要一个模板类 std::vector 的别名:
template<typename T>
using Vec = std::vector<T>;
Vec<int> vecInt; // 相当于 std::vector<int> vecInt;
2)作用范围:using 还可以用于命名空间引入,typedef 没有此功能。
namespace LongNamespaceName {
int value;
}
using LNN = LongNamespaceName;
LNN::value = 42; // 相当于 LongNamespaceName::value
3)可读性与调试:using 相对 typedef 更易读。
typedef void (*Func)(int, double);
using FuncAlias = void(*)(int, double);
在这个例子中,using 显然定义和解释都更加直观。
4)现代 C++ 代码规范:在 C++11 之后,许多代码规范建议优先使用 using 而不是 typedef。这证明了在实际应用和代码维护中,using 更具有优势。
🌟C++ 中 map 和 unordered_map 的区别?分别在什么场景下使用? #
回答重点 #
两者都是常用的关联容器。但有一些区别:
1)底层实现:
map:基于有序的红黑树(具体实现依赖于标准库)。unordered_map:基于哈希表。
2)时间复杂度:
map:插入、删除、查找的时间复杂度为 O(log n)。unordered_map:插入、删除、查找的时间复杂度为 O(1)(摊销)。
3)元素顺序:
map:元素按键值有序排列。unordered_map:元素无序排列。
4)内存使用:
map:由于底层是红黑树,内存使用较少。unordered_map:需要额外的空间存储哈希表,但在处理大量数据时,可能具有更好的表现。
场景选择 #
1)map:当需要按键值有序访问元素时,适合使用 map,例如按顺序遍历键值对。
2)unordered_map:当主要关注查找速度、不关心元素顺序时,使用 unordered_map 会更高效,例如需要高效的键值存储和快速查找的场景。
扩展知识 #
1)迭代器稳定性:在 map 中,由于基于红黑树,其迭代器在插入和删除元素时通常依然有效(除了指向被删除元素的迭代器),但 unordered_map 中,插入和删除操作可能会使所有迭代器失效。
2)复杂数据类型的键:如果键是复杂数据类型(需要自定义比较函数),可以在 map 中利用自定义键比较器的排序规则:
struct MyKey {
int id;
std::string name;
bool operator<(const MyKey& other) const {
return id < other.id; // 按id排序
}
};
std::map<MyKey, int>m;
3)哈希函数的定制:在 unordered_map 中,如果键类型是用户自定义类型,需要自行提供哈希函数和比较器:
struct MyKey {
int id;
std::string name;
};
struct HashFunction {
std::size_t operator()(const MyKey& k) const {
return std::hash<int>()(k.id) ^ std::hash<std::string>()(k.name);
}
};
struct KeyEqual {
bool operator()(const MyKey& lhs, const MyKey& rhs) const {
return lhs.id == rhs.id && lhs.name == rhs.name;
}
};
std::unordered_map<MyKey, int, HashFunction, KeyEqual> um;
什么是 C++ 中的 RAII?它的使用场景? #
回答重点 #
RAII,全称是 “Resource Acquisition Is Initialization”(资源获取即初始化)。
它的核心思想是将资源的获取与对象的生命周期绑定,通过构造函数获取资源(如内存、文件句柄、网络连接等),通过析构函数释放资源。这样,即使程序在执行过程中抛出异常或多路径返回,也能确保资源最终得到正确释放,特别是可以避免内存泄漏。
扩展知识 #
1)使用场景:
- 内存管理:标准库中的
std::unique_ptr和std::shared_ptr是 RAII 的经典实现,用于智能管理动态内存。 - 文件操作:
std::fstream类在打开文件时获取资源,在析构函数中关闭文件。 - 互斥锁:
std::lock_guard和std::unique_lock用于在多线程编程中自动管理互斥锁的锁定和释放。
2)示例代码:
#include <iostream>
#include <fstream>
class FileHandler {
public:
FileHandler(const std::string& filename) : file(filename) { // 资源获取
if (!file.is_open()) {
throw std::runtime_error("Unable to open file");
}
}
~FileHandler() {
file.close(); // 资源释放
}
void write(const std::string& data) {
if (file.is_open()) {
file << data << std::endl;
}
}
private:
std::ofstream file;
};
int main() {
try {
FileHandler fh("example.txt");
fh.write("Hello, RAII!");
} catch (const std::exception& e) {
std::cerr << e.what() << std::endl;
}return 0;
}
在这个示例中,FileHandler 类在构造函数中打开文件,在析构函数中关闭文件。即使 main 函数中发生异常或提前返回,析构函数也会自动调用,确保文件被正确关闭。
3)RAII 的好处:
- 异常安全:使用 RAII 能够确保在异常发生时自动释放资源,避免资源泄漏。
- 简化资源管理:将资源的获取和释放逻辑封装在类内,使代码更加简洁且方便维护。
4)与智能指针的结合:
std::unique_ptr<int> ptr(new int(5));
5)扩展应用:
- 锁管理:通过
std::lock_guard对锁进行管理,确保锁在作用范围内被正确释放。
std::mutex mtx;
{
std::lock_guard<std::mutex> lock(mtx);
// 临界区代码
} // mtx 在此处自动释放
C++ 的 function、bind、lambda 都在什么场景下会用到? #
回答重点 #
三者都用于处理函数和可调用对象:
1)std::function:用于存储和调用任意可调用对象(函数指针、Lambda、函数对象等)。常用场景包括回调函数、事件处理、作为函数参数和返回值。
2)std::bind:用于绑定函数参数,生成函数对象,特别是当函数参数不完全时。常见于将已有函数适配为接口要求的回调、将成员函数与对象绑定。
3)Lambda 表达式:用于定义匿名函数,通常在短期和局部使用函数时比如一次性回调函数、算法库中的自定义操作等。
扩展知识 #
std::function #
std::function 在 C++11 中引入,它是一个类模板,用于封装任何形式的可调用对象。使用 std::function 可以很方便地存储各种不同类型的函数,以便后面调用。
常见使用场景:
1)回调函数:在图形用户界面程序或网络编程中,经常需要定义回调函数。
2)事件处理:在观察者模式中,可以用 std::function 存储和调用事件处理函数。
3)作为函数参数和返回值:方便传递函数或存储函数以在其他地方调用。
示例:
#include <functional>
#include <iostream>
#include <vector>
void exampleFunction(int num) {
std::cout << "Number: " << num << std::endl;
}
int main() {
std::function<void(int)>
func = exampleFunction;func(42);
return 0;
}
std::bind #
std::bind 是一个函数模板,用于从一个可调用对象(如函数或成员函数)和其部分参数创建新的函数对象。这在处理不完全的函数参数或需要绑定特定对象的时候特别有用。
常见使用场景:
1)适配接口:当接口要求的函数签名与现有函数不匹配时,可以通过 std::bind 进行参数适配。
2)绑定成员函数:通过 std::bind 可以绑定类的成员函数与具体的实例对象,从而创建可以调用的对象。
示例:
#include <functional>
#include <iostream>
void exampleFunction(int a, int b) {
std::cout << "Sum: " << a + b << std::endl;
}
int main() {
auto boundFunction = std::bind(exampleFunction, 10, std::placeholders::_1);
boundFunction(32); // Output: Sum: 42
return 0;
}
Lambda 表达式 #
Lambda 表达式是一种匿名函数,它可以在定义的地方直接使用,通常用于简单的计算。如果某个函数逻辑仅在某个特定范围内有用,使用 Lambda 表达式可以使代码更简洁。
常见使用场景:
1)一次性回调函数:与算法和容器一起使用,以简化代码。
2)自定义操作:在标准库算法(如 std::for_each, std::transform 等)中,使用 Lambda 表达式进行自定义操作。
示例:
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
std::for_each(vec.begin(), vec.end(), [](int &n) { n *= 2; });
for (int n : vec) {
std::cout << n << " ";
}
std::cout << std::endl;
return 0;
}
🌟C++ 中堆内存和栈内存的区别? #
回答重点 #
堆内存和栈内存的区别主要体现在分配方式、管理方式、生命周期和性能等方面:
1)分配方式:
- 栈内存:由编译器在程序运行时自动分配和释放。典型的例子是局部变量的分配。
- 堆内存:需要程序员手动分配和释放,使用
new和delete操作符。在 C++11 之后,也可以使用智能指针来管理堆内存。
2)管理方式:
- 栈内存:由编译器自动管理,程序员无需担心内存泄漏,生命周期由作用域决定。
- 堆内存:由程序员手动管理,如果没有正确释放内存,会导致内存泄漏。
3)生命周期:
- 栈内存:变量在离开作用域之后自动销毁。
- 堆内存:只要不手动释放,内存会持续存在,直到程序终止。
4)性能:
- 栈内存:内存分配和释放速度极快,性能上优于堆内存。
- 堆内存:涉及到复杂的内存管理和分配机制,性能上较慢。
扩展知识 #
1)内存分配函数:
- 除了
new和delete,堆内存还可以使用malloc和free来管理。区别在于new会调用构造函数,而malloc只是纯粹的内存分配。
2)内存溢出和内存泄漏:
- 内存溢出:栈空间是有限的,如果递归过深或者分配的局部变量太大,可能导致栈溢出。
- 内存泄漏:堆内存如果没有正确释放,会导致内存泄漏,尤其在长时间运行的程序中,会影响系统性能。
3)智能指针:
- C++11 引入了智能指针
std::unique_ptr和std::shared_ptr,可以自动管理堆内存,大大降低了内存泄漏的风险。
4)虚拟内存:
- 虚拟内存机制,使物理内存和逻辑内存独立,程序可以看到的是一个巨大的连续地址空间,但实际上可能是分散的物理内存和硬盘上的交换空间。
5)栈与堆的容量:
- 栈的容量往往较小,通常为几 MB,主要用于局部变量和函数调用管理。
- 堆的容量通常较大,依赖于系统可用内存,适合动态分配大量内存。
C++ 堆内存与栈内存对比表 #
什么是 C++ 的回调函数?为什么需要回调函数? #
回答重点 #
回调函数是一种通过函数指针或者函数对象(例如 std::function 或 lambda 表达式)将一个函数作为参数传递给另一个函数的机制。
实际上,就是把函数的调用权从一个地方转移到另一个地方,这个调用会在未来某个时刻进行,而不是立即执行。之所以称为“回调”,可以理解为某种倒叙执行:先安排好函数的调用,不立即执行,等到合适的时机再“回头”执行。
需要回调函数的主要原因包括:
1)异步编程:在异步操作中,比如网络请求、文件读取、事件处理等,可以在操作完成后调用回调函数,而主程序可以继续执行其它任务,避免等待操作完成。
2)解耦代码:回调函数有助于将代码模块化和解耦,允许我们创建更灵活和可复用的代码。例如,一个通用的排序算法可以接受一个比较函数,允许用户自定义排序逻辑。
3)事件驱动编程:在 GUI 或者其他事件驱动程序中,回调函数经常用于处理用户输入事件,如点击、鼠标移动、键盘输入等。
扩展知识 #
回调函数的实际应用:
1)使用函数指针作为回调函数:
在 C 风格接口中,最常见的回调函数形式就是使用函数指针。例如:
#include <iostream>
// 定义一个函数指针类型
typedef void (*CallbackFunc)(int);
void RegisterCallback(CallbackFunc cb) {
// 模拟某些操作
std::cout << "Registering callback...\n";
cb(42); // 调用回调函数
}
void MyCallback(int value) {
std::cout << "Callback called with value: " << value << std::endl;
}
int main() {
RegisterCallback(MyCallback); // 传递回调函数
return 0;
}
2)使用 C++11 之后的 std::function 和 lambda 表达式:
#include <iostream>
#include <functional>
void RegisterCallback(
std::function<void(int)> cb) {
std::cout << "Registering callback...\n";
cb(42); // 调用回调函数
}
int main() {
auto myCallback = [](int value) {
std::cout << "Callback called with value: " << value << std::endl;
};
RegisterCallback(myCallback); // 传递 lambda 回调函数
return 0;
}
3)GUI 编程中的回调:
在图形用户界面编程中,回调函数常用于处理用户事件。例如,在一个按钮点击事件中调用用户提供的回调函数。
例如,使用一个假设的 GUI 库:
class Button {
public:
void setOnClick(std::function<void()> cb) {
onClick = cb;
}
void simulateClick() {
if (onClick) {
onClick();
}
}
private:
std::function<void()> onClick;
};
int main() {
Button button;
button.setOnClick([]() {
std::cout << "Button clicked!" << std::endl;
});
button.simulateClick(); // 模拟一次点击事件
return 0;
}
🌟C++ 中为什么要使用 nullptr 而不是 NULL? #
回答重点 #
主要原因是 nullptr 有明确的类型,它是 std::nullptr_t 类型,可以避免代码中出现类型不一致的问题。
扩展知识 #
1)类型安全:NULL 通常被定义为数字 0(在 C++ 代码中一般是 #define NULL 0),它实际上是整型值。这就可能会带来类型不一致的问题,比如传递参数时,编译器无法准确判断是整数 0 还是空指针。而 nullptr 则是 std::nullptr_t 类型的,能够明确表示空指针,使编译器更容易理解代码。
2)代码可读性:使用 nullptr 使得代码更具有可读性和可维护性。它明确传达了变量是用作指针而非整数值,例如:
void process(int x) {
std::cout << "Integer: " << x << std::endl;
}
void process(voidptr) {
std::cout << "Pointer: " << ptr << std::endl;
}
int main() {
process(NULL); // int 还是指针?
process(nullptr); // 指针
return 0;
}
在上面的代码中,可以看出 nullptr 能让编译器和程序员清楚地知道调用哪个函数。
3)避免潜在的错误:在函数重载和模板中使用 NULL 可能导致编译器选择错误的重载版本。另外,模板编程中特别是涉及类型推断时,NULL 会带来一些不期望的效果。
template<typename T>
void foo(T x) {
std::cout << typeid(x).name() << std::endl;
}
int main() {
foo(0); // 0 是int型
foo(NULL); // 你希望是int还是指针呢
foo(nullptr); // std::nullptr_t
return 0;
}
在上面的代码中,使用 nullptr 可以让我们精确控制模板的类型。
C++ 中 nullptr 与 NULL 对比表
#
🌟C++ 中什么是深拷贝?什么是浅拷贝? #
回答重点 #
1)浅拷贝:浅拷贝只是简单地复制对象的值,而不复制对象所拥有的资源或内存。也就是说,两个对象共享同一个资源或内存。当一个对象修改了该资源或内存,另一个对象也会受到影响。这种情况通常发生在默认的拷贝构造函数或赋值操作中。
2)深拷贝:深拷贝不仅复制对象的值,还会新分配内存并复制对象所拥有的资源。这样两个对象之间就不会共享同一个资源或内存,修改其中一个对象的资源或内存不会影响到另一个对象。
C++ 中友元类和友元函数有什么作用? #
回答重点 #
两者主要用于提供访问私有成员和保护成员的权限。
友元关系是一种单向的访问权限,并不会破坏封装性,同时也不会牵涉到类之间的继承关系。友元的使用在以下情况下特别有用:
1) 友元函数:允许一个函数访问某个类的私有成员和保护成员。
class MyClass {
private:
int privateMember;
public:
MyClass() : privateMember(0) {}
//声明友元函数friend void
friendFunction(MyClass &obj);
};
void friendFunction(MyClass &obj) {
//访问 privateMember
obj.privateMember = 10;
}
2) 友元类:允许另一个类访问某个类的私有成员和保护成员。
class B; //前向声明
class A {
private:
int privateMember;
public:
A() : privateMember(0) {}
//声明B为友元类
friend class B;
};
class B {
public:
void accessA(A &obj) {
//访问 A 的 privateMember
obj.privateMember = 20;
}
};
扩展知识 #
下面进一步讨论下它们的作用场景和设计考量:
1) 封装与开放:
- 封装是面向对象编程的基本原则之一,它将数据和操作数据的方法绑定到一起,防止外部代码直接访问对象的内部状态。友元的引入让类在需要的时候能够部分地开放它的内部状态,通常不会滥用。
- 友元函数和友元类提供了一种在不破坏封装性的条件下,安全访问私有成员的方式。
2) 友元的替代方案:
- 如果友元机制的使用本质上意味着违反封装性或设计初衷,那么可能需要重新考量类的设计。
- 你可以选择通过公开接口提供访问权限(如 getter/setter 方法),或利用继承、多态等其他 OOP 特性来实现同样的目的。
3) 访问控制复杂度:
- 使用友元可能会增加代码的复杂度,因为它打破了类的封装性,代码的维护变得相对困难。所以,在维护代码时,需要非常小心,确保友元使用的合理性和必要性。
友元是一种方便但需要慎用的工具,合理使用能够简化代码,但滥用则会破坏类的封装性,增加代码维护的难度。建议在实际编程中能够权衡利弊,合理利用这一机制。
C++ 如何调用 C 语言的库? #
回答重点 #
可以使用 extern "C" 来告诉编译器按照 C 语言的链接方式处理某些代码:
1)在 C++ 代码中包含 C 语言头文件时,用 extern "C" 进行声明,比如:
extern "C" {
#include "your_c_library.h"
}
2)需要在链接阶段确保 C++ 项目和 C 语言库都被正确链接。可通过编写合适的 CMakeLists.txt 或 Makefile 来实现。
3)也可以不使用 extern “C”,源文件后缀名改为.c 也行。
扩展知识 #
说到 extern "C",得从 C 和 C++ 的兼容性说起。C++ 是 C 的增强版本,但它们的编译方式还是有些差异的。C++ 支持函数的重载,而 C 语言不支持。C++ 编译器会对函数进行“名字修饰”(Name Mangling)。
extern "C" 的作用是让编译器按 C 方式编译,避免函数名被修饰,保证 C 语言库里的函数能被正确调用。
举个例子:
假设有一个简单的 C 库 math_library.c:
// math_library.c
int add(int a, int b) {
return a + b;
}
你先编写一个头文件 math_library.h:
// math_library.h
#ifndef MATH_LIBRARY_H
#define MATH_LIBRARY_H
int add(int a, int b);
#endif
然后在你的 C++ 项目中这么用:
// main.cpp
#include <iostream>
extern "C" {
#include "math_library.h"
}
int main() {
int result = add(3, 4);
std::cout << "Result: " << result << std::endl;
return 0;
}
最后,确保编译和链接。可以使用以下命令:
g++ -o main main.cpp math_library.c
另外,有几点需要注意:
1)如果你的 C 库里有 C++ 不支持的特性,比如变量长度数组(VLA),需要仔细考虑兼容性。
2)如果 C 库包含了结构体,尤其是那些带有复杂数据类型或指针的结构体,要确保它们在 C++ 中能够正确处理。
3)最好是 C 和 C++ 不要混用,如果要混用,建议做一个封装层,对 C 做一层 C++ 的封装,然后上层的业务代码还是统一使用 C++。
指针和引用的区别 #
回答重点 #
- 引用必须在声明时初始化,指针可以不需要初始化
// 引用示例
int a = 10;
int& ref_a = a; // 引用初始化
// int& ref_b; // 错误:引用必须在声明时初始化
// 指针示例
int b = 20;
int* ptr_b = &b; // 指针初始化
int* ptr_c = nullptr; // 指针可以为空
- 指针是一个变量,存储的是一个地址,引用跟原来的变量实质上是同一个东西,是原变量的别名,引用本身并不存储地址,而是在底层通过指针来实现对原变量的访问
- 引用被创建之后,就不可以进行更改,指针可以更改
#include<iostream>
int main() {
int a = 10;
int b = 20;
// 引用
int& ref_a = a; // ref_a 是 a 的引用
// ref_a = b; // 错误:引用不能被重新绑定
// 指针
int* ptr_a = &a; // ptr_a 是一个指针,指向 a
ptr_a = &b; // 指针可以被重新赋值,现在指向 b
std::cout << "a: " << a << ", b: " << b << std::endl;
// 如果取消注释 ref_a = b; 这行代码,将会导致编译错误
// 输出 "a: 10, b: 20",因为引用不能被重新绑定
*ptr_a = 30; // 通过指针修改 b 的值
std::cout << "a: " << a << ", b: " << b << std::endl; // 输出 "a: 10, b: 30"
return 0;
}
- 不存在指向空值的引用,必须有具体实体;但是存在指向空值的指针。
public 继承、protected 继承、private 继承的区别 #
回答重点 #
重点说明三种继承方式的区别:
什么是静态数据成员和静态成员函数? #
在 C++ 里,静态数据成员和静态成员函数是类的特殊成员,下面分别介绍它们:
静态数据成员 #
静态数据成员是用 static 关键字修饰的类的数据成员。它不属于类的某个具体对象,而是被类的所有对象共享,在内存中只有一份拷贝。
所有对象都能访问和修改同一个静态数据成员,可用于记录类相关的公共信息。
必须在类外进行初始化,且初始化时不使用 static 关键字。
#include <iostream>
class MyClass {
public:
static int staticData; // 声明静态数据成员
};
// 在类外初始化静态数据成员
int MyClass::staticData = 10;
int main() {
MyClass obj1, obj2;
std::cout << "obj1的静态数据成员值: " << obj1.staticData << std::endl;
std::cout << "obj2的静态数据成员值: " << obj2.staticData << std::endl;
// 修改静态数据成员的值
obj1.staticData = 20;
std::cout << "修改后obj2的静态数据成员值: " << obj2.staticData << std::endl;
return 0;
}
在这个例子中,staticData 是 MyClass 类的静态数据成员,obj1 和 obj2 共享这一成员,修改 obj1 的 staticData 后,obj2 的 staticData 也会改变。
静态成员函数 #
静态成员函数是用 static 关键字修饰的类的成员函数,它不依赖于类的具体对象,可直接通过类名调用。
没有 this 指针,因为它不与特定对象关联,不能访问非静态数据成员和非静态成员函数。
主要用于处理类的静态数据成员,提供与类相关的通用功能。
#include <iostream>
class MyClass {
private:
static int staticData;
public:
static void setStaticData(int value) {
staticData = value;
}
static int getStaticData() {
return staticData;
}
};
// 在类外初始化静态数据成员
int MyClass::staticData = 0;
int main() {
// 直接通过类名调用静态成员函数
MyClass::setStaticData(30);
std::cout << "静态数据成员的值: " << MyClass::getStaticData() << std::endl;
return 0;
}
静态成员变量为什么要在类外初始化? #
回答重点 #
存储空间分配:
- 因为静态变量不属于任何特定对象,而是类的共享成员,需要在全局范围内分配存储空间。静态变量的存储空间在程序启动时分配,生命周期贯穿整个程序运行。类内声明仅告知编译器该变量的存在,而类外定义则实际分配内存。
避免重复定义:
- 如果在类内初始化静态变量,可能会导致多个编译单元中包含该变量的定义,导致链接错误。类外定义确保静态变量只在一个编译单元中定义,避免重复。
扩展知识 #
静态成员函数:
- 静态成员函数只能访问静态成员变量,不能访问非静态成员变量,因为它们没有
this指针。
- 静态成员函数只能访问静态成员变量,不能访问非静态成员变量,因为它们没有
静态常量成员:
- 静态常量成员(如
static const int)可以在类内直接初始化,因为它们在编译时已知,并且不需要额外的存储空间。
- 静态常量成员(如
内联静态成员:
- C++17 引入了内联静态成员,可以在类内直接初始化静态变量,编译器会自动处理存储和链接问题。
class MyClass {
public:
static int staticVar; // 类内声明
static const int staticConstVar = 10; // 静态常量整型成员,类内初始化
};
int MyClass::staticVar = 0; // 类外定义和初始化
int main() {
MyClass::staticVar = 5; // 访问静态变量
return 0;
}
C++ 进阶篇 #
🌟C++ 动态库和静态库的区别? #
回答重点 #
动态库(也称为共享库)和静态库是常用的两种库形式,它们有以下主要区别:
1)动态库在运行时加载,提供共享的库文件,如 .dll(Windows)或 .so(Linux),而静态库在编译时被直接合并到可执行文件中,通常是 .lib(Windows)或 .a(Linux)。
2)动态库在内存中可以被多个程序共享,因此节省了内存和磁盘空间,但会引入一些加载开销。对于静态库,每个使用它的程序都会有一份拷贝,二进制文件较大,但启动速度通常较快。
3)重点:动态库可以在库升级时无需重新编译依赖该库的程序,只需要更新库文件即可。而静态库由于依赖程序直接包含了库的代码,所以需要重新编译依赖程序进行更新。
4)在调试和部署方面,动态库更复杂,因为它们需要在运行时找到所需的库文件。如果库文件不存在或版本不匹配,程序可能无法正常运行。静态库则不会有这种问题,因为所有依赖都已经编译进了可执行文件。
扩展知识 #
除了上面提到的主要区别,动态库和静态库在开发过程中还有一些其他注意事项和优化技巧,可以进一步了解:
1)符号解析:静态链接在编译时就解析了符号,这意味着所有函数和变量的引用都在编译期解决,而动态链接在运行时解析符号,这会略微增加加载时间。
2)版本控制:动态库通常可以使用版本号来管理不同版本的库同时存在,例如在 Linux 系统中,库文件名中可以包含版本号,如 libxyz.so.1.2.3。这可以允许旧版程序继续使用旧版本的库,而新版程序使用新版本的库。
3)编译选项:在创建动态库时,通常需要使用如 -fPIC(Position Independent Code,位置无关代码)选项来生成可以在任意内存地址运行的代码。而静态库通常不需要考虑这一点,因为它们最终会被编译进可执行文件。
4)链接顺序:在链接静态库时,链接顺序可能会影响到最终的可执行文件,尤其是在处理有依赖关系的多个库时。动态库则相对宽松,因为它们的依赖关系可以在运行时解决。
5)打包和分发:动态库通常需要一并打包分发,确保目标系统中存在正确版本的库。常见的方法包括使用容器(如 Docker)或者打包系统(如 Windows 安装包及 Linux 的 .deb 和 rpm 包)。
🌟 介绍下 C++ 程序从编写到可执行的整个过程? #
回答重点 #
总共分 5 步:
1)编写代码:编写 C++ 源代码,保存为 .cpp 、.cc .h 文件。
2)预处理:预处理器根据源代码中的预处理指令(如 #include 替换、#define 替换等)对代码进行处理,生成纯净的源代码。
3)编译:编译器(如 g++ 或 clang++)将预处理后的源代码翻译成汇编代码。
4)汇编:汇编器(如 as)将汇编代码转换成机器码,生成目标文件(.o 文件)。
5)链接:链接器(如 ld)将多个目标文件和库文件链接在一起,生成最终的可执行文件。
扩展知识 #
下面深入理解各个步骤:
1)编写代码
开发者主要参与的就是这个步骤,通过 C++ 编写逻辑业务代码,这部分代码是高级语言编写的,人类易读易写。
2)预处理
预处理器主要做以下工作:
- 处理头文件:如
#include指令会替换为头文件内容。 - 宏替换:如
#define指令用相应的代码替换宏。 - 条件编译:根据条件指令(如
#ifdef、#ifndef等)决定是否编译部分代码。 - 去除注释:清理掉所有注释。
- 添加行号:添加行号和文件名标识,方便编译器产生警告和调试信息
预处理的输出仍是 C++ 代码,但没有了预处理指令。
3)编译
编译器将预处理后的代码转化为汇编代码,主要做以下工作:
- 词法分析:语法扫描,利用有限状态机的算法将源码中的字符串分割成一系列记号,如加减乘除数字括号等。
- 语法分析:检查代码语法,将源代码转为语法树。
- 语义分析:检查变量类型、函数调用是否合法等,比如浮点型整数赋值给指针,编译器就会报错。
- 优化:对中间代码进行优化,提高代码运行效率,比如 3+4=7。
- 生成汇编:根据优化后的中间代码生成汇编代码。
汇编代码是与硬件无关的低级代码。
4)汇编
汇编器将汇编代码转化为与目标机器相关的机器码,生成目标文件。每个 .cpp 源文件(模块)通常会生成一个对应的 .o 目标文件。这些文件包含机器指令以及一些符号表信息,用于后续链接。
5)链接
链接器将所有目标文件和所需的库文件链接起来,生成最终的可执行文件。主要做以下工作:
- 符号解析:找到所有外部符号(如函数、变量)在目标文件和库文件中的定义。
- 地址分配:将目标代码放置在内存中的适当位置。
- 重定位:调整程序内所有的地址引用,使它们指向正确的内存位置。
🌟 谈一谈你对面向对象的理解 #
回答重点 #
四大核心特性(3 + 1):
- 封装:将数据(属性)和操作数据的方法(函数)绑定到类中,通过访问控制(
public/private/protected)隐藏实现细节。可提高安全性(防止外部直接修改数据),简化接口使用。 - 继承:通过派生类(子类)复用基类(父类)的代码,来支持层次化设计。
- 多态:同一接口在不同上下文中表现出不同行为,分为编译时多态(函数重载、模板)和运行时多态(虚函数)。运行时多态主要是通过虚函数表和虚函数指针,实现动态绑定。
- 抽象:仅暴露必要接口,隐藏复杂实现细节。主要通过纯虚函数定义抽象类(接口)。
扩展知识 #
- 菱形继承:C++ 支持一个类继承多个基类,但需注意菱形继承问题(通过虚继承解决):
class A {};
class B : virtual public A {};
class C : virtual public A {};
class D : public B, public C {}; // 虚继承避免 A 的重复拷贝
- 虚函数与多态成本:虚函数通过虚函数表实现,会带来额外内存和间接调用开销,但提供了灵活的运行时多态。
🌟介绍下C++常用的容器以及特点? #
如下表:
🌟详细介绍C++中的constexpr
#
回答重点 #
constexpr是C++11引入的关键字,用于声明常量表达式,在编译时就能确定值的表达式,两个用途:
编译时计算:编译时就可以计算出表达式的值,提高运行时性能
常量表达式上下文:可用于哪些需要常量的表达式,比如数组大小、模板参数等。
扩展知识 #
1)constexpr变量:声明时必须初始化,且初始值必须是常量表达式。
constexpr int size = 10; // size 是编译时常量
int arr[size];
2)constexpr 函数:在编译期求值的函数,它的参数必须是常量表达式。
constexpr int factorial(int n) {
return n <= 1 ? 1 : n * factorial(n - 1);
}
constexpr int val = factorial(5); // val 在编译时计算为 120
3)constexpr 与 const 的区别:
const:运行时不可修改,但不保证编译时求值constexpr:编译时求值
🌟 请介绍 C++ 多态的实现原理? #
回答重点 #
整体流程如下:
回答多态的实现原理,主要可以围绕在 虚函数、虚函数表 和 虚函数表指针 方向上。
多态通过虚函数实现。通过虚函数,子类可以重写父类的方法,当通过基类指针或引用调用时,会根据对象的实际类型调用对应的函数实现。
而这更深层次的原理,是通过虚表(vtable)和虚表指针(vptr)机制实现的。虚表是一个函数指针数组,包含了该类所有虚函数的地址,而虚表指针存储在对象实例中,指向属于该对象的虚表。
扩展知识 #
可以从以下几个方面,更全面的了解多态:
1)虚函数和重写:在基类中使用关键字 virtual 声明虚函数后,在子类中可以重写这个函数。
class Base {
public:
virtual void show() {
std::cout << "Base show" << std::endl;
}
};
class Derived : public Base {
public:
void show() override {
std::cout << "Derived show" << std::endl;
}
};
2)虚表(vtable):每个包含虚函数的类都会有一个虚表(vtable),这个虚表在编译时生成。它包含了该类所有虚函数的指针。对于每个类(而不是每个对象),编译器会创建一个唯一的虚表。
3)虚表指针(vptr):每个包含虚函数的对象实例会有一个隐藏的虚表指针(vptr),它在对象创建时自动初始化,指向该类的虚表。不同类型的对象,其虚表指针会指向不同的虚表。例如,上述示例中,Base 和 Derived 对象的虚表指针分别指向它们各自的虚表。
实际如图所示:
4)多态的调用机制:当通过基类指针或引用调用虚函数时,程序会通过该指针或引用找到对应的对象,然后通过虚表指针找到正确的虚表中的函数地址,最终调用适当的函数实现,这样程序能够在运行时决定调用哪一个函数实现。
5)实际示例:
void demonstratePolymorphism(Base &obj) {
obj.show(); // 依赖于实际对象的类型
}
int main() {
Base b;
Derived d;
demonstratePolymorphism(b); // 输出 "Base show"
demonstratePolymorphism(d); // 输出 "Derived show"
return 0;
}
6)注意事项:
- 使用多态会有一定的内存和性能开销,因为每个类需要维护虚表,每个对象也需要存储虚表指针。
- 虚函数调用通常比普通函数调用更慢一点,因为多了一次指针间接寻址。
🌟 请介绍 C++ 中 unique_ptr 的原理? #
回答重点 #
unique_ptr 是 C++11 引入的智能指针,它利用 RAII 模式,自动管理动态分配的资源。主要特点是它的所有权是独占的,也就是说,在任意时刻,某块内存只能由一个 unique_ptr 实例拥有,这样可以确保资源不会被多次释放。
基本原理如下:
1)unique_ptr 一旦被创建,它会负责管理内存并在适当的时候释放资源。
2)unique_ptr 不允许复制,但可以通过 std::move 进行所有权转移,从而避免双重释放问题。
3)unique_ptr 采用 RAII 模式,即在对象的生命周期内自动管理资源的获取和释放。
它为什么可以做到独占?
可以直接看这段源码:
unique_ptr(const unique_ptr&) = delete;
template<typename _Up, typename _Up_Deleter>
unique_ptr(const unique_ptr<_Up, _Up_Deleter>&) = delete;
unique_ptr& operator=(const unique_ptr&) = delete;
template<typename _Up, typename _Up_Deleter>
unique_ptr& operator=(const unique_ptr<_Up, _Up_Deleter>&) = delete;
因为它禁用了拷贝构造函数。
扩展知识 #
进一步探讨 unique_ptr 的使用和内部机制。
1)创建 unique_ptr:
std::unique_ptr<int> ptr1(new int(10));
auto ptr2 = std::make_unique<int>(20);
2)所有权转移:使用 std::move 转移 unique_ptr 的所有权。
std::unique_ptr<int> ptr3 = std::move(ptr1);
3)不可复制:尝试复制 unique_ptr 会导致编译错误。
// std::unique_ptr<int> ptr4 = ptr3; // 编译错误
4)析构:当 unique_ptr 离开作用域时,其析构函数会自动调用 delete,释放内存。
void example() {std::unique_ptr<int> ptr(new int(30));// 离开作用域时, ptr 会自动释放内存
}
5)自定义删除器:可以为 unique_ptr 指定一个自定义删除器。
std::unique_ptr<FILE, decltype(&fclose)> file_ptr(fopen("file.txt", "r"), &fclose);
6)优化性能:通过使用 std::make_unique 减少内存分配和构造步骤,提高性能和安全性。
auto arr = std::make_unique<int[]>(5);
因为这些特性, unique_ptr 非常适合用来管理动态资源,防止常见的内存泄漏和其他资源管理问题。
而且,使用 unique_ptr 还可以使代码更加清晰简洁,减少手动资源管理的负担。
建议在 C++ 开发中,尽量避免使用裸指针,考虑使用智能指针完全替代裸指针。
🌟 请介绍 C++ 中 shared_ptr 的原理?shared_ptr 线程安全吗? #
回答重点 #
1)原理:shared_ptr 原理的回答重点在于 引用计数,它在底层实现上,通过维护一个引用计数,来管理内存对象的生命周期。
当新构造一个对象时,引用计数初始化为 1,拷贝对象时,引用计数加 1,对象作用域结束析构时,引用计数减 1,当最后一个对象被销毁时,引用计数会减为 0,所持有的资源会被释放。
2)线程安全性:shared_ptr 保证多个线程能够安全地增加或减少其引用计数。但是,如果多个线程同时读写同一个 shared_ptr 或者操作其管理的对象,那么需要额外进行同步机制,比如使用互斥锁(mutex)来保护这些操作。
也就是说,shared_ptr 的引用计数是线程安全的,但是它管理的对象是否线程安全,不归 shared_ptr 来管,取决于相关的对象是否有做同步处理。
扩展知识 #
1)引用计数机制:shared_ptr 内部通常会包含两部分指针:一是指向实际管理的资源,二是指向一个控制块(control block)。控制块中包含引用计数,当 shared_ptr 被拷贝时,引用计数增加;当 shared_ptr 被销毁时,引用计数减少;当引用计数变为零时,资源才会被释放。
2)线程安全:具体来说,shared_ptr 的引用计数操作是线程安全的。这是因为标准库对引用计数的增减操作进行了原子化处理。但是在其他场景下,比如多个线程同时修改 shared_ptr 对象自身,依然需要使用锁来保护。
3)循环引用问题:需要注意的是,shared_ptr 可能会导致循环引用(circular reference)的情况。比如 A 持有 B 的 shared_ptr,B 又持有 A 的 shared_ptr,这会导致引用计数永远不会为零,资源无法正确释放。解决这种问题,可以引入 weak_ptr。weak_ptr 只会弱引用资源,不会影响引用计数。
4)性能开销:由于每次创建或销毁 shared_ptr 都会涉及到控制块的分配和释放操作,所以在一些性能敏感的场景(比如频繁创建和销毁对象)下,需要估算好这些操作的开销,在智能指针的选择上面,可优先选择 unique_ptr,次之选择 shared_ptr。
5)手写一个 shared_ptr
#include <iostream>
#include <mutex>
// 引用计数控制块
template <typename T>
class ControlBlock {
public:
ControlBlock(T* ptr) : ptr_(ptr), ref_count_(1), weak_count_(0) {}
void add_ref() {
std::lock_guard<std::mutex> lock(mutex_);
++ref_count_;
}
void release_ref() {
bool should_delete = false;
{
std::lock_guard<std::mutex> lock(mutex_);
if (--ref_count_ == 0) {
should_delete = true;
if (weak_count_ == 0) {
delete ptr_;
ptr_ = nullptr;
}
}
}
if (should_delete && weak_count_ == 0) {
delete this;
}
}
void add_weak_ref() {
std::lock_guard<std::mutex> lock(mutex_);
++weak_count_;
}
void release_weak_ref() {
bool should_delete = false;
{
std::lock_guard<std::mutex> lock(mutex_);
if (--weak_count_ == 0 && ref_count_ == 0) {
should_delete = true;
}
}
if (should_delete) {
delete this;
}
}
T* get() const { return ptr_; }
int use_count() const { return ref_count_; }
private:
T* ptr_;
int ref_count_;
int weak_count_;
mutable std::mutex mutex_;
};
// shared_ptr 主类
template <typename T>
class SharedPtr {
public:
// 构造函数
SharedPtr() : ctrl_block_(nullptr) {}
explicit SharedPtr(T* ptr) : ctrl_block_(new ControlBlock<T>(ptr)) {}
// 拷贝构造函数
SharedPtr(const SharedPtr& other) : ctrl_block_(other.ctrl_block_) {
if (ctrl_block_) {
ctrl_block_->add_ref();
}
}
// 移动构造函数
SharedPtr(SharedPtr&& other) noexcept : ctrl_block_(other.ctrl_block_) {
other.ctrl_block_ = nullptr;
}
// 析构函数
~SharedPtr() {
if (ctrl_block_) {
ctrl_block_->release_ref();
}
}
// 赋值运算符
SharedPtr& operator=(const SharedPtr& other) {
if (this != &other) {
if (ctrl_block_) {
ctrl_block_->release_ref();
}
ctrl_block_ = other.ctrl_block_;
if (ctrl_block_) {
ctrl_block_->add_ref();
}
}
return *this;
}
SharedPtr& operator=(SharedPtr&& other) noexcept {
if (this != &other) {
if (ctrl_block_) {
ctrl_block_->release_ref();
}
ctrl_block_ = other.ctrl_block_;
other.ctrl_block_ = nullptr;
}
return *this;
}
// 访问指针
T* get() const { return ctrl_block_ ? ctrl_block_->get() : nullptr; }
T& operator*() const { return *get(); }
T* operator->() const { return get(); }
// 引用计数
int use_count() const { return ctrl_block_ ? ctrl_block_->use_count() : 0; }
// 重置指针
void reset(T* ptr = nullptr) {
if (ctrl_block_) {
ctrl_block_->release_ref();
}
ctrl_block_ = ptr ? new ControlBlock<T>(ptr) : nullptr;
}
// 交换
void swap(SharedPtr& other) {
std::swap(ctrl_block_, other.ctrl_block_);
}
// 转换为bool
explicit operator bool() const { return get() != nullptr; }
private:
ControlBlock<T>* ctrl_block_;
template <typename U>
friend class WeakPtr;
};
// weak_ptr 实现
template <typename T>
class WeakPtr {
public:
WeakPtr() : ctrl_block_(nullptr) {}
WeakPtr(const SharedPtr<T>& shared) : ctrl_block_(shared.ctrl_block_) {
if (ctrl_block_) {
ctrl_block_->add_weak_ref();
}
}
WeakPtr(const WeakPtr& other) : ctrl_block_(other.ctrl_block_) {
if (ctrl_block_) {
ctrl_block_->add_weak_ref();
}
}
~WeakPtr() {
if (ctrl_block_) {
ctrl_block_->release_weak_ref();
}
}
WeakPtr& operator=(const WeakPtr& other) {
if (this != &other) {
if (ctrl_block_) {
ctrl_block_->release_weak_ref();
}
ctrl_block_ = other.ctrl_block_;
if (ctrl_block_) {
ctrl_block_->add_weak_ref();
}
}
return *this;
}
SharedPtr<T> lock() const {
SharedPtr<T> shared;
if (ctrl_block_ && ctrl_block_->use_count() > 0) {
shared.ctrl_block_ = ctrl_block_;
ctrl_block_->add_ref();
}
return shared;
}
int use_count() const { return ctrl_block_ ? ctrl_block_->use_count() : 0; }
private:
ControlBlock<T>* ctrl_block_;
};
class MyClass {
public:
MyClass() { std::cout << "MyClass constructed\n"; }
~MyClass() { std::cout << "MyClass destroyed\n"; }
void foo() { std::cout << "MyClass::foo()\n"; }
};
int main() {
// 创建shared_ptr
SharedPtr<MyClass> ptr1(new MyClass());
// 拷贝构造
SharedPtr<MyClass> ptr2 = ptr1;
std::cout << "Use count: " << ptr1.use_count() << std::endl; // 2
// 通过weak_ptr观察
WeakPtr<MyClass> weak = ptr1;
std::cout << "Use count via weak: " << weak.use_count() << std::endl; // 2
// 重置ptr1
ptr1.reset();
std::cout << "Use count after reset: " << ptr2.use_count() << std::endl; // 1
// 从weak_ptr获取shared_ptr
if (auto shared = weak.lock()) {
shared->foo();
} else {
std::cout << "Object already destroyed\n";
}
// ptr2离开作用域,对象被销毁
return 0;
}
请介绍 C++ 中 weak_ptr 的原理? #
回答重点 #
std::weak_ptr 是 C++11 引入的新特性,它主要搭配 std::shared_ptr 一起使用,它用来监视 std::shared_ptr 的生命周期,不会影响内部的引用计数,主要用于打破 std::shared_ptr 之间的循环引用问题。例如在对象 A 和对象 B 相互持有对方的 shared_ptr 时,会造成无法释放内存的情况,weak_ptr 可以帮助解决这个问题。
它提供了一种观察资源但不拥有资源的手段,我们可以通过它来检查资源是否依然存在,并且在需要时将其转变为一个 shared_ptr 进行使用。
扩展知识 #
1)循环引用:下面是 shared_ptr 循环引用的示例:
#include <iostream>
#include <memory>
using namespace std;
struct A;
struct B;
struct A {
std::shared_ptr<B> bptr;
~A() {
cout << "A delete" << endl;
}
void Print() {
cout << "A" << endl;
}
};
struct B {
std::shared_ptr<A> aptr; // 这里产生了循环引用
~B() {
cout << "B delete" << endl;
}
void PrintA() {
aptr->Print();
}
};
int main() {
auto aaptr = std::make_shared<A>();
auto bbptr = std::make_shared<B>();
aaptr->bptr = bbptr;
bbptr->aptr = aaptr;
bbptr->PrintA();
return 0;
}
输出:
A
从上面示例可以看到,A 持有了 B,B 又持有了 A,导致两者的引用计数都无法减为 0,两者对象都没办法析构,出现了内存泄漏。
2)解决循环引用:
使用 weak_ptr 就可以解决上面的循环引用问题,看示例代码:
#include <iostream>
#include <memory>
using namespace std;
struct A;
struct B;
struct A {
std::shared_ptr<B> bptr;
~A() {cout << "A delete" << endl;
}void Print() {cout << "A" << endl;
}
};
struct B {std::weak_ptr<A> aptr; // 这里改成weak_ptr
~B() {
cout << "B delete" << endl;
}
void PrintA() {
if (!aptr.expired()) { // 监视shared_ptr的生命周期
auto ptr = aptr.lock();
ptr->Print();
}
}
};
int main() {
auto aaptr = std::make_shared<A>();
auto bbptr = std::make_shared<B>();
aaptr->bptr = bbptr;
bbptr->aptr = aaptr;
bbptr->PrintA();
return 0;
}
输出:
A
A delete
B delete
因为 weak_ptr 不持有引用计数,不管理资源,所以这里不会出现循环引用问题,引用计数会减为 0,两者对象都会正常析构。
3)基本原理:weak_ptr 基于 shared_ptr 实现。weak_ptr 本身不管理资源,而是与 shared_ptr 共享内部控制块(control block)。这个控制块包含了实际资源指针、引用计数(shared_count 和 weak_count)。当所有的 shared_ptr 对象销毁时,资源被释放,但控制块直到所有 weak_ptr 也销毁时才会被释放。
4)成员函数:
lock():将weak_ptr转换为shared_ptr,若资源已被释放则返回一个空的shared_ptr。expired():检查weak_ptr指向的资源是否已被释放。
5)线程安全:控制块是线程安全的,因此 shared_ptr 和 weak_ptr 本身是线程安全的。多个线程可以同时使用 shared_ptr 和 weak_ptr 而不需要额外的同步机制。
STL 容器的六个组件是什么? #
主要是:容器,算法,迭代器,仿函数, 适配器,空间配置器。
容器 #
用于存储和管理数据,提供多种数据结构(如动态数组、链表、树、哈希表等)。
分类:
std::vector<int> vec = {1, 2, 3}; _// 动态数组_
std::map<std::string, int> m = {{"Alice", 25}}; _// 键值对_
算法 #
作用:对容器中的数据进行通用操作(如排序、查找、遍历、修改等),通过迭代器与容器解耦。
分类:
- 非修改序列算法:
find、count、for_each。 - 修改序列算法:
copy、replace、remove。 - 排序与搜索算法:
sort、binary_search。 - 数值算法:
accumulate(求和)、inner_product(点积)。
std::sort(vec.begin(), vec.end()); _// 排序_
auto it = std::find(vec.begin(), vec.end(), 2); _// 查找元素_
迭代器 #
提供访问容器元素的统一接口,充当容器与算法之间的桥梁(类似指针的抽象)。
for (auto it = vec.begin(); it != vec.end(); ++it) {
std::cout << *it << " "; _// 通过迭代器访问元素_
}
仿函数 #
行为类似函数的对象(重载了 operator() 的类),用于定制算法的操作逻辑。它比普通函数更灵活,可携带状态(通过成员变量)。
分类:
- 算术仿函数:
plus、minus、modulus(定义在<functional>中)。 - 关系仿函数:
less、greater、equal_to。 - 逻辑仿函数:
logical_and、logical_not。
std::sort(vec.begin(), vec.end(), std::greater<int>()); _// 降序排序_
适配器 #
作用:对现有组件进行封装,改变其接口或行为,提供更特定的功能。
常见适配器:
- 容器适配器:
stack(基于deque/list)、queue(基于deque)、priority_queue(基于vector)。 - 迭代器适配器:
reverse_iterator(反向遍历)、insert_iterator(插入元素)。 - 函数适配器:
bind(参数绑定)、not1(逻辑取反)。
- 容器适配器:
std::stack<int> s; _// 默认基于 deque_
s.push(10); _// 适配器隐藏了底层容器的细节_
空间配置器 #
- 作用:管理容器的内存分配与释放,实现内存分配的灵活控制(如内存池优化)。
- 默认行为:STL 容器默认使用
std::allocator(调用new和delete)。 - 自定义场景:需要优化内存碎片或性能时,可替换为自定义分配器。
std::vector<int, MyAllocator<int>> vec; _// 使用自定义分配器_
六大组件的关系 #
- 容器通过空间配置器管理内存。
- 算法通过迭代器访问容器数据。
- 仿函数和适配器增强算法和容器的灵活性。
- 组件间高度解耦,用户可独立扩展某一部分(如自定义容器或分配器)
🌟C++ 有哪些进程间通信的方式? #
回答重点 #
C++ 支持多种进程间通信(IPC)方式:
1)管道(Pipes)
2)消息队列(Message Queues)
3)共享内存(Shared Memory)
4)信号(Signals)
5)套接字(Sockets)
6)文件(Files)
扩展知识 #
这些 IPC 通信方式各有优缺点,
1)不同场景选择不同方式
管道(Pipes)
- 匿名管道:通常用于具有父子关系的进程间通信,它们是单向的,也就是数据只能沿一个方向流动,如果需要双向通信,需要使用两个匿名管道。
- 命名管道(Named Pipe):命名管道通过在文件系统中创建一个特殊文件来实现。它可以用于没有亲缘关系的进程间通信,并且是双向的。
消息队列(Message Queues) 进程以消息的形式进行通信。消息队列具有以下特点:
- 消息队列中的消息具有特定的标识,可以优先级排序。
- 不需同步,消息独立存在,不会覆盖。
- Posix 中可以使用
mq_open、mq_send、mq_receive、mq_close、mq_unlink进行操作。
共享内存(Shared Memory) 共享内存是最快的进程间通信方式,因为数据不需要从一个缓冲区拷贝到另一个缓冲区。特点是:
- 多个进程可以同时访问同一个内存段。
- 在 Linux 上,使用
shmget,shmat,shmdt,shmctl等系统调用进行操作。 - 需要同步机制(如信号量)来防止竞争条件。
信号(Signals) 信号是一种最古老的进程间通信方式。信号是一种比较简单的通知机制:
- 用于通知进程发生了某个事件。
- 由于信号携带的信息量很少,通常用于简单的通知和控制。
套接字(Sockets) 套接字不仅支持进程间通信,而且可以用于网络通信。分为:
- 本地域套接字(UNIX Domain Sockets):用于同一主机上的进程间通信。
- 网络套接字(TCP/UDP):用于不同主机间的进程通信,应用广泛但相对速度较慢。
文件(Files) 尽管效率不是很高,但使用文件进行进程间通信比较简单:
- 通过文件写入和读取来传递信息。
- 避免文件竞争通常使用文件锁(如
flock)。
2)不同平台建议选择不同的IPC方式
跨平台建议 #
关键对比维度 #
- 速度:共享内存 > 管道/套接字 > 消息队列 > 文件
- 复杂度:共享内存(需同步) > 套接字 > 消息队列 > 管道 > 文件
- 数据量:共享内存(大块数据) > 消息队列(结构化数据) > 管道/套接字(流式数据)
什么场景下使用锁?什么场景下使用原子变量? #
回答重点 #
锁(lock)和原子变量(atomic)都可以用作同步机制,它们有各自的适用场景:
1)使用锁的场景:
- 当需要保护长时间访问的临界区时,比如复杂的操作或逻辑(如链表、树等复杂数据结构的操作)。
- 当多个共享资源需要同步访问时,锁可以一次性锁定多个资源,确保整体一致性。
- 在涉及到复杂的操作时,比如需要一次性更新多个共享变量。
2)使用原子变量的场景:
- 当操作可以在一个原子步骤内完成时,比如简单的整数增减、标志位切换。
- 当性能非常关键,且锁的开销和上下文切换的成本过高时。原子操作通常比使用锁更轻量级。
- 用于实现非阻塞算法时,因为原子变量不会导致线程挂起而等待锁释放。
建议:优先使用原子变量,如果发现使用原子变量不能满足同步机制的需求,那就使用锁。
扩展知识 #
这里进一步探讨锁和原子操作:
1)锁的类型:
- 互斥锁(Mutex):最常见的普通锁,用于保护一个共享资源。
- 读写锁(Read-Write Lock):允许多个读者并行访问,但写者访问需要独占。
- 自旋锁(Spinlock):线程在等待时会不断轮询锁状态,而不是挂起,非常适合短时间持有锁的场景。
2)原子操作:
- 可以使用
std::atomic库提供的原子类型,如std::atomic<int>,std::atomic<bool>,atomic是个模板类,你还可以使用 double 等类型填充。 - 这些操作通常由硬件直接支持,比如 x86 架构的"Lock"前缀指令,确保读取-修改-写入一个不可分割的操作。
3)实际应用示例:
- 使用锁的例子:假设我们有一个共享的
std::map,需要在线程间进行插入和删除操作,我们可以使用std::mutex来保护这个map。
std::mutex mtx;
std::map<int, std::string> sharedMap;
void insertIntoMap(int key, const std::string& value) {
std::lock_guard<std::mutex> lock(mtx);
sharedMap[key] = value;
}
- 使用原子变量的例子:假设我们有一个计数器,只需要每次增加或减少 1,使用
std::atomic更高效。
std::atomic<int> counter(0);
void incrementCounter() {
counter++;
}
void decrementCounter() {
counter--;
}
选择建议 #
C++ 什么场景用线程?什么场景用协程? #
回答重点 #
线程和协程是两种不同的并发编程方式,各有其适用的场景。
1)线程使用场景:
- CPU 密集型任务:线程适合处理需要大量计算的任务,如矩阵运算、复杂算法的并行处理。
- I/O 密集型任务:线程更适用于处理需要频繁与外部系统进行数据交换的任务,如网络请求、文件读写。
- 多核处理器充分利用:当你希望充分利用多核处理器的优势,进行真正的并行计算时,线程非常适合。
2)协程使用场景:
- 轻量级任务切换:协程适用于需要轻量级任务切换的场景,像是大量小任务需要被并发执行时,比如异步的任务处理、网络服务器等等。
- 高并发处理:在处理大量高并发请求时,协程更合适,因为它的开销相对于线程更小,如高并发的 web 服务器处理请求时。
- 复杂控制流:协程能够方便地暂停和恢复执行,在处理需要复杂状态机或多步骤操作时显得更加便捷。
扩展知识 #
结合应用场景,可以更深入地探讨线程和协程的使用:
1)线程的优势:
- 真正并行:线程能够在多核处理器上实现真正的并行执行,充分利用硬件资源。
- 适用广泛的库支持:比如 C++ 标准库提供了
std::thread,非常易于使用。
2)线程的劣势:
- 资源开销大:线程创建和上下文切换的开销较大。
- 复杂的同步机制:面对竞争条件时,需要且不容易处理好各种同步机制,如锁、互斥量等,容易产生死锁等问题,或其他线程安全问题。
3)协程的优势:
- 高效的任务切换:协程是用户态的轻量级任务切换,创建和切换开销非常小。
- 更简单的逻辑控制:协程的暂停和恢复机制使编写异步代码更加直观、易读,避免了回调地狱。
4)协程的劣势:
- 单线程执行:协程本质上是单线程的,因此无法真正实现并行,需要与线程结合使用才能扩展到多核。
- 库支持欠缺:截至目前,C++20 才引入了较为标准的协程库支持,应用和生态相对较新,相比线程仍有待成熟。
5)实际应用示例:
- 多线程应用:如视频渲染、数据压缩解压、科学计算等需要占用多个 CPU 资源的场景。
- 协程应用:如高并发网络服务器、多任务调度器、大量异步 I/O 的处理等。
C++20 引入的协程库提供了更强大的工具来简化异步编程。在特定场景下,比如高并发请求或复杂异步操作,使用协程能够显著简化代码并提高性能,相较于传统的线程方案,优势明显。
选择建议 #
混合使用场景 #
补充说明 #
协程的局限性:
- 协程依赖异步 I/O 框架(如
io_uring或libuv)才能发挥性能优势。 - C++20 协程为无栈协程(Stackless),需通过
co_await/co_yield显式切换。
- 协程依赖异步 I/O 框架(如
线程的优化方向:
- 使用线程池(如
std::async)避免频繁创建/销毁线程。 - 结合无锁数据结构减少同步开销。
- 使用线程池(如
用过哪些 C++ 日志框架?都有什么优缺点? #
回答重点 #
C++ 的日志框架,流行的主要有:log4cpp、Boost.Log、spdlog、glog。
各自的优缺点如下:
1)log4cpp:
- 优点:功能强大,支持多种日志输出和格式化方式;配置灵活,支持外部配置文件。
- 缺点:配置相对复杂,文档不是太完善,比较老的库了,现在用的不是很多。
2)Boost.Log:
- 优点:属于 Boost 库的一部分,方便与 Boost 的其他库集成;功能全面,支持多线程。
- 缺点:编译时间较长,配置略显复杂。
3)spdlog:推荐使用。
- 优点:非常快,效率很高;易于使用,接口简洁;支持 header-only 形式的接入,不需要进行复杂的编译配置。
- 缺点:功能相对简单,不如 log4cpp 和 Boost.Log 复杂功能全面。
4)glog:
- 优点:Google 出品,性能和稳定性有保证;支持多线程,适合大型项目。
- 缺点:库的体积相对较大,不支持 header-only 接入,接入起来比较麻烦。
扩展知识 #
为了让大家更好地理解,我再补充一些背景和使用体验吧。
1)log4cpp: 我发现 log4cpp 在一些老旧的 C++ 项目中很常见,因为它出现的时间较长,功能也相对全面。通过 external 配置文件(如 XML 或 properties 文件),可以精确地控制日志的输出格式和目录,然而,新手在配置时可能会有点吃力,需要认真研读官方文档,新项目就不太建议使用 log4cpp 了。
2)Boost.Log: Boost.Log 是 Boost 库的一个模块,提供了相当全面的日志功能。由于库的复杂性以及编译时间较长,项目启动时间可能会有所增加。不过,如果你的项目已经使用了 Boost 库,添加 Boost.Log 可能会是一个不错的选择,因为它们之间的集成会比较顺畅。
3)spdlog: 如果只推荐一个日志库的话,我推荐使用 spdlog。spdlog 可以说是一个新时代的日志框架,它采用了 C++11/14 的新特性,使得整体效率非常高。我非常喜欢它的 header-only 设计,让你不用担心额外的库文件。对于性能有极高要求的项目,spdlog 是一个理想的选择,但要注意的是,它的功能相对简单,如果你需要非常复杂的日志功能,可能需要自己进行二次开发。
4)glog: glog 是 Google 的一个 C++ 日志库,通常用在一些需要高可靠性的项目中。它支持多线程,这让我在构建一些大型项目时非常放心。不过,相对于 spdlog,它在接入便捷性和性能上都略逊一筹。
详细功能对比 #
🌟 介绍下 socket 的多路复用?epoll 有哪些优点? #
回答重点 #
多路复用这个术语在网络编程中非常重要,尤其是在涉及 I/O 操作的时候。所谓 socket 的多路复用,指的是在单个线程或进程中可以同时处理多个 socket 的 I/O 事件,可以提高整体效率和资源利用率。
常见的多路复用机制包括 select、poll 和 epoll,在 Linux 平台上这种机制主要依赖于 epoll,因为它在大多数情况下性能更好。epoll 是 Linux 内核针对大量并发连接进行高效管理的系统调用接口。
编程过程中,建议使用 epoll。epoll 相比于 select 和 poll,主要有以下几个优点:
1)效率高:epoll 使用事件通知的方式能够解决轮询(polling)带来的性能瓶颈,对大量文件描述符的处理效率高。
2)不受描述符数量限制:select 有文件描述符数量的上限(通常是 1024),而 epoll 没有这种限制。
3)内存拷贝少:epoll 的系统调用仅在需要数据时进行内存拷贝,减少了系统开销。
4)支持边沿触发:相比于 select 和 poll 的水平触发(level-triggered),epoll 还支持边沿触发(edge-triggered),能够适应更多的应用场景。
扩展知识 #
可以从几个方面进一步展开:
1)select 和 poll 的缺点: select 和 poll 都是 I/O 多路复用的早期实现,但它们有一些不足。例如,select 在每次调用时都需要重新传递所有文件描述符集合,并进行内存拷贝,而 poll 则需要传递整个文件描述符数组,这在文件描述符特别多的情况下,性能开销很大。此外,select 还有一个描述符数量的限制。
2)epoll 的工作机制: epoll 使用两个系统调用来操作:epoll_create 创建一个 epoll 实例,epoll_ctl 增加、修改或删除要控制的文件描述符。epoll_wait 则是用于等待事件的发生。与 select 不同的是,epoll 每次只需传递发生的事件,不需要传递所有文件描述符,极大提高了效率。
3)边沿触发与水平触发: 水平触发(Level-triggered, LT)是默认的触发模式,处理器只要发现事件有未处理的数据就会再次通知,在传统的 select 和 poll 中也是这种方式。而边沿触发(Edge-triggered, ET)是更高效的一种方式,它只会在状态变化(例如从无数据到有数据)时通知一次,开发难度稍大但可以减少系统调用次数,提高性能。
通过上面介绍,可以看出 epoll 是如何更高效率地进行 I/O 多路复用的。在实际工作中,在大规模高并发 I/O 操作时,建议优先选择 epoll。
Socket 多路复用机制对比 #
epoll 的核心优势详解 #
1. 高效事件驱动(O(1)复杂度) #
- 原理:通过内核事件表(红黑树 + 就绪链表)直接获取就绪事件
- 优势:无需遍历所有 fd,性能随 fd 数量增长几乎不下降
2. 无文件描述符数量限制 #
- select 限制:默认仅支持 1024 个 fd
- epoll 突破:仅受系统内存限制,可支持数十万并发连接
🌟C++ 中 vector 的 push_back 和 emplace_back 有什么区别? #
回答重点 #
两者都是 vector 类的成员函数,用于在 vector 的末尾添加元素。它们之间的主要区别在于添加元素的方式:
- push_back:接受一个已存在的对象作为参数,进行拷贝或移动,将其添加到 vector 的末尾。这会触发一次拷贝或移动构造函数的调用,具体取决于传递的对象是否可移动。
- emplace_back:接受构造函数的参数,直接在 vector 的内存空间中调用该对象的构造函数,避免了额外的拷贝或移动操作。这可以提高效率,特别是在处理复杂对象时。
扩展知识 #
性能差异:
- push_back 因为需要拷贝或移动已经存在的对象,较之 emplace_back 效率稍低,特别是对于大型或复杂对象,额外的拷贝或移动会显著影响性能。
- emplace_back 直接在容器中构造对象,避免了不必要的对象构造和析构以及拷贝或移动,效率更高。
使用场景:
- 如果需要将一个已经存在的对象添加到 vector 中,使用 push_back。
- 如果希望直接在 vector 中构造对象,避免额外的拷贝或移动开销,使用 emplace_back。
代码示例:
#include <iostream>
#include <vector>
#include <string>
class MyClass {
public:
MyClass(int a, std::string b) : a_(a), b_(b) {
std::cout << "Constructor called\n";
}
MyClass(const MyClass& other) : a_(other.a_), b_(other.b_) {
std::cout << "Copy Constructor called\n";
}
MyClass(MyClass&& other) noexcept : a_(other.a_), b_(std::move(other.b_)) {
std::cout << "Move Constructor called\n";
}
private:
int a_;
std::string b_;
};
int main() {
std::vector<MyClass> v;
v.reserve(16);
std::cout << "Using push_back:\n";
MyClass obj1(1, "example1");
v.push_back(obj1); // 会调用拷贝构造
v.push_back(std::move(obj1)); // 会调用移动构造
std::cout << "\nUsing emplace_back:\n";
v.emplace_back(2, "example2"); // 直接在 vector 内存空间中构造,无需拷贝或移动
std::cout << "\nover \n";
return 0;
}
输出:
Using push_back:
Constructor called
Copy Constructor called
Move Constructor called
Using emplace_back:
Constructor called
over
在上面的示例中(输出结果也贴在了代码中),当使用 push_back 时,会调用拷贝构造函数或移动构造函数。而使用 emplace_back 时,直接构造对象,避免了额外的构造和析构开销。
线程安全性:无论是 push_back 还是 emplace_back,它们在多线程环境下都不是线程安全的。因此,必须考虑同步机制(如互斥锁)来避免数据竞争。
二者选择:建议无脑选择 emplace_back。
🌟C++ 成员变量的初始化顺序是固定的吗? #
回答重点 #
成员变量的初始化顺序是固定的。成员变量总是按照它们在类中出现的顺序进行初始化,而不是在构造函数中的初始化列表顺序。
例如:
class MyClass {
public:
MyClass(int a, int b) : b(b), a(a) {}
private:
int b;
int a;
};
即使在构造函数的初始化列表中先初始化 b,后初始化 a,成员变量仍然会按照 int b; int a; 的顺序来初始化。
扩展知识 #
当涉及到成员变量的初始化时,有几个重要的点需要注意:
1)依赖关系(重点): 如果类的成员变量之间存在依赖关系,需要特别注意初始化顺序。例如,当一个成员变量的初始值取决于另一个成员变量的值时,应确保这些依赖关系在声明顺序中得到正确处理。
2)静态成员变量: 静态成员变量的初始化与普通成员变量不同。静态成员变量的初始化通常在类定义体外进行,并且只初始化一次。
3)初始化列表的使用: 使用初始化列表对于效率和可读性通常是有益的,因为它避免了成员变量在构造函数体内先被默认初始化然后再被赋值的开销。
4)继承时的初始化顺序: 在类的继承体系中,基类的构造函数会先于派生类的构造函数执行,因此基类的成员变量也会先于派生类的成员变量进行初始化。
具体地说:
- 基类的成员变量按声明顺序初始化。
- 派生类的成员变量按声明顺序初始化。在这个过程中,派生类的初始化顺序紧随基类之后。
5)成员对象的初始化顺序: 如果类中包含其他类的对象作为成员,这些成员对象也会按照它们的声明顺序优先于自身的构造函数体内的代码进行初始化。
C++ 中未初始化和已初始化的全局变量放在哪里?全局变量定义在头文件中有什么问题? #
回答重点 #
1)未初始化的全局变量放在 BSS 段,而已初始化的全局变量放在数据段(Data Segment)。
2)将全局变量定义在头文件中会引发多重定义的问题,如果头文件可能会被多个源文件包含,导致编译时同一个变量被多次定义,进而编译失败。
扩展知识 #
下面深入探讨一下这些段和多重定义的问题。
1)BSS 段和数据段
BSS 段全称 “Block Started by Symbol” 或 “Block Storage Segment”,用于存放程序中未初始化或初始化为零的全局变量和静态变量。因为这些变量在程序加载时会被自动初始化为零,所以在编译好的程序中只占用很少的空间(只是需要在运行时期占用内存)。
数据段则包含初始化过的全局变量和静态变量。这个段在程序加载到内存时也被加载,并包含那些已经有初始值的变量,它们在程序运行期间保持这个初始值。
2)头文件中的全局变量定义问题
头文件中的全局变量定义会造成重复定义的问题。假设你在一个头文件 example.h 中这样定义了一个全局变量:
int globalVar;
然后你在两个源文件 file1.cpp 和 file2.cpp 中都包含了 example.h。结果是编译器会在链接的时候发现 globalVar 被定义了两次,导致编译错误。
解决这一问题的方法,可以使用 static 修饰变量,或者使用 extern 关键字声明全局变量,然后在一个源文件中进行定义,例如:
// example.h
extern int globalVar;
// file1.cpp
#include "example.h"
int globalVar = 0; // 这里只定义一次
// file2.cpp
#include "example.h"//
可以直接使用 globalVar,但不需要再次定义
通过这个方式,在头文件中的 extern 声明不会实际分配内存,而是在一个特定的源文件中定义一次,其他源文件包含头文件时就共享这个变量的定义。这样不仅能避免多重定义的问题,还能确保每个文件都能访问同一个全局变量。这是很多项目标准的做法,能有效管理全局变量及其作用范围。
开发建议:不要使用全局变量,可以考虑做好代码设计,非必要不使用全局变量。
🌟 什么情况下会出现内存泄漏?如何避免内存泄漏? #
回答重点 #
申请了内存,但未释放,就是内存泄漏,有几个经典的场景:
1)对象创建后却没有释放。
2)智能指针的循环引用,两者互相持有,导致引用计数永不为 0,内存无法释放。
3)集合类容器中,删除元素后未释放内存。
4)在外面手动申请的内存,但进入了异常处理,手动分配的内存未释放。
5)静态成员或全局变量持有动态分配的对象。
避免内存泄漏的方法:
1)使用智能指针(比如 std::unique_ptr 和 std::shared_ptr),自动管理内存。
2)用 RAII 原则,通过构造函数分配资源并在析构函数中释放。
3)执行静态分析工具(如 cppcheck)和内存检测工具(如 Valgrind)来检测代码质量和内存泄漏。
4)规范编码,确保每个 new 对应一个 delete,每个 malloc 对应一个 free。但在函数中也要注意对 if-else-return 分支的处理,确保每个 return 之前都能释放对应的内存。
5)避免循环引用,使用 std::weak_ptr 解决循环引用的问题。
扩展知识 #
探讨一下智能指针的相关知识点。
C++11 标准引入了三种主要的智能指针:std::unique_ptr、std::shared_ptr 和 std::weak_ptr:
1. std::unique_ptr
#
std::unique_ptr 是一种独占所有权的智能指针,意味着同一时间内只能有一个 unique_ptr 指向一个特定的对象。当 unique_ptr 被销毁时,它所指向的对象也会被销毁。
使用场景:
- 当你需要确保一个对象只被一个指针所拥有时。
- 当你需要自动管理资源,如文件句柄或互斥锁时。
示例代码:
#include <iostream>
#include <memory>
class Test {
public:
Test() { std::cout << "Test::Test()"; }
~Test() { std::cout << "Test::~Test()"; }
void test() { std::cout << "Test::test()"; }
};
int main() {
std::unique_ptr<Test>
ptr(new Test());
ptr->test();
// 当ptr离开作用域时,它指向的对象会被自动销毁
return 0;
}
2. std::shared_ptr
#
std::shared_ptr 是一种共享所有权的智能指针,多个 shared_ptr 可以指向同一个对象。内部使用引用计数来确保只有当最后一个指向对象的 shared_ptr 被销毁时,对象才会被销毁。
使用场景:
- 当你需要在多个所有者之间共享对象时。
- 当你需要通过复制构造函数或赋值操作符来复制智能指针时。
示例代码:
#include <iostream>
#include <memory>
class Test {
public:
Test() { std::cout << "Test::Test()"; }
~Test() { std::cout << "Test::~Test()"; }
void test() { std::cout << "Test::test()"; }
};
int main() {
std::shared_ptr<Test> ptr1(new Test());
std::shared_ptr<Test> ptr2 = ptr1;
ptr1->test();
// 当ptr1和ptr2离开作用域时,它们指向的对象会被自动销毁
return 0;
}
3. std::weak_ptr
#
std::weak_ptr 是一种不拥有对象所有权的智能指针,它指向一个由 std::shared_ptr 管理的对象。weak_ptr 用于解决 shared_ptr 之间的循环引用问题。
使用场景:
- 当你需要访问但不拥有由
shared_ptr管理的对象时。 - 当你需要解决
shared_ptr之间的循环引用问题时。 - 注意
weak_ptr肯定要和shared_ptr搭配使用。
示例代码:
#include <iostream>
#include <memory>
class Test {
public:
Test() { std::cout << "Test::Test()"; }
~Test() { std::cout << "Test::~Test()"; }void test() { std::cout << "Test::test()"; }
};
int main() {
std::shared_ptr<Test> sharedPtr(new Test());
std::weak_ptr<Test> weakPtr = sharedPtr;
if (auto lockedSharedPtr = weakPtr.lock()) {
lockedSharedPtr->test();
}// 当sharedPtr离开作用域时,它指向的对象会被自动销毁
return 0;
}
这三种智能指针各有其用途,选择哪一种取决于你的具体需求。
内存泄漏常见场景 #
智能指针对比 #
防范措施对比 #
最佳实践示例 #
1. 智能指针使用 #
// 推荐做法
auto ptr = std::make_shared<Resource>(); // 替代 new+shared_ptr
std::weak_ptr<Resource> observer = ptr; // 避免循环引用
// 危险做法
Resource* raw_ptr = new Resource();
std::shared_ptr<Resource> p1(raw_ptr);
std::shared_ptr<Resource> p2(raw_ptr); // 导致双重释放!
🌟C++ 中为什么要引入 make_shared?它有什么优点? #
回答重点 #
C++ 中创建 shared_ptr 有两种方式,一种是直接把裸指针传递进去,一种是使用 make_shared:
class A {
public:
A() {}
};
std::shared_ptr<A> sp1 = std::shared_ptr<A>(new A());
std::shared_ptr<A> sp2 = std::make_shared<A>();
既然推出了 make_shared,肯定是有优点,它的优点包括:
1)简化代码:使用 make_shared 可以简化创建 shared_ptr 实例的代码,代码更加清晰。
2)性能更好:make_shared 在内存分配时只需要一次分配,而直接使用 shared_ptr 构造函数可能需要两次内存分配。
3)降低内存泄漏风险:使用 make_shared 可以避免由于异常导致的部分已分配内存未释放的问题。
扩展知识 #
详细说一说 make_shared 相关的知识点:
1)shared_ptr 基础:与之对应的是 unique_ptr,, 但使用它有限制,比如不能共享所有权。而 std::shared_ptr 是一个可以共享控制权的智能指针,可以自动管理动态分配的对象生命周期。
2)new 和 shared_ptr :在没有 make_shared 之前,我们通常这样创建 shared_ptr: std::shared_ptr<int> sp(new int(5));。这个过程其实做了两个动作:创建一个临时对象,又创建一个 shared_ptr 对象。如果第一步的内存分配成功,但第二步抛出异常,那么就会发生内存泄漏。
3)make_shared 内部原理:make_shared 将对象的动态内存和控制块内存(存储引用计数的那块内存)一次性分配,减少了内存分配的次数。例如:auto sp = std::make_shared<int>(5);,这种方式比前一种方式高效,并且更加安全。
4)性能更好:单次内存分配意味着分配器只调用一次,这比多次调用(可能导致的内存碎片问题)更加高效。此外,这种方式在多线程环境中也有一定优势,减少了分配内存时的竞争。
5)异常安全:使用 make_shared,如果在创建过程中抛出异常,因为它是“全有或全无”的过程,所以不需要担心部分资源分配成功导致的内存泄漏。例如,make_shared 可以保证在对象和控制块都构建成功之后才开始使用它们。
如何理解 C++ 中的 atomic? #
回答重点 #
std::atomic 用于实现原子操作,它也是 C++11 引入的新特性。
多个线程可以对同一个变量进行读写操作,不会导致数据竞争或中间状态,也不需要锁的保护,一定程度上简化了代码编写,性能也会有提高。
扩展知识 #
这个话题其实挺有深度的,这里展开说说:
1)什么是原子操作:原子操作指的是一个不可分割的操作,要么完全执行,要么完全不执行,不会被中途打断。举个例子,假设两个线程要同时增加一个变量,如果没有原子操作,可能会导致未预期的结果。而使用 std::atomic 后,这个操作就十分安全了。
2)如何使用 std::atomic:在 C++ 中,可以用 std::atomic 来修饰基本的数据类型,如 int, bool,甚至指针。示例如下:
#include <atomic>
#include <iostream>
#include <thread>
std::atomic<int> counter(0);
void increment(int n) {
for (int i = 0; i < n; ++i) {
++counter; // 原子操作,线程安全
}
}
int main() {
std::thread t1(increment, 1000);
std::thread t2(increment, 1000);
t1.join();
t2.join();
std::cout << "Final counter value: " << counter << std::endl; // 预期输出2000
return 0;
}
3)底层实现:std::atomic 通过 CPU 提供的原子指令来实现这些不可分割的操作。现代 CPU 会提供一组指令,比如 CMPXCHG, XADD 等来实现原子的读或写。
4)内存序约束:C++ 提供了多种内存序约束,比如 memory_order_relaxed, memory_order_acquire, memory_order_release 等。这些约束让你可以更好地控制程序的内存可见性和行为。
例如,memory_order_relaxed 只保证原子性,但不提供任何同步或顺序保证,而 memory_order_acquire 和 memory_order_release 则提供更严格的同步机制。
atomic 默认使用的是 memory_order_seq_cst,也就是最严格的内存序约束,既保证原子性,又提供了同步顺序保证。详见 cppreference。
5)和锁比较:虽然 std::atomic 可以在某些场景下替代锁,但它并不是万能的。锁在某些复杂场景下仍然是不可替代的。原子操作更适合一些基本的计数器或标志位,而对于复杂的数据结构,锁的使用仍是较优选择。
6)性能:使用原子操作通常比使用锁要快,因为锁涉及到上下文切换和操作系统调度,而原子操作都是硬件级别的操作。经过优化的原子操作可以使得你的程序在多线程环境下有更好的性能表现。
#
什么情况下会出现死锁?如何避免死锁? #
回答重点 #
本题主要考察死锁出现的四大必要条件。
什么情况下会发生死锁?一般来说,多个线程相互等待对方持有的资源且都不释放自己的资源,这种现象称为死锁。
具体有四个必要条件,必须同时满足才会发生死锁:
1) 互斥条件:线程对分配的资源有排他性访问,即每一个资源要么分配给一个线程,要么是可用的。
2) 占有且等待:一个线程已经占有至少一个资源,但又在等待另一个资源,而此时该资源被其他线程占有。
3) 不可剥夺:线程占有的资源不能被剥夺,资源只能在使用完后由线程自行释放。
4) 环路等待:存在一种资源等待的环形链,即线程 A 在等待线程 B 占有的资源,而线程 B 在等待线程 C 占有的资源,….,直到最后一个线程等待线程 A 占有的资源,从而形成一个等待环路。
这四大必要条件,只要能够破坏其一,就能避免死锁,可以采取以下几种措施:
1) 避免互斥条件:尽量减少资源的独占性,使用非阻塞同步机制。
2) 破坏占有且等待:采用资源预分配策略,即进程一次性请求所需的所有资源。
3) 破坏不可剥夺:如果一个进程得不到所需的资源,应释放它所持有的资源,或者使用优先级来剥夺资源。
4) 破坏环路等待:对系统中的资源进行排序,每个线程按序请求资源,避免形成环路。
扩展知识 #
下面详细解释下这几个关键点。
1)互斥条件:资源同一时间只能被一个线程所占有,可以通过使用锁(如 std::mutex)来确保互斥。
std::mutex mtx;
void critical_section() {
std::lock_guard<std::mutex> lock(mtx); // 确保互斥访问
// 临界区代码
}
2)占有且等待:
- 一个线程可能需要在持有资源 A 的情况下再去请求资源 B,这样就满足了占有且等待的条件。
- 避免这种情况可以用资源一次性分配,确保一个线程在开始执行时已经获得了所有所需资源。
std::mutex mtxA, mtxB;
void thread_func() {
std::unique_lock<std::mutex> lockA(mtxA, std::defer_lock);std::unique_lock<std::mutex> lockB(mtxB, std::defer_lock);
std::lock(lockA, lockB); // 脱离单独锁定合并为原子操作,避免死锁
// 临界区代码
}
3)不可剥夺:如果一个线程得不到它所需的所有资源,可以释放已占用的资源,然后过一段时间再尝试重新获取。
std::mutex mtx1, mtx2;
void thread_func() {
while (true) {
mtx1.lock();
if (mtx2.try_lock()) {
// 获得所需资源,进行处理
mtx2.unlock();
mtx1.unlock();
break;
} else {
mtx1.unlock();
std::this_thread::yield(); // 让出处理器一段时间再重试
}
}
}
4)环路等待:通过对所有资源进行排序,确保按序请求资源,这样就避免了环形等待。
std::mutex mtx1, mtx2;
void thread_func1() {
std::lock(mtx1, mtx2); // 遵守资源请求顺序
std::lock_guard<std::mutex> lock1(mtx1, std::adopt_lock);
std::lock_guard<std::mutex> lock2(mtx2, std::adopt_lock);
// 临界区代码
}
void thread_func2() {
std::lock(mtx1, mtx2); // 遵守资源请求顺序
std::lock_guard<std::mutex> lock1(mtx1, std::adopt_lock);
std::lock_guard<std::mutex> lock2(mtx2, std::adopt_lock);
// 临界区代码
}
通过这些方法就可以有效地避免死锁的发生。需要注意的是,避免死锁是一项非常重要也非常复杂的工作,需要仔细的设计和检查。
破坏环路等待条件很常见,一般开发过程中,只要我们可以保证资源加锁的顺序是一致的,基本都可以避免死锁的发生。
C++ 中如何实现一个单例模式? #
回答重点 #
现在最常见的实现单例模式的方法就是使用 static 静态局部变量的懒汉模式了,可以归纳为以下几点:
- 将构造函数、拷贝构造函数和赋值操作符设为
private,防止外部模块通过它们创建对象。 - 在类中提供一个静态的、返回类实例的
public方法。 - 使用局部静态变量初始化类实例,确保线程安全的懒汉模式。
下面是一个具体的示例代码:
class Singleton {
private:
// 私有构造函数
Singleton() {}
// 禁止拷贝构造函数和赋值操作符
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
public:
// 获取唯一实例的静态方法
static Singleton& getInstance() {
static Singleton instance;
return instance;
}
// 其他成员函数
void someMemberFunction() {
// TODO: 实现功能
}
};
这个实现利用了 C++11 局部静态变量的线程安全性,确保多线程环境下仅创建一个实例。
扩展知识 #
饿汉模式与懒汉模式:
- 饿汉模式:实例在程序开始运行时就被创建,常见的做法是直接在类中初始化静态成员。
- 懒汉模式:实例在首次使用时才被创建,节省资源。
上面的代码属于懒汉模式,而且线程安全。
线程安全: C++11 之前的局部静态变量并不保证线程安全。在 C++11 及之后,局部静态变量的初始化是线程安全的。此外,也可以使用互斥锁(如 std::mutex)来显式保证线程安全。
class Singleton {
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static std::mutex mutex_;
public:
static Singleton& getInstance() {
std::lock_guard<std::mutex> lock(mutex_); // C++11 之后可以不用锁
static Singleton instance;
return instance;
}
};
std::mutex Singleton::mutex_;
双重检测机制: 在某些情况下,双重检测机制也是实现单例模式的常用方法,尤其是针对一些旧版本的多线程系统。
class Singleton {
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton* instance_;
static std::mutex mutex_;
public:
static Singleton* getInstance() {
if (instance_ == nullptr) {
std::lock_guard<std::mutex> lock(mutex_);
if (instance_ == nullptr) { // 双重检测
instance_ = new Singleton();
}
}
return instance_;
}
};
Singleton* Singleton::instance_ = nullptr;
std::mutex Singleton::mutex_;
内存管理和实例销毁: 在需要明确销毁单例对象的情况下,可以使用智能指针(如 std::unique_ptr)来管理单例对象的生命周期,或者在程序结束时手动清理。
单例模式的应用场景: 单例模式通常用于需要全局访问的系统配置、日志记录器、线程池管理、数据库连接池等场景。
🌟 请介绍下 C++ 中的 std::sort 算法? #
回答重点 #
std::sort 非常高效,它不单纯是快速排序,而是使用了一种名为 introspective sort(内省排序)的算法。
内省排序是快速排序、堆排序和插入排序的结合体,它结合这些算法优点的同时避免它们的缺点,特别是快速排序在最坏情况下的性能下降问题。
注意:本题介绍,仅限于 GCC 的源码实现。
扩展知识 #
快速排序:内省排序首先使用快速排序算法。利用快速排序分而治之的特点,通过选取一个 pivot 元素,将数组分为两个子数组,一个包含小于 pivot 的元素,另一个包含大于 pivot 的元素,然后递归地对这两个子数组进行快速排序。快速排序在平均情况下非常高效,时间复杂度为 O(n log n)。
/// This is a helper function for the sort routine.
template <typename _RandomAccessIterator, typename _Size, typename _Compare>
_GLIBCXX20_CONSTEXPR void
__introsort_loop(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Size __depth_limit, _Compare __comp) {
while (__last - __first > int(_S_threshold)) {
if (__depth_limit == 0) {
std::__partial_sort(__first, __last, __last, __comp);
return;
}
--__depth_limit;
_RandomAccessIterator __cut =
std::__unguarded_partition_pivot(__first, __last, __comp);
std::__introsort_loop(__cut, __last, __depth_limit, __comp);
__last = __cut;
}
}
// sort
template <typename _RandomAccessIterator, typename _Compare>
_GLIBCXX20_CONSTEXPR inline void __sort(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_Compare __comp) {
if (__first != __last) {
std::__introsort_loop(__first, __last, std::__lg(__last - __first) * 2,
__comp);
std::__final_insertion_sort(__first, __last, __comp);
}
}
内省排序:通过限制快速排序递归深度,避免其最坏情况的性能问题。递归深度的限制基于输入数组的大小,通常是对数组长度取对数然后乘以一个常数(在 GCC 实现中是 2 * log(len))。如果排序过程中递归深度超过了这个限制,算法会切换到堆排序。
/// This is a helper function for the sort routine.
template <typename _RandomAccessIterator, typename _Size, typename _Compare>
_GLIBCXX20_CONSTEXPR void
__introsort_loop(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Size __depth_limit, _Compare __comp) {
while (__last - __first > int(_S_threshold)) {
if (__depth_limit == 0) {
std::__partial_sort(__first, __last, __last, __comp);
return;
}
--__depth_limit;
_RandomAccessIterator __cut =
std::__unguarded_partition_pivot(__first, __last, __comp);
std::__introsort_loop(__cut, __last, __depth_limit, __comp);
__last = __cut;
}
}
堆排序:当快速排序的递归深度超过限制时,内省排序会切换到堆排序,保证最坏情况下的时间复杂度为 O(n log n)。堆排序不依赖于数据的初始排列,因此它的性能无论在最好、平均和最坏情况下都是稳定的。
template <typename _RandomAccessIterator, typename _Compare>
_GLIBCXX20_CONSTEXPR inline void
__partial_sort(_RandomAccessIterator __first, _RandomAccessIterator __middle,
_RandomAccessIterator __last, _Compare __comp) {
std::__heap_select(__first, __middle, __last, __comp);
std::__sort_heap(__first, __middle, __comp);
}
插入排序:最后,当数组的大小减小到一定程度时,内省排序会使用插入排序来处理小数组。插入排序在小数组上非常高效,尽管它的平均和最坏情况时间复杂度为 O(n^2),但在数据量小的情况下,这种复杂度不是问题。此外,插入排序是稳定的,可以保持等值元素的相对顺序。
/// This is a helper function for the sort routine.
template <typename _RandomAccessIterator, typename _Compare>
_GLIBCXX20_CONSTEXPR void __final_insertion_sort(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_Compare __comp) {
if (__last - __first > int(_S_threshold)) {
std::__insertion_sort(__first, __first + int(_S_threshold), __comp);
std::__unguarded_insertion_sort(__first + int(_S_threshold), __last,
__comp);
} else
std::__insertion_sort(__first, __last, __comp);
}
Reactor 和 Proactor 的区别?
#
回答重点 #
Reactor 和 Proactor 都是用于处理大量网络 IO 操作的编程模式。
它们的主要区别在于如何处理 IO 操作。
Reactor模式,程序会先注册一些事件处理器,监听需要处理的 IO 事件,例如socket读写事件。当这些事件发生时,事件处理程序会通知相应的事件处理器来处理该事件。这种方式通常使用同步 I/O 操作,即程序需要等待 IO 操作完成才能进行下一步操作。- 在
Proactor模式中,程序也会先注册一些事件处理器来监听需要处理的 IO 事件。但是与Reactor不同的是,Proactor使用异步 I/O 操作,即程序可以继续执行其他任务而不必等待 IO 操作完成。当 IO 操作完成后,事件处理程序会自动调用相关的回调函数来处理已经就绪的 IO 结果。
扩展知识 #
由于 Proactor 使用异步 I/O 操作,因此它比 Reactor 更适合处理大量数据或者需要进行复杂计算的场景。然而,它的实现可能会更加复杂,需要使用回调函数、协程或者异步框架等技术来支持。比如 asio。
操作系统面试题 #
什么是操作系统? #
操作系统是管理硬件和软件的一种应用程序。操作系统是运行在计算机上最重要的一种 软件,它管理计算机的资源和进程以及所有的硬件和软件。它为计算机硬件和软件提供了一种中间层,使应用软件和硬件进行分离,让我们无需关注硬件的实现,把关注点更多放在软件应用上。
通常情况下,计算机上会运行着许多应用程序,它们都需要对内存和 CPU 进行交互,操作系统的目的就是为了保证这些访问和交互能够准确无误的进行。
操作系统的主要功能 #
一般来说,现代操作系统主要提供下面几种功能:
进程管理: 进程管理的主要作用就是任务调度,在单核处理器下,操作系统会为每个进程分配一个任务,进程管理的工作十分简单;而在多核处理器下,操作系统除了要为进程分配任务外,还要解决处理器的调度、分配和回收等问题内存管理:内存管理主要是操作系统负责管理内存的分配、回收,在进程需要时分配内存以及在进程完成时回收内存,协调内存资源,通过合理的页面置换算法进行页面的换入换出设备管理:根据确定的设备分配原则对设备进行分配,使设备与主机能够并行工作,为用户提供良好的设备使用界面。文件管理:有效地管理文件的存储空间,合理地组织和管理文件系统,为文件访问和文件保护提供更有效的方法及手段。提供用户接口:操作系统提供了访问应用程序和硬件的接口,使用户能够通过应用程序发起系统调用从而控制硬件,实现想要的功能。
🌟 软件访问硬件的几种方式 #
软件访问硬件其实就是一种 I/O 操作,软件访问硬件的方式,也就是 I/O 操作的方式有哪些。
硬件在 I/O 上大致分为并行和串行,同时也对应串行接口和并行接口。
随着计算机技术的发展,I/O 控制方式也在不断发展。选择和衡量 I/O 控制方式有如下三条原则:
- 数据传送速度足够快,能满足用户的需求但又不丢失数据;
- 系统开销小,所需的处理控制程序少;
- 能充分发挥硬件资源的能力,使 I/O 设备尽可能忙,而 CPU 等待时间尽可能少。
根据以上控制原则,I/O 操作可以分为四类:
直接访问:直接访问由用户进程直接控制主存或 CPU 和外围设备之间的信息传送。直接程序控制方式又称为忙/等待方式。中断驱动:为了减少程序直接控制方式下 CPU 的等待时间以及提高系统的并行程度,系统引入了中断机制。中断机制引入后,外围设备仅当操作正常结束或异常结束时才向 CPU 发出中断请求。在 I/O 设备输入每个数据的过程中,由于无需 CPU 的干预,一定程度上实现了 CPU 与 I/O 设备的并行工作。
上述两种方法的特点都是以 CPU 为中心,数据传送通过一段程序来实现,软件的传送手段限制了数据传送的速度。接下来介绍的这两种 I/O 控制方式采用硬件的方法来显示 I/O 的控制
DMA 直接内存访问:为了进一步减少 CPU 对 I/O 操作的干预,防止因并行操作设备过多使 CPU 来不及处理或因速度不匹配而造成的数据丢失现象,引入了 DMA 控制方式。通道控制方式:通道是独立于 CPU 的专门负责输入输出控制的处理机,它控制设备与内存直接进行数据交换。有自己的通道指令,这些指令由 CPU 启动,并在操作结束时向 CPU 发出中断信号。
🌟 操作系统的主要目的是什么? #
操作系统是一种软件,它的主要目的有三种
- 管理计算机资源,这些资源包括 CPU、内存、磁盘驱动器、打印机等。
- 提供一种图形界面,就像我们前面描述的那样,它提供了用户和计算机之间的桥梁。
- 为其他软件提供服务,操作系统与软件进行交互,以便为其分配运行所需的任何必要资源。

操作系统的种类有哪些? #
常见的操作系统只有三种:Windows、macOS 和 Linux。
🌟 为什么 Linux 系统下的应用程序不能直接在 Windows 下运行? #
这是一个老生常谈的问题了,在这里给出具体的回答。
其中一点是因为 Linux 系统和 Windows 系统的格式不同,格式就是协议,就是在固定位置有意义的数据。Linux 下的可执行程序文件格式是 elf,可以使用 readelf 命令查看 elf 文件头。
而 Windows 下的可执行程序是 PE 格式,它是一种可移植的可执行文件。
还有一点是因为 Linux 系统和 Windows 系统的 API 不同,这个 API 指的就是操作系统的 API,Linux 中的 API 被称为 系统调用,是通过 int 0x80 这个软中断实现的。而 Windows 中的 API 是放在动态链接库文件中的,也就是 Windows 开发人员所说的 DLL ,这是一个库,里面包含代码和数据。Linux 中的可执行程序获得系统资源的方法和 Windows 不一样,所以显然是不能在 Windows 中运行的。
🌟什么是用户态?什么是内核态? #
内核态:又指管态、系统态,是操作系统管理程序执行时机器所处的状态。具有较高特权,能执行一切指令。
用户态:是用户程序执行时机器所处的状态,特权较低,只能执行规定内的指令,访问指定的部分。
总结:内核态特权高,可以横行霸道,拥有一切特权,执行指令,访问内存。用户态特权小,只能执行部分指令,访问部分内存。
另外用户不能直接调用内核态程序,只能通过中断,由中断系统将其转入操作系统内的相应程序。
特权指令:只能有操作系统内核部分使用,不允许用户直接使用的指令,I/0 指令。设置中断屏蔽指令、清内存指令,存储保护指令,设置时钟指令。
中断和异常 #
中断:又称为外中断,是系统正常功能的一部分,使系统停止当前运行的进程而执行其他进程。然后操作系统处理完该任务之后,再来处理中断前的命令。
异常:是由错误引起的,如文件损坏、进程越界等。
为什么称为陷入内核? #
如果把软件结构进行分层说明的话,应该是这个样子的,最外层是应用程序,里面是操作系统内核。
应用程序处于特权级 3,操作系统内核处于特权级 0 。如果用户程序想要访问操作系统资源时,会发起系统调用,陷入内核,这样 CPU 就进入了内核态,执行内核代码。至于为什么是陷入,我们看图,内核是一个凹陷的构造,有陷下去的感觉,所以称为陷入。
🌟 用户态和内核态是如何切换的? #
所有的用户进程都是运行在用户态的,但是我们上面也说了,用户程序的访问能力有限,一些比较重要的比如从硬盘读取数据,从键盘获取数据的操作则是内核态才能做的事情,而这些数据却又对用户程序来说非常重要。所以就涉及到两种模式下的转换,即用户态 -> 内核态 -> 用户态,而唯一能够做这些操作的只有 系统调用,而能够执行系统调用的就只有 操作系统。
一般用户态到内核态的转换我们都称之为 trap 进内核,也被称之为 陷阱指令(trap instruction)。
它们的工作流程如下:
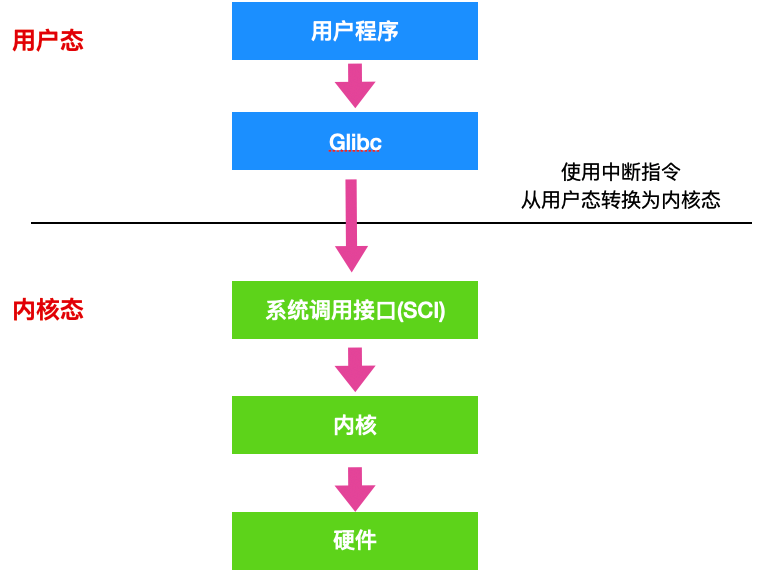
- 首先用户程序会调用
glibc库,glibc 是一个标准库,同时也是一套核心库,库中定义了很多关键 API。 - glibc 库知道针对不同体系结构调用
系统调用的正确方法,它会根据体系结构应用程序的二进制接口设置用户进程传递的参数,来准备系统调用。 - 然后,glibc 库调用
软件中断指令(SWI),这个指令通过更新CPSR寄存器将模式改为超级用户模式,然后跳转到地址0x08处。 - 到目前为止,整个过程仍处于用户态下,在执行 SWI 指令后,允许进程执行内核代码,MMU 现在允许内核虚拟内存访问
- 从地址 0x08 开始,进程执行加载并跳转到中断处理程序,这个程序就是 ARM 中的
vector_swi()。 - 在 vector_swi() 处,从 SWI 指令中提取系统调用号 SCNO,然后使用 SCNO 作为系统调用表
sys_call_table的索引,调转到系统调用函数。 - 执行系统调用完成后,将还原用户模式寄存器,然后再以用户模式执行。
关键概念对比 #
什么是内核? #
在计算机中,内核是一个计算机程序,它是操作系统的核心,可以控制操作系统中所有的内容。内核通常是在 boot loader 装载程序之前加载的第一个程序。
这里还需要了解一下什么是 boot loader。
boot loader 又被称为引导加载程序,能够将计算机的操作系统放入内存中。在电源通电或者计算机重启时,BIOS 会执行一些初始测试,然后将控制权转移到引导加载程序所在的主引导记录(MBR) 。
Linux 操作系统启动流程 #
什么是系统调用? #
介绍系统调用之前,我们先来了解一下用户态和系统态。
根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
- 用户态(user mode) : 用户态运行的进程或可以直接读取用户程序的数据。
- 系统态(kernel mode):可以简单的理解系统态运行的进程或程序几乎可以访问计算机的任何资源,不受限制。
说了用户态和系统态之后,那么什么是系统调用呢?
我们运行的程序基本都是运行在用户态,如果我们调用操作系统提供的系统态级别的子功能咋办呢?那就需要系统调用了!
也就是说在我们运行的用户程序中,凡是与系统态级别的资源有关的操作(如文件管理、进程控制、内存管理等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
这些系统调用按功能大致可分为如下几类:
- 设备管理。完成设备的请求或释放,以及设备启动等功能。
- 文件管理。完成文件的读、写、创建及删除等功能。
- 进程控制。完成进程的创建、撤销、阻塞及唤醒等功能。
- 进程通信。完成进程之间的消息传递或信号传递等功能。
- 内存管理。完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
进程管理篇 #
进程与线程 #
🌟什么是进程? #
标准定义:进程是一个具有一定独立功能的程序在一个数据集合上依次动态执行的过程。进程是一个正在执行程序的实例,包括程序计数器、寄存器和程序变量的当前值。
简单来说进程就是一个程序的执行流程,内部保存程序运行所需的资源。
在操作系统中可以有多个进程在运行,可对于 CPU 来说,同一时刻,一个 CPU 只能运行一个进程,但在某一时间段内,CPU 将这一时间段拆分成更短的时间片,CPU 不停的在各个进程间游走,这就给人一种并行的错觉,像 CPU 可以同时运行多个进程一样,这就是伪并行。
主要特点 #
- 动态性:进程是程序的一次执行过程,它是动态地产生、变化和消亡的。一个程序可以多次被执行,每次执行都会创建一个新的进程。
- 独立性:每个进程都有自己独立的地址空间,不同进程之间的内存空间是相互隔离的。这意味着一个进程中的错误不会影响到其他进程。
- 并发性:在多道程序设计系统中,多个进程可以同时存在并执行。操作系统通过时间片轮转等调度算法,在不同进程之间切换执行,从而实现并发执行。
- 制约性:因访问共享资源或进程间同步而产生制约。
组成部分 #
- 程序代码:进程执行的指令序列,是进程的静态部分。
- 数据:进程在执行过程中所使用的变量、常量、数组等数据,也是进程的静态部分。
- 进程控制块(PCB):是操作系统为了管理进程而设置的数据结构,包含了进程的标识信息、状态信息、资源信息等。PCB 是进程存在的唯一标志,操作系统通过 PCB 来对进程进行管理和调度。
重要作用 #
- 资源分配:操作系统通过为进程分配资源,如内存、CPU 时间、文件等,来实现对计算机系统资源的有效管理和利用。
- 提高系统效率:通过并发执行多个进程,可以充分利用计算机的硬件资源,提高系统的效率和吞吐量。
- 实现多任务处理:在现代操作系统中,用户可以同时运行多个应用程序,每个应用程序都是一个进程。操作系统通过对进程的管理和调度,实现了多任务处理,提高了用户的工作效率。
进程和程序有什么联系? #
一个进程是某种类型的一个活动,它有程序、输入、输出以及状态。单个处理器可以被若干进程共享,它使用某种调度算法决定何时停止一个进程的工作,并转而为另一个进程提供服务。
- 程序是产生进程的基础
- 程序的每次运行产生不同的进程
- 进程是程序功能的体现
- 通过多次执行,一个程序可对应多个进程;通过调用关系,一个进程可包括多个程序
🌟进程和程序的区别? #
- 进程是动态的,程序是静态的:程序是有序代码的集合,进程是程序的执行。
- 进程是暂时的,程序是永久的:进程是一个状态变化的过程,程序可长久保存。
- 进程和程序的组成不同:进程的组成包括程序、数据和进程控制块(进程状态信息)。
如何创建进程? #
有什么事件会触发进程的创建呢?
- 系统初始化:当启动操作系统时,通常会创建很多进程,有些是同用户交互并替他们完成工作的前台进程,其它的都是后台进程,后台进程和特定用户没有关系,但也提供某些专门的功能,例如接收邮件等,这种功能的进程也称为守护进程。计划任务是个典型的守护进程,它每分钟运行一次来检查是否有工作需要它完成。如果有工作要做,它就会完成此工作,然后进入休眠状态,直到下一次检查时刻的到来。
- 正在运行的程序执行了创建进程的系统调用:在一个进程中又创建了一个新的进程,这种情况很常见。
- 用户请求创建一个新进程:这种情况相信每个人都见过,用电脑时双击某个应用图标,就会有至少一个进程被创建。
- 一个批处理作业的初始化:这种情形不常见,仅在大型机的批处理系统中应用,用户在这种系统中提交批处理作业,在操作系统认为有资源可运行另一个作业时,它创建一个新的进程,并运行其输入队列中的下一个作业。
归根到底:在 UNIX 系统中,只有 fork 系统调用才可以创建新进程,使用方式如下:
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t id = fork();
if (id < 0) {
perror("fork\n");
} else if (id == 0) { // 子进程
printf("子进程\n");
} else { // 父进程
printf("父进程\n");
}
return 0;
}
进程创建之后,父子进程都有各自不同的地址空间,其中一个进程在其地址空间的修改对另一个进程不可见。子进程的初始化空间是父进程的一个副本,这里涉及两个不同地址空间,不可写的内存区是共享的,某些 UNIX 的实现使程序正文在两者间共享,因为它是不可修改的。
进程为何终止? #
有什么事件会触发进程的终止呢?
- 正常退出(自愿):进程完成了工作正常终止,UNIX 中退出进程的系统调用是 exit。
- 出错退出(自愿):进程发现了错误而退出。可以看如下代码:
#include <stdio.h>
#include <stdlib.h>
void Func() {
if (error) { // 有错误就退出程序
exit(1);
}
}
int main() {
Func();
}
- 严重错误(非自愿):进程发生了严重的错误而不得不退出,通常是程序的错误导致,例如执行了一条非法指令,引用不存在的内存,或者除数是 0 等,出现这些错误时进程默认会退出。而有些时候如果用户想自行处理某种类型的错误,发生不同类型错误时进程会收到不同类型的信号,用户注册处理不同信号的函数即可。
- 被其它进程杀死(非自愿):其它进程执行 kill 系统调用通知操作系统杀死某个进程。
🌟操作系统如何进行进程管理? #
这里就不得不提到一个数据结构:进程控制块(PCB),操作系统为每个进程都维护一个 PCB,用来保存与该进程有关的各种状态信息。进程可以抽象理解为就是一个 PCB,PCB 是进程存在的唯一标志,操作系统用 PCB 来描述进程的基本情况以及运行变化的过程,进程的任何状态变化都会通过 PCB 来体现。
PCB 包含进程状态的重要信息,包括程序计数器、堆栈指针、内存分配状况、所打开文件的状态、账号和调度信息,以及其它在进程由运行态转换到就绪态或阻塞态时必须保存的信息,从而保证该进程随后能再次启动,就像从未中断过一样。
提到进程管理,有一个概念我们必须要知道,就是中断向量,中断向量是指中断服务程序的入口地址。一个进程在执行过程中可能会被中断无数次,但是每次中断后,被中断的进程都要返回到与中断发生前完全相同的状态。
中断发生后操作系统底层做了什么?
- 硬件压入堆栈程序计数器等;
- 硬件从中断向量装入新的程序计数器;
- 汇编语言过程保存寄存器值;
- 汇编语言过程设置新的堆栈;
- C 中断服务例程运行(典型的读和缓冲输入);
- 调度程序决定下一个将运行的进程;
- C 过程返回到汇编代码;
- 汇编语言过程开始运行新的当前进程。
📚 关键补充说明 #
// Linux 中 PCB 的简化结构(task_struct 部分字段)
struct task_struct {
volatile long state; // 进程状态(-1不可运行, 0可运行, >0已停止)
struct mm_struct *mm; // 内存管理信息
pid_t pid; // 进程标识符
struct files_struct *files; // 打开的文件表
struct thread_struct thread; // CPU 寄存器状态
// ... 其他 100+ 字段
};
为什么说 PCB(进程控制块)是进程存在的唯一标识? #
PCB(进程控制块)是操作系统中用来管理和控制进程的数据结构,其中包含了进程的各种信息,如进程状态、程序计数器、寄存器、内存分配情况、打开文件列表等。由于 PCB 包含了进程的所有关键信息,因此可以说 PCB 是进程存在的唯一标识。
主要存储这些信息:
进程标识信息:如本进程的标识,本进程的父进程标识,用户标识等。
处理机状态信息保护区:用于保存进程的运行现场信息:
- 用户可见寄存器:用户程序可以使用的数据,地址等寄存器
- 控制和状态寄存器:程序计数器,程序状态字
- 栈指针:过程调用、系统调用、中断处理和返回时需要用到它
进程控制信息:
- 调度和状态信息:用于操作系统调度进程使用
- 进程间通信信息:为支持进程间与通信相关的各种标识、信号、信件等,这些信息存在接收方的进程控制块中
- 存储管理信息:包含有指向本进程映像存储空间的数据结构
- 进程所用资源:说明由进程打开使用的系统资源,如打开的文件等
- 有关数据结构连接信息:进程可以连接到一个进程队列中,或连接到相关的其他进程的 PCB
每个进程都有一个独特的 PCB,通过 PCB 可以唯一地标识和管理每个进程。当操作系统需要对一个进程进行调度、切换或终止时,就需要通过该进程对应的 PCB 来获取和修改进程的相关信息。
因此,可以说 PCB 是进程存在的唯一标识,因为它包含了进程的所有信息,并且用于操作系统对进程进行管理和控制。
📌 进程控制块 (PCB) 核心结构 #
🌟进程的生命周期 #
进程创建 #
创建进程有三个主要事件:
- 系统初始化
- 用户请求创建一个新进程
- 一个正在运行的进程执行创建进程的系统调用
进程运行 #
内核选择一个就绪的进程,让它占用处理机并运行,这里就涉及到了进程的调度策略,选择哪个进程调度?为什么选择调度这个进程呢?
进程等待 #
在以下情况下进程会等待(阻塞):
- 请求并等待系统服务,无法马上完成
- 启动某种操作,无法马上完成
- 需要的数据没有到达。
进程唤醒 #
进程只能被别的进程或操作系统唤醒,唤醒进程的原因有:
- 被阻塞进程需要的资源可被满足
- 被阻塞进程等待的事件到达
- 将该进程的 PCB 插入到就绪队列
进程结束 #
在以下四种情况下进程会结束:
- 自愿型正常退出
- 自愿型错误退出
- 强制型致命错误退出
- 强制型被其它进程杀死退出
进程的状态与转换 #
不同系统设置的进程状态是不同的,多数系统中的进程在生命结束前有三种基本状态,进程只会处于三种基本状态之一:
- 运行状态:进程正在处理机上运行时就处在运行状态,该时刻进程时钟占用着 CPU;
- 就绪状态:万事俱备,只欠东风,进程已经获得了除处理机之外的一切所需资源,一旦得到处理机就可以运行;就绪态中的进程其实可以运行,但因为其它进程正在占用着 CPU 而暂时停止运行;
- 等待状态(阻塞状态):进程正在等待某一事件而暂停运行,等待某个资源或者等待输入输出完成。除非某种外部事件发生,否则阻塞态的进程不能运行;
进程状态变化图如下:
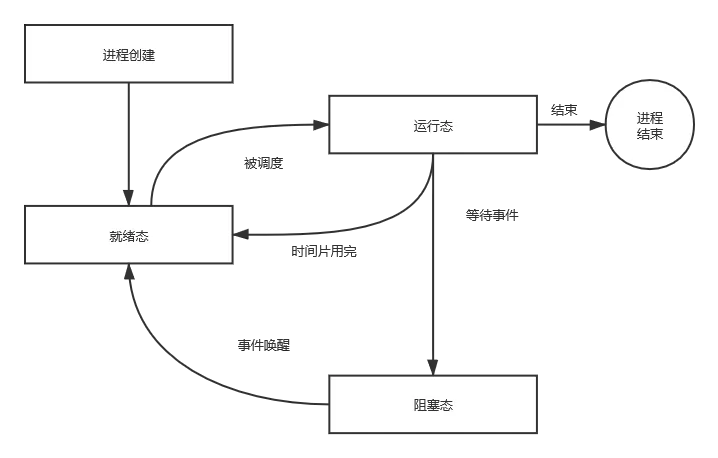
在操作系统发现进程不能继续运行下去时,进程因为等待输入而被阻塞,进程从运行态转换到阻塞态!
调度程序选择了另一个进程执行时,当前程序就会从运行态转换到就绪态!
被调度程序选择的程序会从就绪态转换到运行态!
当阻塞态的进程等待的一个外部事件发生时,就会从阻塞态转换到就绪态,此时如果没有其他进程运行时,则立刻从就绪态转换到运行态!
有些与进程管理相关的系统调用有必要了解一下:
pid=fork(); // 创建一个与父进程一样的子进程
pid=waitpid(); // 等待子进程终止
s=execve(); // 替换进程的核心映像
exit(); // 终止进程运行并返回状态值
s=sigaction(); // 定义信号处理的动作
s=sigprocmask(); // 检查或更换信号掩码
s=sigpending(); // 获得阻塞信号集合
s=sigsuspend(); // 替换信号掩码或挂起进程
alarm(); // 设置定时器
pause(); // 挂起调用程序直到下一个信号出现
⚙️ 进程状态转换对比 #
什么是进程挂起?为什么会出现进程挂起? #
进程挂起就是为了合理且充分的利用系统资源,把一个进程从内存转到外存。进程在挂起状态时,意味着进程没有占用内存空间,处在挂起状态的进程映射在磁盘上。进程挂起通常有两种状态:
- 阻塞挂起状态:进程在外存并等待某事件的出现;
- 就绪挂起状态:进程在外存,但只要进入内存即可运行。
有什么与进程挂起相关的状态转换?
进程挂起可能有以下几种情况:
- 阻塞到阻塞挂起:没有进程处于就绪状态或就绪进程要求更多内存资源时,会进行这种转换,以提交新进程或运行就绪进程;
- 就绪到就绪挂起:当有高优先级阻塞进程或低优先级就绪进程时,系统会选择挂起低优先级就绪进程;
- 运行到就绪挂起:对于抢占式分时系统,当有高优先级阻塞挂起进程因事件出现而进入就绪挂起时,系统可能会把运行进程转到就绪挂起状态;
- 阻塞挂起到就绪挂起:当有阻塞挂起进程有相关事件出现时,系统会把阻塞挂起进程转换为就绪挂起进程。
有进程挂起那就有进程解挂:指一个进程从外存转到内存,相关状态有:
- 就绪挂起到就绪:没有就绪进程或就绪挂起进程优先级高于就绪进程时,就会进行这种转换;
- 阻塞挂起到阻塞:当一个进程释放足够内存时,系统会把一个高优先级阻塞挂起进程转换为阻塞进程。
🔄 中断处理流程(以 Linux 为例) #
🌟什么是线程? #
线程是进程当中的一条执行流程,这几乎就是进程的定义,一个进程内可以有多个子执行流程,即线程。可以从两个方面重新理解进程:
- 从资源组合的角度:进程把一组相关的资源组合起来,构成一个资源平台环境,包括地址空间(代码段、数据段),打开的文件等各种资源
- 从运行的角度:代码在这个资源平台上的执行流程,然而线程貌似也是这样,但是进程比线程多了资源内容列表样式:那就有一个公式:进程 = 线程 + 共享资源
为什么使用线程? #
因为要并发编程,在许多情形中同时发生着许多活动,而某些活动有时候会被阻塞,通过将这些活动分解成可以准并行运行的多个顺序流程是必须的,而如果使用多进程方式进行并发编程,进程间的通信也很复杂,并且维护进程的系统开销较大:创建进程时分配资源建立 PCB,撤销进程时回收资源撤销 PCB,进程切换时保存当前进程的状态信息。所以为了使并发编程的开销尽量小,所以引入多线程编程,可以并发执行也可以共享相同的地址空间。并行实体拥有共享同一地址空间和所有可用数据的能力,这是多进程模型所不具备的能力。
使用线程有如下优点:
- 可以多个线程存在于同一个进程中
- 各个线程之间可以并发的执行
- 各个线程之间可以共享地址空间和文件等资源
- 线程比进程更轻量级,创建线程撤销线程比创建撤销进程要快的多,在许多系统中,创建一个线程速度是创建一个进程速度的 10-100 倍。
- 如果多个线程是 CPU 密集型的,并不能很好的获得更好的性能,但如果多个线程是 IO 密集型的,线程存在着大量的计算和大量的 IO 处理,有多个线程允许这些活动彼此重叠进行,从而会加快整体程序的执行速度。
但也有缺点:
- 一旦一个线程崩溃,会导致其所属进程的所有线程崩溃。
- 由于各个线程共享相同的地址空间,那么读写数据可能会导致竞争关系,因此对同一块数据的读写需要采取某些同步机制来避免线程不安全问题。
什么时候用进程?什么时候用线程? #
进程是资源分配单位,线程是 CPU 调度单位;
进程拥有一个完整的资源平台,而线程只独享必不可少的资源,如寄存器和栈;
线程同样具有就绪阻塞和执行三种基本状态,同样具有状态之间的转换关系;
线程能减少并发执行的时间和空间开销:
- 线程的创建时间比进程短
- 线程的终止时间比进程短
- 同一进程内的线程切换时间比进程短
- 由于同一进程的各线程间共享内存和文件资源,可直接进行不通过内核的通信
结论:可以在强调性能时候使用线程,如果追求更好的容错性可以考虑使用多进程,google 浏览器据说就是用的多进程编程。在多 CPU 系统中,多线程是有益的,在这样的系统中,通常情况下可以做到真正的并行。
进程和线程的比较 #
我们主要从调度,拥有资源 ,并发性,系统开销等方面对其进行比较:
- 调度:在传统的操作系统中,拥有资源和独立调度的单位都是进程,引入线程之后,调度的最小单位就变成了线程,但是拥有资源的最小单位还是进程,另外在同一个进程中,线程的切换不会影响进程,但是不同的进程中的切换则会引起进程切换。
- 拥有资源:不论是传统的操作系统,还是设有线程的操作系统,进程都是资源分配的最小单位。
- 并发性:在引入线程的操作系统中,不仅进程之间可以并发,线程之间也可以并发,这使得操作系统具有更好的并发性。
- 系统开销:创建进程或撤销进程的同时,系统都要为之分配或回收资源,在进行进程切换时,涉及当前进程 CPU 环境的保存和新环境的设置,线程切换时,只需保存和设置少量寄存器内容,因此开销很小。总的来说就是线程间切换的开销更小,同步和通信很容易实现。
线程是如何实现的? #
线程的实现可分为用户线程和内核线程:
用户线程 #
在用户空间实现的线程机制,它不依赖于操作系统的内核,由一组用户级的线程库函数来完成线程的管理,包括进程的创建终止同步和调度等。
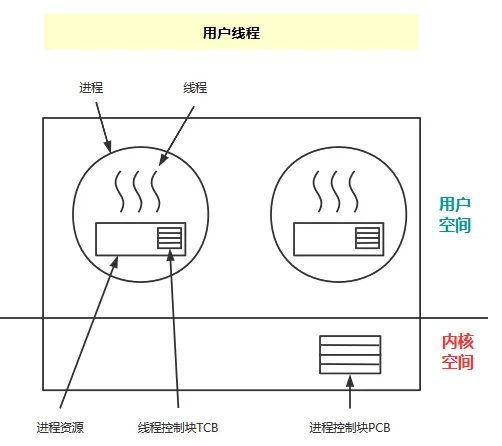
用户线程有如下优点:
- 由于用户线程的维护由相应进程来完成(通过线程库函数),不需要操作系统内核了解内核了解用户线程的存在,可用于不支持线程技术的多进程操作系统。
- 每个进程都需要它自己私有的线程控制块列表,用来跟踪记录它的各个线程的状态信息(PC,栈指针,寄存器),TCB 由线程库函数来维护;
- 用户线程的切换也是由线程库函数来完成,无需用户态/核心态切换,所以速度特别快;
- 允许每个进程拥有自定义的线程调度算法;
但用户线程也有缺点:
- 阻塞性的系统调用如何实现?如果一个线程发起系统调用而阻塞,则整个进程在等待。
- 当一个线程开始运行后,除非它主动交出 CPU 的使用权,否则它所在进程当中的其它线程将无法运行;
- 由于时间片分配给进程,与其它进程比,在多线程执行时,每个线程得到的时间片较少,执行会较慢
内核线程 #
是指在操作系统的内核中实现的一种线程机制,由操作系统的内核来完成线程的创建终止和管理。

特点:
- 在支持内核线程的操作系统中,由内核来维护进程和线程的上下文信息(PCB TCB);
- 线程的创建终止和切换都是通过系统调用内核函数的方式来进行,由内核来完成,因此系统开销较大;
- 在一个进程当中,如果某个内核线程发起系统调用而被阻塞,并不会影响其它内核线程的运行;
- 时间片分配给线程,多线程的进程获得更多 CPU 时间;
注意:
由于在内核中创建或撤销线程的代价比较大,某些系统采取复用的方式回收线程,当某个线程被撤销时,就把它标记不可运行,但是内核数据结构没有受到任何影响,如果后续又需要创建一个新线程时,就重新启动被标记为不可运行的旧线程,从而节省一些开销。
尽管使用内核线程可以解决很多问题,但还有些问题,例如:当一个多线程的进程创建一个新的进程时会发生什么?新进程是拥有与原进程相同数量的线程还是只有一个线程?在很多情况下,最好的选择取决于进程计划下一步做什么?如果它要调用 exec 启动一个新程序,或许一个线程正合适,但如果它继续运行,那么最好复制所有的线程。
轻量级进程 #
它是内核支持的用户线程模型,一个进程可以有多个轻量级进程,每个轻量级进程由一个单独的内核线程来支持。
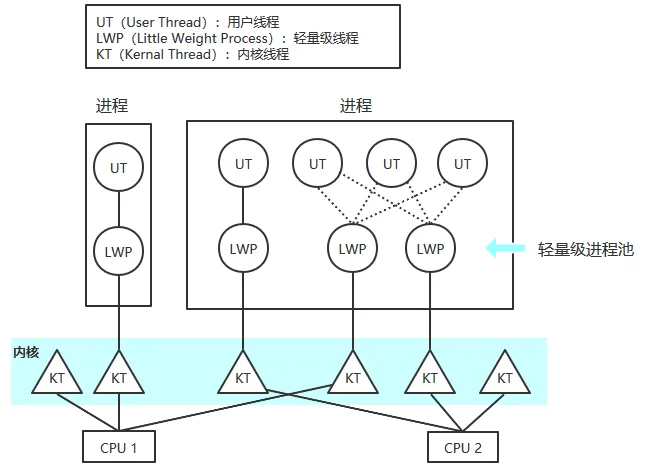
在 Linux 下是没有真正的线程的,它所谓的线程其实就是使用进程来实现的,就是所谓的轻量级进程,其实就是进程,都是通过 clone 接口调用创建的,只不过两者传递的参数不同,通过参数决定子进程和父进程共享的资源种类和数量,进而有了普通进程和轻量级进程的区别。
🧵 线程实现方式对比 #
什么是僵尸进程 #
僵尸进程是已完成且处于终止状态,但在进程表中却仍然存在的进程。僵尸进程通常发生在父子关系的进程中,由于父进程仍需要读取其子进程的退出状态所造成的。
进程切换 #
进程切换的速度是远小于线程切换的。举个不太恰当的例子,我们如果把进程比作房子,线程比作卧室的话,线程切换则是在每个卧室之间,来回穿梭,不用更换衣物,鞋子,但是我们如果要去邻居家(另一个进程)那么则需要更换衣服鞋子,这就是线程切换和进程切换。
进程切换为什么慢?
这就需要说到虚拟地址的地方了,因为每个进程都有自己的虚拟地址空间,然后线程共用当前进程的虚拟空间,所以进程切换需要虚拟地址空间的切换。这个过程是比较慢的。
另外进程通过查找页表,将虚拟空间映射到物理地址空间。这个过程是比较慢的,所以通常使用 Cache 来保存那些经常被查找的地址映射,然后进程切换的话,也会导致页表的切换,进而导致 Cache 失效,命中率降低,进而就会导致程序运行变慢。
协程 #
协程又叫微线程。
在有大量 IO 操作业务的情况下,考虑采用协程替换线程,可以到达很好的效果,一是降低了系统内存,二是减少了系统切换开销,因此系统的性能也会提升。
协程多用于异步 I/O,这样性能最好,阻塞 I/O 不能完全发挥出优势。
我们可以把协程理解成用户态的线程,操作系统不知道协程的存在,所以协程切换时不需要由操作系统控制,可以由自己控制,这样就节省了操作系统资源。
🌟什么是上下文切换? #
上下文切换指的是操作系统停止当前运行进程(从运行状态改变成其它状态)并且调度其它进程(就绪态转变成运行状态)。操作系统必须在切换之前存储许多部分的进程上下文,必须能够在之后恢复他们,所以进程不能显示它曾经被暂停过,同时切换上下文这个过程必须快速,因为上下文切换操作是非常频繁的。那上下文指的是什么呢?指的是任务所有共享资源的工作现场,每一个共享资源都有一个工作现场,包括用于处理函数调用、局部变量分配以及工作现场保护的栈顶指针,和用于指令执行等功能的各种寄存器。
注意:这里所说的进程切换导致上下文切换其实不太准确,准确的说应该是任务的切换导致上下文切换,这里的任务可以是进程也可以是线程,准确的说线程才是 CPU 调度的基本单位,但是因为各个资料都这么解释上下文切换,所以上面也暂时这么介绍,只要心里有这个概念就好。
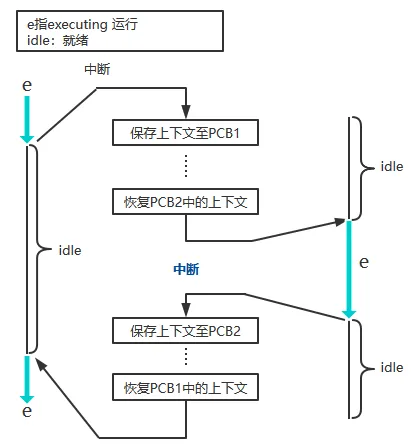
上下文切换的过程 #
- 挂起一个进程,将这个进程在 CPU 中的状态(上下文信息)存储于内存的 PCB 中。
- 在 PCB 中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复。
- 跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行)并恢复该进程
📌 核心概念对比 #
💡 上下文切换的详细步骤 #
为什么进程上下文切换比线程上下文切换代价高? #
原文:https://zwmst.com/1322.html
进程切换分两步:
- 切换页目录以使用新的地址空间
- 切换内核栈和硬件上下文
对于 linux 来说,线程和进程的最大区别就在于地址空间,对于线程切换,第 1 步是不需要做 的,第 2 是进程和线程切换都要做的
切换的性能消耗:
线程上下文切换和进程上下文切换一个最主要的区别是线程的切换虚拟内存空间依然是相同 的,但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。内核 的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出
另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下 文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚拟 内存空间的时候,处理的页表缓冲(processor’s Translation Lookaside Buffer (TLB))或 者相当的神马东西会被全部刷新,这将导致内存的访问在一段时间内相当的低效。但是在线程 的切换中,不会出现这个问题。
🖥️ 进程 vs 线程上下文切换代价对比 #
守护、僵尸、孤儿进程的概念 #
- 守护进程:运行在后台的一种特殊进程,独立于控制终端并周期性地执行某些任务。
- 僵尸进程:一个进程 fork 子进程,子进程退出,而父进程没有 wait/waitpid 子进程,那么子 进程的进程描述符仍保存在系统中,这样的进程称为僵尸进程。
- 孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,这些子进程称为孤儿进程。 (孤儿进程将由 init 进程收养并对它们完成状态收集工作)
🌟进程通信与线程通信 #
进程通信 #
进程通信,是指进程之间的信息交换(信息量少则一个状态或数值,多者则是成千上万个字 节)。因此,对于用信号量进行的进程间的互斥和同步,由于其所交换的信息量少而被归结为低级通信。
高级进程通信指:用户可以利用操作系统所提供的一组通信命令传送大量数据的一种通信 方式。操作系统隐藏了进程通信的实现细节。或者说,通信过程对用户是透明的
高级通信机制可归结为三大类:
共享存储器系统(存储器中划分的共享存储区);实际操作中对应的是“剪贴板”(剪贴板实际 上是系统维护管理的一块内存区域)的通信方式,比如举例如下:word 进程按下 ctrl+c,在 ppt 进程按下 ctrl+v,即完成了 word 进程和 ppt 进程之间的通信,复制时将数据放入到剪贴 板,粘贴时从剪贴板中取出数据,然后显示在 ppt 窗口上
消息传递系统(进程间的数据交换以消息(message)为单位,当今最流行的微内核操作系统 中,微内核与服务器之间的通信,无一例外地都采用了消息传递机制。应用举例:邮槽(MailSlot)是基于广播通信体系设计出来的,它采用无连接的不可靠的数据传输。邮槽是一 种单向通信机制,创建邮槽的服务器进程读取数据,打开邮槽的客户机进程写入数据
管道通信系统(管道即:连接读写进程以实现他们之间通信的共享文件(pipe 文件,类似先进 先出的队列,由一个进程写,另一进程读))。实际操作中,管道分为:匿名管道、命名管道。匿名管道是一个未命名的、单向管道,通过父进程和一个子进程之间传输数据。匿名管道 只能实现本地机器上两个进程之间的通信,而不能实现跨网络的通信。命名管道不仅可以在本 机上实现两个进程间的通信,还可以跨网络实现两个进程间的通信。
- 管道:管道是单向的、先进先出的、无结构的、固定大小的字节流,它把一个进程的标准输出 和另一个进程的标准输入连接在一起。写进程在管道的尾端写入数据,读进程在管道的道端读 出数据。数据读出后将从管道中移走,其它读进程都不能再读到这些数据。管道提供了简单的 流控制机制。进程试图读空管道时,在有数据写入管道前,进程将一直阻塞。同样地,管道已 经满时,进程再试图写管道,在其它进程从管道中移走数据之前,写进程将一直阻塞。
- 信号量:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机 制,防止某进程正在访问共享资源时,其它进程也访问该资源。因此,主要作为进程间以及同 一进程内不同线程之间的同步手段
- 消息队列:是一个在系统内核中用来保存消 息的队列,它在系统内核中是以消息链表的形式出 现的。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺 点
- 共享内存:共享内存允许两个或多个进程访问同一个逻辑内存。这一段内存可以被两个或两个 以上的进程映射至自身的地址空间中,一个进程写入共享内存的信息,可以被其他使用这个共 享内存的进程,通过一个简单的内存读取读出,从而实现了进程间的通信。如果某个进程向共 享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程。共享内 存是最快的 IPC 方式,它是针对其它进程间通信方式运行效率低而专门设计的。它往往与其它 通信机制(如信号量)配合使用,来实现进程间的同步和通信
- 套接字:套接字也是一种进程间通信机制,与其它通信机制不同的是,它可用于不同机器间的进程通信。
由于各个进程不共享相同的地址空间,任何一个进程的全局变量在另一个进程中都不可见,所以如果想要在进程之间传递数据就需要通过内核,在内核中开辟出一块区域,该区域对多个进程都可见,即可用于进程间通信。有读者可能有疑问了,文件方式也是进程间通信啊,也要在内核开辟区域吗?这里说的内核区域其实是一段缓冲区,文件方式传输数据也有内核缓冲区的参与(零拷贝除外)。
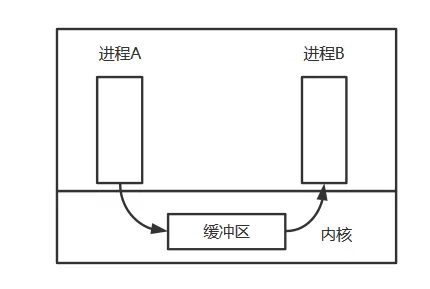
进程通信就是指进程间的信息交换,有多种进程间通信的方式:
- 管道
- 消息队列
- 共享内存
- 信号量
- 信号
- socket
🔄 进程通信 vs 线程通信机制对比 #
📌 通信方式分类 #
📊 进程通信方式详解 #
⚙️ 线程同步机制 #
管道 #
ps auxf | grep mysql
中间的 | 就是管道,管道分为 匿名管道 和 命名管道。
匿名管道 #
匿名管道就是 pipe,pipe 只能在父子进程间通信,而且数据只能单向流动(半双工通信)。
使用方式:
- 父进程创建管道,会得到两个文件描述符,分别指向管道的两端;
- 父进程创建子进程,从而子进程也有两个文件描述符指向同一管道;
- 父进程可写数据到管道,子进程就可从管道中读出数据,从而实现进程间通信,下面的示例代码中通过 pipe 实现了每秒钟父进程向子进程都发送消息的功能。
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main() {
int _pipe[2];
int ret = pipe(_pipe);
if (ret < 0) {
perror("pipe\n");
}
pid_t id = fork();
if (id < 0) {
perror("fork\n");
} else if (id == 0) { // 子进程
close(_pipe[1]);
int j = 0;
char _mesg[100];
while (j < 100) {
memset(_mesg, '\0', sizeof(_mesg));
read(_pipe[0], _mesg, sizeof(_mesg));
printf("%s\n", _mesg);
j++;
}
} else { // 父进程
close(_pipe[0]);
int i = 0;
char *mesg = NULL;
while (i < 100) {
mesg = "父进程来写消息了";
write(_pipe[1], mesg, strlen(mesg) + 1);
sleep(1);
++i;
}
}
return 0;
}
我们平时也经常使用关于管道的命令行:
ls | less
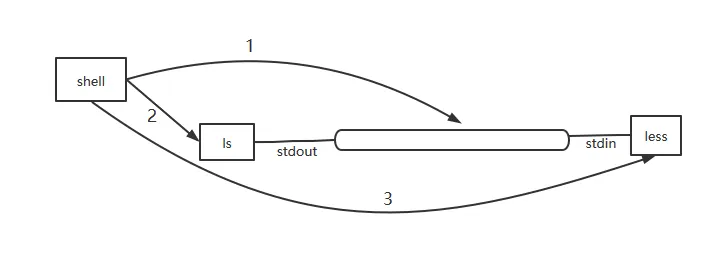
- 创建管道
- 为 ls 创建一个进程,设置 stdout 为管理写端
- 为 less 创建一个进程,设置 stdin 为管道读端
高级管道 #
通过 popen 将另一个程序当作一个新的进程在当前进程中启动,它算作当前进程的子进程,高级管道只能用在有亲缘关系的进程间通信,这种亲缘关系通常指父子进程,下面的 GetCmdResult 函数可以获取某个 Linux 命令执行的结果,实现方式就是通过 popen。
std::string GetCmdResult(const std::string &cmd, int max_size = 10240) {
char *data = (char *)malloc(max_size);
if (data == NULL) {
return std::string("malloc fail");
}
memset(data, 0, max_size);
const int max_buffer = 256;
char buffer[max_buffer];
// 将标准错误重定向到标准输出
FILE *fdp = popen((cmd + " 2>&1").c_str(), "r");
int data_len = 0;
if (fdp) {
while (!feof(fdp)) {
if (fgets(buffer, max_buffer, fdp)) {
int len = strlen(buffer);
if (data_len + len > max_size) {
cout << "data size larger than " << max_size;
break;
}
memcpy(data + data_len, buffer, len);
data_len += len;
}
}
pclose(fdp);
}
std::string ret(data, data_len);
free(data);
return ret;
}
命名管道 #
有名字,可以双向传输,可以在非亲缘关系的进程间传输。
匿名管道有个缺点就是通信的进程一定要有亲缘关系,而命名管道就不需要这种限制。
命名管道其实就是一种特殊类型的文件,所谓的命名其实就是文件名,文件对各个进程都可见,通过命名管道创建好特殊文件后,就可以实现进程间通信。
可以通过 mkfifo 创建一个特殊的类型的文件,参数读者看名字应该就了解,一个是文件名,一个是文件的读写权限:
int mkfifo(const char* filename, mode_t mode);
当返回值为 0 时,表示该命名管道创建成功,至于如何通信,其实就是个读写文件的问题!
管道的优点:方便,可以传输大量数据。
管道的缺点:效率相对于共享内存来说较低。
消息队列 #
队列想必大家都知道,像 FIFO 一样,这里可以有多个进程写入数据,也可以有多个进程从队列里读出数据,但消息队列有一点比 FIFO 还更高级,它读消息不一定要使用先进先出的顺序,每个消息可以赋予类型,可以按消息的类型读取,不是指定类型的数据还存在队列中。本质上 MessageQueue 是存放在内核中的消息链表,每个消息队列链表会由消息队列标识符表示,这个消息队列存于内核中,只有主动的删除该消息队列或者内核重启时,消息队列才会被删除。
在 Linux 中消息队列相关的函数调用如下:
// 创建和访问一个消息队列
int msgget(key_t, key, int msgflg);
// 用来把消息添加到消息队列中
int msgsend(int msgid, const void *msg_ptr, size_t msg_sz, int msgflg);
// msg_ptr是结构体数据的指针,结构第一个字段要有个类型:struct Msg {
long int message_type;
// 想要传输的数据
};
// 从消息队列中获取消息
int msgrcv(int msgid, void *msg_ptr, size_t msg_st, long int msgtype, int msgflg);
// 用来控制消息队列,不同的command参数有不同的控制方式
int msgctl(int msgid, int command, struct msgid_ds *buf);
示例代码如下:
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/msg.h>
#include <chrono>
#include <iostream>
#include <thread>
using namespace std;
#define BUFFER_SIZ 20
typedef struct {
long int msg_type;
char text[BUFFER_SIZ];
} MsgWrapper;
void Receive() {
MsgWrapper data;
long int msgtype = 2;
int msgid = msgget((key_t)1024, 0666 | IPC_CREAT);
if (msgid == -1) {
cout << "msgget error \n";
return;
}
while (true) {
if (msgrcv(msgid, (void *)&data, BUFFER_SIZ, msgtype, 0) == -1) {
cout << "error " << errno << endl;
}
cout << "read data " << data.text << endl;
if (strlen(data.text) > 6) { // 发送超过6个字符的数据,结束
break;
}
}
if (msgctl(msgid, IPC_RMID, 0) == -1) {
cout << "msgctl error \n";
}
cout << "Receive ok \n";
}
void Send() {
MsgWrapper data;
long int msgtype = 2;
int msgid = msgget((key_t)1024, 0666 | IPC_CREAT);
if (msgid == -1) {
cout << "msgget error \n";
return;
}
data.msg_type = msgtype;
for (int i = 0; i < 10; ++i) {
memset(data.text, 0, BUFFER_SIZ);
char a = 'a' + i;
memset(data.text, a, 1);
if (msgsnd(msgid, (void *)&data, BUFFER_SIZ, 0) == -1) {
cout << "msgsnd error \n";
return;
}
std::this_thread::sleep_for(std::chrono::seconds(1));
}
memcpy(data.text, "1234567", 7);
if (msgsnd(msgid, (void *)&data, BUFFER_SIZ, 0) == -1) {
cout << "msgsnd error \n";
return;
}
}
int main() {
std::thread r(Receive);
r.detach();
std::thread s(Send);
s.detach();
std::this_thread::sleep_for(std::chrono::seconds(20));
return 0;
}
输出:root@iZuf64idor3ej648ciairaZ:~## ./a.out
read data a
read data b
read data c
read data d
read data e
read data f
read data g
read data h
read data i
read data j
read data 1234567
Receive ok
代码中为了演示方便使用消息队列进行的线程间通信,该代码同样用于进程间通信,消息队列的实现依赖于内核的支持,上述代码可能在某些系统(WSL)上不能运行,在正常的 Ubuntu 上可以正常运行。
消息队列 vs 管道 #
消息队列 > 命名管道
- 消息队列收发消息自动保证了同步,不需要由进程自己来提供同步方法,而命名管道需要自行处理同步问题;
- 消息队列接收数据可以根据消息类型有选择的接收特定类型的数据,不需要像命名管道一样默认接收数据。
消息队列 < 命名管道
消息队列有一个缺点就是发送和接收的每个数据都有最大长度的限制。
共享内存 #
如图:
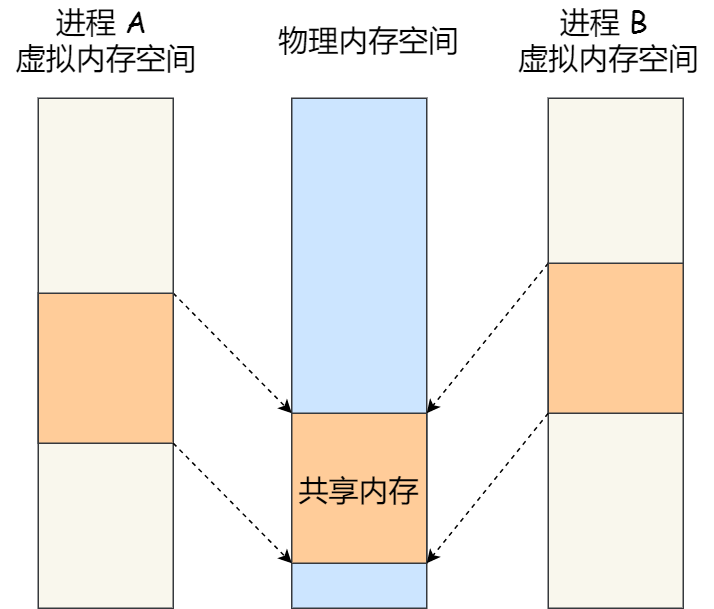
多个进程共同使用一块内存,自然可以通信。
可开辟中一块内存,用于各个进程间共享,使得各个进程可以直接读写同一块内存空间,就像线程共享同一块地址空间一样,该方式基本上是最快的进程间通信方式,因为没有系统调用干预,也没有数据的拷贝操作,但由于共享同一块地址空间,数据竞争的问题就会出现,需要自己引入同步机制解决数据竞争问题。
共享内存只是一种方式,它的实现方式有很多种,主要的有 mmap 系统调用、Posix 共享内存以及 System V 共享内存等。通过这三种“工具”共享地址空间后,通信的目的自然就会达到。
优点:效率高。
缺点:对开发者编程能力要求很高,很容易写出问题,特别是并发环境下。
信号量 #
信号量就是一个特殊的变量,程序对其访问都是原子操作,每个信号量开始都有个初始值。最简单最常见的信号量是只能取 0 和 1 的变量,也叫二值信号量。
信号量有两个操作,P 和 V:
- P:如果信号量变量值大于 0,则变量值减 1,如果值为 0,则阻塞进程;
- V:如果有进程阻塞在该信号量上,则唤醒阻塞的进程,如果没有进程阻塞,则变量值加 1
信号 #
信号也是进程间通信的一种方式,信号可以在任何时候发送给某一个进程,如果进程当前并未处于执行状态,内核将信号保存,直到进程恢复到执行态再发送给进程,进程可以对信号设置预处理方式,如果对信号设置了阻塞处理,则信号的传递会被延迟直到阻塞被取消,如果进程结束,那信号就被丢弃。我们常用的 CTRL+C 和 kill 等就是信号的一种,也达到了进程间通信的目的,进程也可以对信号设置 signal 捕获函数自定义处理逻辑。
这种方式有很大的缺点:只有通知的作用,通知了一下消息的类型,但不能传输要交换的任何数据。
Linux 系统中常见的信号有:
- SIGHUP:该信号在用户终端结束时发出,通常在中断的控制进程结束时,所有进程组都将收到该信号,该信号的默认操作是终止进程;
- SIGINT:程序终止信号,通常的 CTRL+C 产生该信号来通知终止进程;
- SIGQUIT:类似于程序错误信号,通常的 CTRL+\产生该信号通知进程退出时产生 core 文件;
- SIGILL:执行了非法指令,通常数据段或者堆栈溢出可能产生该信号;
- SIGTRAP:供调试器使用,由断电指令或其它陷阱指令产生;
- SIGABRT:使程序非正常结束,调用 abort 函数会产生该信号;
- SIGBUS:非法地址,通常是地址对齐问题导致,比如访问一个 4 字节长的整数,但其地址不是 4 的倍数;
- SIGSEGV:合理地址的非法访问,访问了未分配的内存或者没有权限的内存区域;
- SIGPIPE:管道破裂信号,socket 通信时经常会遇到,进程写入了一个无读者的管道;
- SIGALRM:时钟定时信号,由 alarm 函数设置的时间终止时产生;
- SIGFPE:出现浮点错误(比如除 0 操作);
- SIGKILL:杀死进程(不能被捕捉和忽略);
文件 #
显而易见,多个进程可以操作同一个文件,所以也可以通过文件来进行进程间通信。
socket #
很类似于网络通信,分为客户端和服务端:
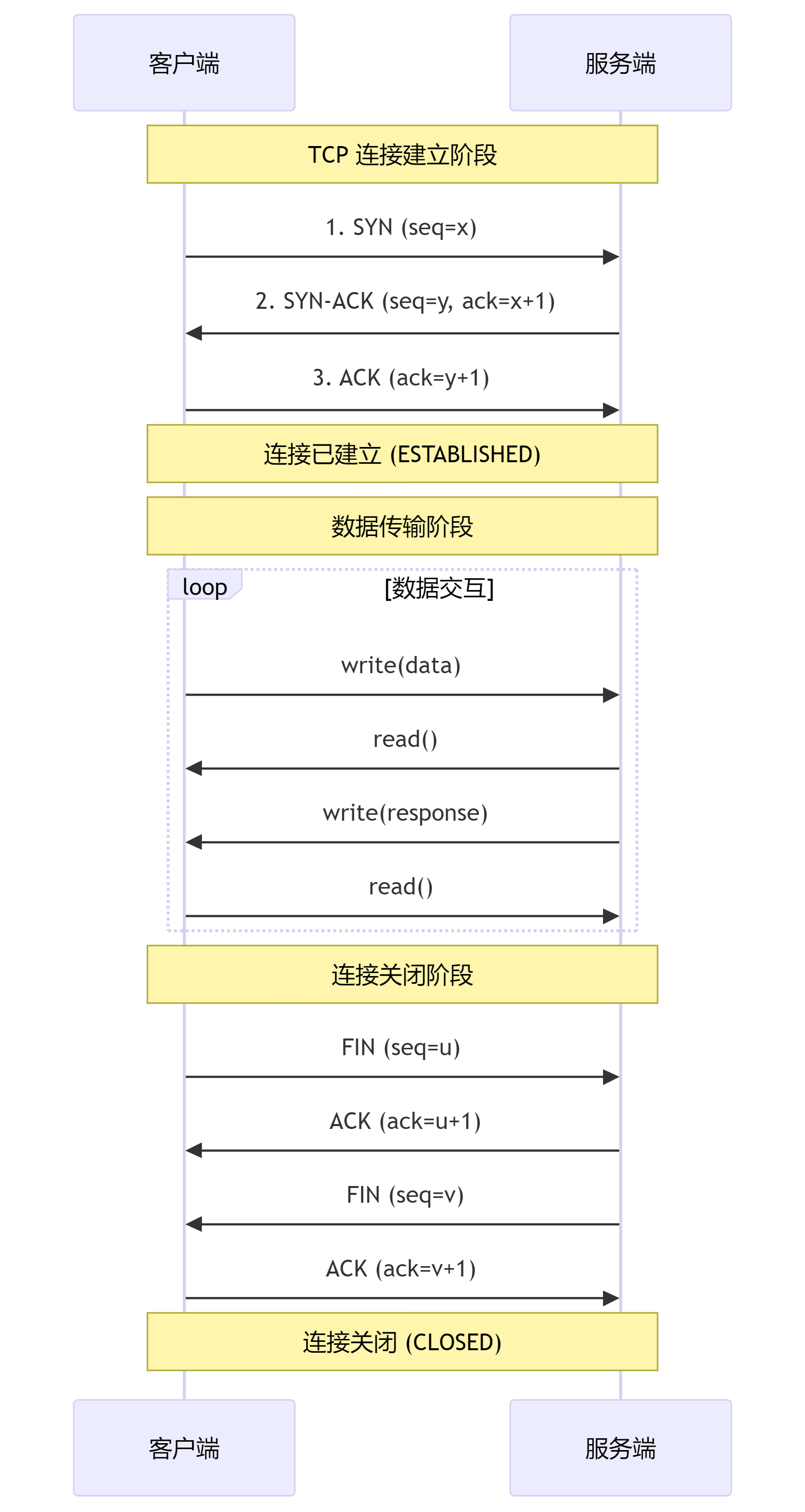
线程通信 #
所有线程共用所在进程的内存,所以肯定可以通信。但要注意线程安全问题,需要通过锁机制或者原子机制避免多线程环境下的数据竞争问题。
🌟进程调度 #
当系统中有多个进程同时竞争 CPU,如果只有一个 CPU 可用,那同一时刻只会有一个进程处于运行状态,操作系统必须要选择下一个要运行的是哪个进程,在操作系统中,完成选择工作的这部分称为调度程序,该程序使用的算法称作调度算法。
什么时候进行调度? #
- 系统调用创建一个新进程后,需要决定是运行父进程还是运行子进程
- 一个进程退出时需要做出调度决策,需要决定下一个运行的是哪个进程
- 当一个进程阻塞在 I/O 和信号量或者由于其它原因阻塞时,必须选择另一个进程运行
- 当一个 I/O 中断发生时,如果中断来自 IO 设备,而该设备现在完成了工作,某些被阻塞的等待该 IO 的进程就成为可运行的就绪进程了,是否让新就绪的进程运行,或者让中断发生时运行的进程继续运行,或者让某个其它进程运行,这就取决于调度程序的抉择了。
调度的准则 #
CPU利用率:如何调度可以使 CPU 的利用率达到最大系统吞吐率:系统吞吐量表示单位时间内 CPU 完成作业的数量响应时间:调度策略要尽量保证响应时间在用户接受的范围内周转时间:周转时间是作业从开始到完成所需的时间,尽量使这个时间较小。
调度的策略 #
不同系统环境下有不同的调度策略算法。调度算法也是有 KPI 的,对调度算法首先提的需求就是:
- 公平:调度算法需要给每个进程公平的 CPU 份额,相似的进程应该得到相似的服务,对一个进程给予较其它等价的进程更多的 CPU 时间是不公平的,被普通水平的应届生工资倒挂也是不公平的!
- 执行力:每一个策略必须强制执行,需要保证规定的策略一定要被执行。
- 平衡:需要保证系统的所有部分尽可能都忙碌
进程调度算法 ⭐️⭐️⭐️ #
进程调度:多个进程都在等待处理器调度执行,处理器如何选择?
进程调度分为 抢占式 和 非抢占式。
非抢占式调度算法:挑选一个进程,然后让该进程运行直至被阻塞,或者直到该进程自动释放 CPU,即使该进程运行了若干个小时,它也不会被强迫挂起。这样做的结果是,在时钟中断发生时不会进行调度,在处理完时钟中断后,如果没有更高优先级的进程等待,则被中断的进程会继续执行。简单来说,调度程序必须等待事件结束。
非抢占方式引起进程调度的条件:
- 进程执行结束,或发生某个事件而不能继续执行
- 正在运行的进程因有 I/O 请求而暂停执行
- 进程通信或同步过程中执行了某些原语操作(wait、block 等)
抢占式调度算法:挑选一个进程,并且让该进程运行某个固定时段的最大值。如果在该时段结束时,该进程仍在运行,它就被挂起,而调度程序挑选另一个进程运行,进行抢占式调度处理,需要在时间间隔的末端发生时钟中断,以便 CPU 控制返回给调度程序,如果没有可用的时钟,那么非抢占式调度就是唯一的选择。简单来说,就是当前运行的进程在事件没结束时就可以被换出,防止单一进程长时间独占 CPU 资源。下面会介绍很多抢占式调度算法:优先级算法、短作业优先算法、轮转算法等。
常见的进程调度算法:
因为不同的应用有不同的目标,不同的系统中,调度程序的优化也是不同的,大体可以分为三种环境:
批处理系统 #
批处理系统的管理者为了掌握系统的工作状态,主要关注三个指标:
- 吞吐量:是系统每小时完成的作业数量
- 周转时间:指从一个作业提交到完成的平均时间
- CPU 利用率:尽可能让 CPU 忙碌,但又不能过量
具体调度算法:
先来先服务:先来后到,就像平时去商店买东西需要排队一样,使用该算法,进程按照它们请求 CPU 的顺序来使用 CPU,该算法最大的优点就是简单易于实现,太容易的不一定是好的,该算法也有很大的缺点:平均等待时间波动较大,时间短的任务可能排队排在了时间长的任务后面。举个生活中的例子,排着队去取快递,如果每个人都很快取出来快递还好,如果前面有几个人磨磨唧唧到快递柜前才拿出手机打开 app,再找半分钟它的取件码,就会严重拖慢后面的人取快递的速度,同理排着队的进程如果每个进程都很快就运行完还好,如果其中有一个得到了 CPU 的进程运行时候磨磨唧唧很长时间都运行不完,那后面的进程基本上就没有机会运行了!短作业优先调度:该调度算法是非抢占式的算法,每个进程执行期间不会被打断,每次都选择执行时间最短的进程来调度,但问题来了,操作系统怎么可能知道进程具体的执行时间呢,所以该算法注定是基于预测性质的理想化算法,而且有违公平性,而且可能导致运行时间长的任务得不到调度。最短剩余时间优先:该调度算法是抢占式的算法,是最短作业优先的抢占版本,在进程运行期间,如果来了个更短时间的进程,那就转而去把 CPU 时间调度给这个更短时间的进程,它的缺点和最短作业优先算法类似。
交互式系統 #
对于交互系统最重要的指标就是响应时间和均衡性:
- 响应时间:一个请求被提交到产生第一次响应所花费的时间。你给别人发微信别人看后不回复你或者几个小时后才回复你,你是什么感受,这还是交互式吗?
- 均衡性:减少平均响应时间的波动。需要符合固有期望和预期,你给别人发微信,他有时候秒回复,有时候几个小时后才回复。在交互式系统中,可预测性比高差异低平均更重要。
具体调度算法:
- 轮转调度:每个进程被分配一个时间段,称为时间片,即 CPU 做到雨露均沾,轮流翻各个进程的牌子,这段时间宠幸进程 A,下一段时间宠幸进程 B,再下一段时间宠幸进程 C,确保每个进程都可以获得 CPU 时间,如果 CPU 时间特别短的话,在外部看来像是同时宠幸了所有进程一样。那么问题来了,这个时间片究竟多长时间好呢?如果时间片设的太短会导致过多的进程切换,频繁的上下文切换会降低 CPU 效率,而如果时间片设的太长又可能对短的交互请求的响应时间变长,通常将时间片设为 20-50ms 是个比较合理的折中,大佬们的经验规则时维持上下文切换的开销处于 1% 以内。
- 优先级调度:上面的轮转调度算法是默认每个进程都同等重要,都有相同优先级,然而有时候进程需要设置优先级,例如某些播放视频的前台进程可以优先于某些收发邮件的后台守护进程被调度,在优先级调度算法中,每个优先级都有相应的队列,队列里面装着对应优先级的进程,首先在高优先级队列中进行轮转调度,当高优先级队列为空时,转而去低优先级队列中进行轮转调度,如果高优先级队列始终不为空,那么低优先级的进程很可能就会饥饿到很久不能被调度。
- 多级队列:多级队列算法与优先级调度算法不同,优先级算法中每个进程分配的是相同的时间片,而在多级队列算法中,不同队列中的进程分配给不同的时间片,当一个进程用完分配的时间片后就移动到下一个队列中,这样可以更好的避免上下文频繁切换。举例:有一个进程需要 100 个时间片,如果每次调度都给分配一个时间片,则需要 100 次上下文切换,这样 CPU 运行效率较低,通过多级队列算法,可以考虑最开始给这个进程分配 1 个时间片,然后被换出,下次分给它 2 个时间片,再换出,之后分给它 4、8、16、64 个时间片,这样分配的话,该进程只需要 7 次交换就可以运行完成,相比 100 次上下文切换运行效率高了不少,但顾此就会失彼,那些需要交互的进程得到响应的速度就会下降。
- 最短进程优先:交互式系统中应用最短进程优先算法其实是非常适合的,每次都选择执行时间最短的进程进行调度,这样可以使任务的响应时间最短,但这里有个任务,还没有运行呢,我怎么知道进程的运行时间呢?根本没办法非常准确的再当前可运行进程中找出最短的那个进程。有一种办法就是根据进程过去的行为进行预测,但这能证明是个好办法吗?
- 保证调度:这种调度算法就是向用户做出明确的可行的性能保证,然后去实现它。一种很实际的可实现的保证就是确保 N 个用户中每个用户都获得 CPU 处理能力的 1/N,类似的,保证 N 个进程中每个进程都获得 1/N 的 CPU 时间。
- 彩票调度:彩票调度算法基本思想是为进程提供各种资源(CPU 时间)的彩票,一旦需要做出调度决策时,就随机抽出一张彩票,拥有该彩票的进程获得该资源,很明显,拥有彩票越多的进程,获得资源的可能性越大。该算法在程序喵看来可以理解为股票算法,将 CPU 的使用权分成若干股,假设共 100 股分给了 3 个进程,给这些进程分别分配 20、30、50 股,那么它们大体上会按照股权比例(20:30:50)划分 CPU 的使用。
- 公平分享调度:假设有系统两个用户,用户 1 启动了 1 个进程,用户 2 启动了 9 个进程,如果使用轮转调度算法,那么用户 1 将获得 10% 的 CPU 时间,用户 2 将获得 90% 的 CPU 时间,这对用户来说公平吗?如果给每个用户分配 50% 的 CPU 时间,那么用户 2 中的进程获得的 CPU 时间明显比用户 1 中的进程短,这对进程来说公平吗?这就取决于怎么定义公平啦?
实时系统 #
实时系统顾名思义,最关键的指标当然是实时:
- 满足截止时间:需要在规定 deadline 前完成作业;
- 可预测性:可预测性是指在系统运行的任何时刻,在任何情况下,实时系统的资源调配策略都能为争夺资源的任务合理的分配资源,使每个实时任务都能得到满足。
调度算法分类:
- 硬实时:必须在 deadline 之前完成工作,如果 delay,可能会发生灾难性或发生严重的后果;
- 软实时:必须在 deadline 之前完成工作,但如果偶尔 delay 了,也可以容忍。
具体调度算法:
- 单调速率调度:采用抢占式、静态优先级的策略,调度周期性任务。每个任务最开始都被配置好了优先级,当较低优先级的进程正在运行并且有较高优先级的进程可以运行时,较高优先级的进程将会抢占低优先级的进程。在进入系统时,每个周期性任务都会分配一个优先级,周期越短,优先级越高。这种策略的理由是:更频繁的需要 CPU 的任务应该被分配更高的优先级。
- 最早截止时间调度:根据截止时间动态分配优先级,截止时间越早的进程优先级越高。该算法中,当一个进程可以运行时,它应该向操作系统通知截止时间,根据截止时间的早晚,系统会为该进程调整优先级,以便满足可运行进程的截止时间要求。它与单调速率调度算法的区别就是一个是静态优先级,一个是动态优先级。
⏱️ 进程调度算法对比 #
📌 调度算法分类 #
🔄 常见调度算法对比 #
📊 性能指标对比 #
如何配置调度策略 #
调度算法有很多种,各有优缺点,操作系统自己很少能做出最优的选择,那么可以把选择权交给用户,由用户根据实际情况来选择适合的调度算法,这就叫策略与机制分离,调度机制位于内核,调度策略由用户进程决定,将调度算法以某种形式参数化,由用户进程来选择参数从而决定内核使用哪种调度算法。
操作系统如何完成的进程调度? #
进程的每次变化都会有相应的状态,而操作系统维护了一组状态队列,表示系统中所有进程的当前状态;不同的状态有不同的队列,有就绪队列阻塞队列等,每个进程的 PCB 都根据它的状态加入到相应的队列中,当一个进程的状态发生变化时,它的 PCB 会从一个状态队列中脱离出来加入到另一个状态队列。
注意图中同一种状态为什么有多个队列呢?因为进程有优先级概念,相同状态的不同队列的优先级不同。
🌟同步与互斥 #
进程同步的方法 #
操作系统中,进程是具有不同的地址空间的,两个进程是不能感知到对方的存在的。有时候,需要多个进程来协同完成一些任务。
当多个进程需要对同一个内核资源进行操作时,这些进程便是竞争的关系,操作系统必须协调各个进程对资源的占用,进程的互斥是解决进程间竞争关系的方法。 进程互斥指若干个进程要使用同一共享资源时,任何时刻最多允许一个进程去使用,其他要使用该资源的进程必须等待,直到占有资源的进程释放该资源。
当多个进程协同完成一些任务时,不同进程的执行进度不一致,这便产生了进程的同步问题。需要操作系统干预,在特定的同步点对所有进程进行同步,这种协作进程之间相互等待对方消息或信号的协调关系称为进程同步。进程互斥本质上也是一种进程同步。
进程的同步方法:
- 互斥锁
- 读写锁
- 条件变量
- 记录锁(record locking)
- 信号量
- 屏障(barrier)
线程同步的方法 #
操作系统中,属于同一进程的线程之间具有相同的地址空间,线程之间共享数据变得简单高效。遇到竞争的线程同时修改同一数据或是协作的线程设置同步点的问题时,需要使用一些线程同步的方法来解决这些问题。
线程同步的方法:
- 互斥锁
- 读写锁
- 条件变量
- 信号量
- 自旋锁
- 屏障(barrier)
进程同步与线程同步有什么区别 #
进程之间地址空间不同,不能感知对方的存在,同步时需要将锁放在多进程共享的空间。而线程之间共享同一地址空间,同步时把锁放在所属的同一进程空间即可。
临界区和临界资源 #
临界资源:同时只能允许一个进程访问的资源。
临界区:进程中用于访问临界资源的代码。
如何防止多个进程同时进入临界区? #
- 闲时让进:空闲状态你可以进入
- 忙则等待:有人正在用,你等一等
- 有限等待:不会让你一直等的放心好啦
- 让权等待:你出问题了,就别占着位置啦,让别人用吧。
同步和互斥的经典示例 #
生产者-消费者问题
一组生产者向一组消费者提供产品,他们共享一个缓冲区,生产者会向里面投放物品,消费者从里面取走产品。 但是这个里面存在一些问题:
- 缓冲区内没有物品,消费者还不断取
- 缓冲区已经满了,生产者还在不断放入
- 多个消费者同时取
读写锁 #
多线程环境下对共享资源的读多写少场景,使用读写锁正适合,它通过区分读操作和写操作,可以显著提高并发性能。
- 读锁:多个线程可同时持有读锁(共享访问)。
- 写锁:仅一个线程能持有写锁,且期间不允许任何读锁或其他写锁(独占访问)。
优势:
- 读操作不互斥,适合读多写少的场景(如缓存、数据库)。
- 写操作独占资源,避免数据竞争。
读饥饿是什么 #
读饥饿是读写锁中的一种现象,指写线程因读线程持续占用锁而长时间无法获取写锁,导致写操作被“饿死”(无法执行)。这种现象在高并发读场景下很常见。
原因:
- 多个读线程频繁获取读锁(共享访问)。
- 写线程尝试获取写锁时,必须等待所有读锁释放。
- 若读锁的获取是连续的(无间隙),写线程将无限等待。
危害:
- 数据更新延迟:写操作无法执行,导致数据长时间不更新。
- 系统响应下降:写线程阻塞可能引发超时或死锁。
- 公平性破坏:违背“先来先服务”原则。
解决方案:
- 公平读写锁:通过队列或优先级机制,保证写锁请求不会被后续读锁插队。比如一旦有写锁请求,后续读锁必须等待写锁完成。
- 限制读锁持有时间:设置读锁的最大持有时间,超时后自动释放。
- 避免长期持有读锁:将长耗时读操作拆分为多个短操作,间歇释放锁。
🌟死锁 #
死锁产生的条件 #
请求和保持:请求新资源的同时,保持住已的占有资源不松手互斥:某一时刻下,一个资源只能一个进程所占有不可剥夺:获得的资源没有使用完时,别人不可以抢走循环等待:没有获得新资源,绝不死心。
处理死锁的方法 #
鸵鸟法:对死锁不管不问预防死锁:设置某些限制条件,破坏死锁产生的四个条件之一避免死锁:资源分配的动态过程中,用某种方法防止系统进入不安全状态,从而避免死锁的发生。检测死锁:专门喊个人来检测死锁是否存在。
死锁预防 #
破坏四个条件之一:
互斥条件:不太可能通过这个来解决请求和保持:静态分配,进程运行之前先分配所有资源给他不可剥夺:当某个资源长时间不能获得需要的新资源时,则放弃他的所有资源循环等待:当等待一段时间还没有获得资源时,则放弃等待
死锁的检测和解除 #
死锁检测:可以通过资源分配图来检测进程的资源占用情况及申请情况,进而来判断是否产生了死锁。如果资源分配图构成了环,则表示有死锁。
死锁解除:可以通过 剥夺资源、进程撤销 等方式来解除死锁。
死锁产生的条件 #
处理死锁的方法 #
内存管理篇 #
🌟什么是物理内存? #
我们常说的物理内存大小就是指内存条的大小,一般买电脑时都会看下内存条是多大容量。
话说如果内存条大小是 100G,那这 100G 就都能够被使用吗?不一定,更多的还是要看 CPU 地址总线的位数,如果地址总线只有 20 位,那么它的寻址空间就是 1MB,即使可以安装 100G 的内存条也没有意义,也只能视物理内存大小为 1MB。
物理内存的缺点 #
这种方式下每个程序都可以直接访问物理内存,有两种情况:
系统中只有一个进程在运行:如果用户程序可以操作物理地址空间的任意地址,它们就很容易在不经意间破坏了操作系统,使系统出现各种奇奇怪怪的问题。
系统有多个进程同时在运行:如图,理想情况下可以使进程 A 和进程 B 各占物理内存的一边,两者互不干扰,但这也只是在理想情况下。
- 进程 B 在后台正常运行着,程序员在调试进程 A 时有可能就会误操作到进程 B 正在使用的物理内存,导致进程 B 运行出现异常,两个程序操作了同一地址空间,第一个程序在某一地址空间写入某个值,第二个程序在同一地址又写入了不同值,这就会导致程序运行出现问题,所以直接使用物理内存会使所有进程的安全性得不到保证。

如何解决?
可以考虑为存储器创造新的抽象概念:地址空间。
地址空间为程序创造了一种抽象的内存,是进程可用于寻址内存的一套地址集合,同时每个进程都有一套自己的地址空间,一个进程的地址空间独立于其它进程的地址空间。
如何为程序创造独立的地址空间?
最简单的办法就是把每个进程的地址空间分别映射到物理内存的不同部分。这样就可以保证不同进程使用的是独立的地址空间。
给每个进程提供一个基址 A 和界限 B,进程内使用的空间为 x,则对应的物理地址为 A + x,同时需要保证 A + x < B,如果访问的地址超过的界限,需要产生错误并中止访问。 为了达到目的,CPU 配置了两个特殊硬件寄存器:基址寄存器和界限寄存器,当一个进程运行时,程序的起始物理地址和长度会分别装入到基址寄存器和界限寄存器里,进程访问内存,在每个内存地址送到内存之前,都会先加上基址寄存器的内容。
缺点:每次访问内存都需要进行加法和比较运算,比较运算很快,但是加法运算由于进位传递事件的问题,在没有使用特殊电路的情况下会显得很慢。
此外,每个进程运行都会占据一定的物理内存,如果物理内存足够大到可以容纳许多个进程同时运行还好,但现实中物理内存的大小是有限的,可能会出现内存不够用的情况,怎么办?
方法 1:如果是因为程序太大,大到超过了内存的容量,可以采用 手动覆盖 技术,只把需要的指令和数据保存在内存中。
方法 2:如果是因为程序太多,导致超过了内存的容量,可以采用 自动交换 技术,把暂时不需要执行的程序移动到外存中。
覆盖技术 #
把程序按照自身逻辑结构,划分成多个功能相互独立的程序模块,那些不会同时执行的模块可以共享到同一块内存区域,按时间顺序来运行:
- 将常用功能需要的代码和数据常驻在内存中;
- 将不常用的功能划分成功能相互独立的程序模块,平时放到外存中,在需要的时候将对应的模块加载到内存中;
- 那些没有调用关系的模块平时不需要装入到内存,它们可以共用一块内存区,需要时加载到内存,不需要时换出到外存中;
交换技术 #
多个程序同时运行,可以将暂时不能运行的程序送到外存,获得更多的空闲内存,操作系统将一个进程的整个地址空间内容换出到外存中,再将外存中某个进程的整个地址空间信息换入到内存中,换入换出内容的大小是整个程序的地址空间。
交换技术在实现上有很多困难:
- 需要确定什么时候发生交换:简单的办法是可以在内存空间不够用时换出一些程序;
- 交换区必须足够大:多个程序运行时,交换区(外存)必须足够大,大到可以存放所有程序所需要的地址空间信息;
- 程序如何换入:一个程序被换出后又重新换入,换入的内存位置可能不会和上一次程序所在的内存位置相同,这就需要动态地址映射机制。
覆盖 vs 交换 #
- 覆盖只能发生在那些相互之间没有调用关系的程序模块之间,因此程序员必须给出程序内的各个模块之间的逻辑覆盖结构。
- 交换技术是以在内存中的程序大小为单位来进行的,它不需要程序员给出各个模块之间的逻辑覆盖结构。
通俗来说:覆盖发生在程序的内部,交换发生在程序与程序之间。
但是这两种技术都有缺点:
- 覆盖技术:需要程序员自己把整个程序划分为若干个小的功能模块,并确定各个模块之间的覆盖关系,增加了程序员的负担,很少有程序员擅长这种技术;
- 交换技术:以进程作为交换的单位,需要把进程的整个地址空间都换进换出,增加了处理器的开销,还需要足够大的外存。
那有没有更好的解决上述问题的方法呢?答案是虚拟内存技术。
🌟什么是虚拟内存? #
虚拟内存,那就是虚拟出来的内存,它的基本思想就是确保每个程序拥有自己的地址空间,地址空间被分成多个块,每一块都有连续的地址空间,同时物理空间也分成多个块,块大小和虚拟地址空间的块大小一致,操作系统会自动将虚拟地址空间映射到物理地址空间,程序所关注的只是虚拟内存,请求的也是虚拟内存,其实真正使用的是物理内存。
虚拟内存技术有覆盖技术的功能,但它不是把程序的所有内容都放在内存中,因而能够运行比当前的空闲内存空间还要大的程序。它比覆盖技术做的更好,整个过程由操作系统自动来完成,无需程序员的干涉;
虚拟内存技术有交换技术的功能,能够实现进程在内存和外存之间的交换,因而获得更多的空闲内存空间。它比交换技术做的更好,它只对进程的部分内容在内存和外存之间进行交换。
虚拟内存技术的具体实现:
虚拟内存技术一般是在页式管理(下面介绍)的基础上实现:
- 在装入程序时,不必将其全部装入到内存,而只需将当前需要执行的部分页面装入到内存,就可让程序开始执行;
- 在程序执行过程中,如果需执行的指令或访问的数据尚未在内存(称为缺页)。则由处理器通知操作系统将相应的页面调入到内存,然后继续执行程序;
- 另一方面,操作系统将内存中暂时不使用的页面调出保存在外存上,从而腾出更多空闲空间存放将要装入的程序以及将要调入的页面。
虚拟内存技术的特点:
- 大的用户空间:通过把物理内存与外存相结合,提供给用户的虚拟内存空间通常大于实际的物理内存,即实现了两者的分离。如 32 位的虚拟地址理论上可以访问 4GB,而可能计算机上仅有 256M 的物理内存,但硬盘容量大于 4GB;
- 部分交换:与交换技术相比较,虚拟存储的调入和调出是对部分虚拟地址空间进行的;
- 连续性:程序可以使用一系列相邻连续的虚拟地址来映射物理内存中不连续的大内存缓冲区;
- 安全性:不同进程使用的虚拟地址彼此隔离。一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
为什么要有虚拟地址空间呢? #
- 先从没有虚拟地址空间的时候说起吧!没有虚拟地址空间的时候,程序都是直接访问和操作的都是物理内存 。但是这样有什么问题呢?
- 用户程序可以访问任意内存,寻址内存的每个字节,这样就很容易(有意或者无意)破坏操作系统,造成操作系统崩溃。
想要同时运行多个程序特别困难,比如你想同时运行一个微信和一个 QQ 音乐都不行。为什么呢?举个简单的例子:微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就造成了微信这个程序就会崩溃。
总结来说:如果直接把物理地址暴露出来的话会带来严重问题,比如可能对操作系统造成伤害以及给同时运行多个程序造成困难。
通过虚拟地址访问内存有以下优势:
- 程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
- 程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。当物理内存的供应量变小时,内存管理器会将物理内存页(通常大小为 4 KB)保存到磁盘文件。数据或代码页会根据需要在物理内存与磁盘之间移动。
- 不同进程使用的虚拟地址彼此隔离。一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
虚拟内存如何映射到物理内存? #
如图,CPU 里有一个内存管理单元(Memory Management Unit),简称 MMU,虚拟内存不是直接送到内存总线,而是先给到 MMU,由 MMU 来把虚拟地址映射到物理地址,程序只需要管理虚拟内存就好,映射的逻辑自然有其它模块自动处理。
什么是分页内存管理? #
将虚拟地址空间分成若干个块,每个块都有固定的大小,物理地址空间也被划分成若干个块,每个块也都有固定的大小,物理地址空间的块和虚拟地址空间的块大小相等,虚拟地址空间这些块就被称为页面,物理地址空间这些块被称为帧。
关于分页这里有个问题,页面的大小是多少合适呢?页面太大容易产生空间浪费,程序假如只使用了 1 个字节却被分配了 10M 的页面,这岂不是极大的浪费,页面太小会导致页表(下面介绍)占用空间过大,所以页面需要折中选择合适的大小,目前大多数系统都使用 4KB 作为页的大小。
上面关于虚拟内存如何映射到物理内存,只介绍了 MMU,但是 MMU 是如何工作的还没有介绍,MMU 通过页表这个工具将虚拟地址转换为物理地址。32 位的虚拟地址分成两部分(虚拟页号和偏移量),MMU 通过页表找到了虚拟页号对应的物理页号,物理页号 + 偏移量就是实际的物理地址。
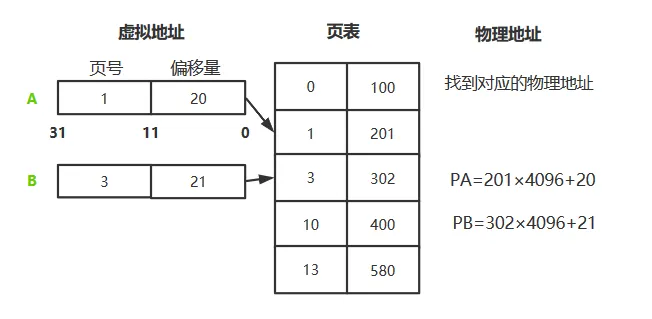
上图只表示了页表的大体功能,页表的结构其实还很复杂,继续往下看。
页表的目的就是虚拟页面映射为物理内存的页框,页表可以理解为一个数学函数,函数的输入是虚拟页号,函数的输出是物理页号,通过这个函数可以把虚拟页面映射到物理页号,从而确定物理地址。不同机器的页表结构不同,通常页表的结构如下:
- 页框号:最主要的一项,页表最主要的目的就是找到物理页号;
- 有效位:1 表示有效,表示该表项是有效的,如果为 0,表示该表项对应的虚拟页面现在不在内存中,访问该页面会引起缺页中断,缺页中断后会去物理空间找到一个可用的页框填回到页表中;
- 保护位:表示一个页允许什么类型的访问,可读可写还是可执行;
- 修改位:该位反应了页面的状态,在操作系统重新分配页框时有用,在写入一页时由硬件自动设置该位,重新分配页框时,如果一个页面已经被修改过,则必须把它这个脏页写回磁盘,如果没有被修改过,表示该页是干净的,它在磁盘上的副本依然是有效的,直接丢弃该页面即可。
- 访问位:该位主要用于帮助操作系统在发生缺页中断时选择要被淘汰的页面,不再使用的页面显然比正在使用的页面更适合被淘汰,该位在页面置换算法中发挥重要作用。
- 高速缓存禁止位:该位用于禁止该页面被高速缓存。
如何加快地址映射速度? #
每次访问内存都需要进行虚拟地址到物理地址的映射,每次映射都需要访问一次页表,所有的指令执行都必须通过内存,很多指令也需要访问内存中的操作数,因此每条指令执行基本都会进行多次页表查询,为了程序运行速度,指令必须要在很短的时间内执行完成,而页表查询映射不能成为指令执行的瓶颈,所以需要提高页表查询映射的速度。
如何才能提高速度呢?可以为页表提供一个缓存,通过缓存进行映射比通过页表映射速度更快,这个缓存是一个小型的硬件设备,叫 快表(TLB),MMU 每次进行虚拟地址转换时,首先去 TLB 中查找,找到了有效的物理页框则直接返回,如果没有找到则进行正常的页表访问,页表中找到后则更新 TLB,从 TLB 中淘汰一个表项,然后用新找到的表项替代它,这样下次相同的页面过来时可以直接命中 TLB 找到对应的物理地址,速度更快,不需要继续去访问页表。
这里之所以认为 TLB 能提高速度主要依靠程序局部性原理,程序局部性原理是指程序在执行过程中的一个较短时间,所执行的指令地址和要访问的数据通常都局限在一块区域内,这里可分为 时间局部性 和 空间局部性:
- 时间局部性:一条指令的一次执行和下次执行,一个数据的一次访问和下次访问都集中在一个较短时间内;
- 空间局部性:当前指令和邻近的几条指令,当前访问的数据和邻近的几个数据都集中在一个较小区域内。
多级页表 #
通过 TLB 可以加快虚拟地址到物理地址的转换速度,还有个问题,现在都是 64 位操作系统啦,有很大的虚拟地址空间,虚拟地址空间大那对应的页表也会非常大,又加上多个进程多个页表,那计算机的大部分空间就都被拿去存放页表,有没有更好的办法解决页表大的问题呢?答案是多级页表。
页表为什么大?32 位环境下,虚拟地址空间有 4GB,一个页大小是 4KB,那么整个页表就需要 100 万页,而每个页表项需要 4 个字节,那整个页表就需要 4MB 的内存空间,又因为每个进程都有一个自己的页表,多个进程情况下,这简直就是灾难。
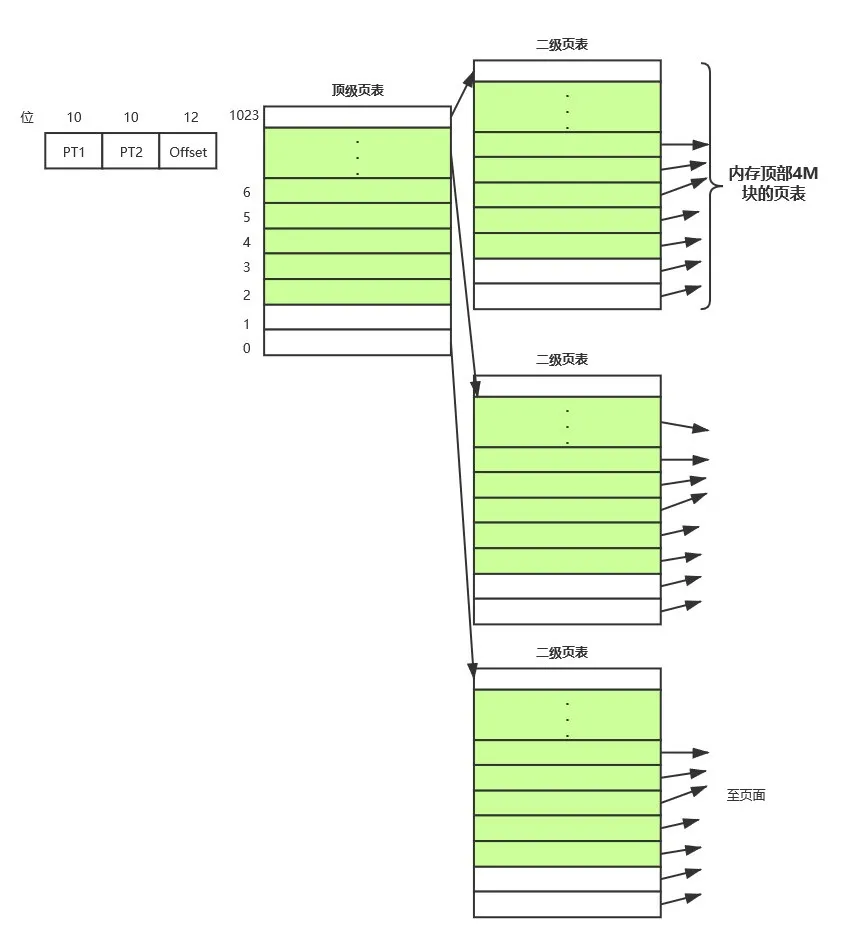
如图,以一个 32 位虚拟地址的二级页表为例,将 32 位虚拟地址划分为 10 位的 PT1 域,10 位的 PT2 域,以及 12 位的 offset 域,当一个虚拟地址被送入 MMU 时,MMU 首先提取 PT1 域并把其值作为访问第一级页表的索引,之后提取 PT2 域把把其值作为访问第二级页表的索引,之后再根据 offset 找到对应的页框号。
32 位的虚拟地址空间下:每个页面 4KB,且每条页表项占 4B:
- 一级页表:进程需要 1M 个页表项(4GB / 4KB = 1M, 2^20 个页表项),即页表(每个进程都有一个页表)占用 4MB(1M * 4B = 4MB)的内存空间。
- 二级页表:一级页表映射 4MB(2^22)、二级页表映射 4KB,则需要 1K 个一级页表项(4GB / 4MB = 1K, 2^10 个一级页表项)、每个一级页表项对应 1K 个二级页表项(4MB / 4KB = 1K),这样页表占用 4.004MB(1K * 4B + 1K * 1K * 4B = 4.004MB)的内存空间。
二级页表占用空间看着貌似变大了,为什么还说多级页表省内存呢?
每个进程都有 4GB 的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到 4GB,何必去映射不可能用到的空间呢?
也就是说,一级页表覆盖了整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有 20% 的一级页表项被用到了,那么页表占用的内存空间就只有 0.804MB(1K4B+0.21K1K4B=0.804MB),对比单级页表的 4M 是不是一个巨大的节约?
那么为什么不分级的页表就做不到这样节约内存呢?我们从页表的性质来看,保存在主存中的页表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了。所以页表一定要覆盖全部虚拟地址空间,不分级的页表就需要有 1M 个页表项来映射,而二级页表则最少只需要 1K 个页表项(此时一级页表覆盖到了全部虚拟地址空间,二级页表在需要时创建)。
二级页表其实可以不在内存中:其实这就像是把页表当成了页面。当需要用到某个页面时,将此页面从磁盘调入到内存;当内存中页面满了时,将内存中的页面调出到磁盘,这是利用到了程序运行的局部性原理。我们可以很自然发现,虚拟内存地址存在着局部性,那么负责映射虚拟内存地址的页表项当然也存在着局部性了!这样我们再来看二级页表,根据局部性原理,1024 个第二级页表中,只会有很少的一部分在某一时刻正在使用,我们岂不是可以把二级页表都放在磁盘中,在需要时才调入到内存?
我们考虑极端情况,只有一级页表在内存中,二级页表仅有一个在内存中,其余全在磁盘中(虽然这样效率非常低),则此时页表占用了 8KB(1K4B+11K*4B=8KB),对比上一步的 0.804MB,占用空间又缩小了好多倍!
什么是缺页中断? #
缺页中断就是要访问的页不在主存中,需要操作系统将页调入主存后再进行访问,此时会暂时停止指令的执行,产生一个页不存在的异常,对应的异常处理程序就会从选择一页调入到内存,调入内存后之前的异常指令就可以继续执行。
缺页中断的处理过程如下:
- 如果内存中有空闲的物理页面,则分配一物理页帧 r,然后转第 4 步,否则转第 2 步;
- 选择某种页面置换算法,选择一个将被替换的物理页帧 r,它所对应的逻辑页为 q,如果该页在内存期间被修改过,则需把它写回到外存;
- 将 q 所对应的页表项进行修改,把驻留位置 0;
- 将需要访问的页 p 装入到物理页面 r 中;
- 修改 p 所对应的页表项的内容,把驻留位置 1,把物理页帧号置为 x;
- 重新运行被中断的指令。
🌟都有哪些页面置换算法? #
当缺页中断发生时,需要调入新的页面到内存中,而内存已满时,选择内存中哪个物理页面被置换是个学问,由此引入了多种页面置换算法,致力于尽可能减少页面的换入换出次数(缺页中断次数)。尽量把未来不再使用的或短期内较少使用的页面换出,通常在程序局部性原理指导下依据过去的统计数据来进行预测。
最优页面置换算法 #
当一个缺页中断发生时,对于保存在内存当中的每一个逻辑页面,计算在它的下一次访问之前,还需等待多长时间,从中选择等待时间最长的那个,作为被置换的页面。注意这只是一种理想情况,在实际系统中是无法实现的,因为操作系统不可能预测未来,不知道每一个页面要等待多长时间以后才会再次被访问。该算法可用作其它算法的性能评价的依据(在一个模拟器上运行某个程序,并记录每一次的页面访问情况,在第二遍运行时即可使用最优算法)。
先进先出算法 #
最先进入的页面最先被淘汰,这种算法很简单,不多介绍。
最近最久未使用算法 #
传说中的 LUR 算法,当发生缺页中断时,选择最近最久没有使用过的页面淘汰,该算法会给每个页面一个字段,用于记录自上次访问以来所经历的时间 T,当需要淘汰一个页面时,选择已有页面中 T 值最大的页面进行淘汰。
第二次机会页面置换算法 #
先进先出算法的升级版,只是在先进先出算法的基础上做了一点点改动,因为先进先出算法可能会把经常使用的页面置换出去,该方法会给这些页面多一次机会,给页面设置一个修改位 R,每次淘汰最老页面时,检查最老页面的 R 位,如果 R 位是 0,那么代表这个页面又老又没有被二次使用过,直接淘汰,如果这个页面的 R 位是 1,表示该页面被二次访问过,将 R 位置 0,并且把该页面放到链表的尾端,像该页面是最新进来的一样,然后继续按这种方法淘汰最老的页面。
时钟页面置换算法 #
第二次机会页面算法的升级版,尽管二次机会页面算法是比较合理的算法,但它需要在链表中经常移动页面,效率比较低,时钟页面置换算法如图,该算法把所有的页面都保存在一个类似时钟的环形链表中,一个表针指向最老的页面,当发生缺页中断时,算法首先检查表针指向的页面,如果它的 R 位是 0 就淘汰该页面,并且把新的页面插入这个位置,然后表针移动到下一个位置,如果 R 位是 1 就将 R 位置 0 并把表针移动到下一个位置,重复这个过程直到找到一个 R 位是 0 的页面然后淘汰。
最不常用算法 #
当发生缺页中断时,选择访问次数最少的那个页面去淘汰。该算法可以给每个页面设置一个计数器,被访问时,该页面的访问计数器 +1,在需要淘汰时,选择计数器值最小的那个页面。
这里有个问题:一个页面如果在开始的时候访问次数很多,但之后就再也不用了,那它可能永远都不会淘汰,但它又确实需要被淘汰,怎么办呢?可以定期把减少各个页面计数器的值,常见的方法是定期将页面计数器右移一位。
最不常用算法(LFU)和最近最久未使用算法(LRU)的区别:LRU 考察的是最久未访问,时间越短越好,而 LFU 考察的是访问的次数或频度,访问次数越多越好。
工作集页面置换算法 #
介绍该算法时首先介绍下什么是工作集。
工作集是指一个进程当前正在使用的页面的集合,可以用二元函数 W(t, s)表示:
- t 表示当前的执行时刻)s 表示工作集窗口,表示一个固定的时间段
- W(t, s)表示在当前时刻 t 之前的 s 时间段中所有访问页面所组成的集合
不同时间下的工作集会有所变化,如图:
- 进程开始执行后随着访问新页面逐步建立较稳定的工作集
- 当内存访问的局部性区域的位置大致稳定时(只访问那几个页面 没有大的改变时) 工作集大小也大致稳定
- 局部性区域的位置改变时(进程前一项事情做完 去做下一项事情时) 工作集快速扩张和快速收缩过渡到下一个稳定值。
工作集置换算法主要就是换出不在工作集中的页面,示例如图:
- 第 0 次访问 e:缺页,装入 e
- 第 1 次访问 d:缺页,装入 d
- 第 2 次访问 a:缺页,装入 a
- 第 3 次访问 c:缺页,装入 c
- 第 4 次访问 c:命中,时间窗口【1-4】,淘汰 e
- 第 5 次访问 d:命中,时间窗口【2-5】
- 第 6 次访问 b:缺页,时间窗口【3-6】,淘汰 a,装入 b
- 第 7 次访问 c:命中,时间窗口【4-7】
- 第 8 次访问 e:缺页,时间窗口【5-8】,装入 e
- 第 9 次访问 c:命中,时间窗口【6-9】,淘汰 d,装入 c
- 第 10 次访问 e:命中,时间窗口【7-10】,淘汰 b
- 第 11 次访问 a:缺页,时间窗口【8-11】,装入 a
- 第 12 次访问 d:缺页,时间窗口【9-12】,装入 d
工作集时钟页面置换算法 #
在工作集页面置换算法中,当缺页中断发生后,需要扫描整个页表才能直到页面的状态,进而才能确定被淘汰的是哪个页面,因此比较耗时,所以引入了工作集时钟页面算法。与时钟算法改进了先进先出算法类似,工作集页面置换算法 + 时钟算法=工作集时钟页面置换算法。避免了每次缺页中断都需要扫描整个页表的开销。
什么是分段内存管理? #
关于分段内存管理我们平时见的最多的应该就是 Linux 可执行程序的代码段数据段之类的啦,要了解分段最好的方式就是了解它的历史。分段起源于 8086CPU,那时候程序访问内存还是直接给出相应单元的物理地址,为了方便多道程序并发执行,需要支持对各个程序进行重定位,如果不支持重定位,涉及到内存访问的地方都需要将地址写死,进而把某个程序加载到物理内存的固定区间。通过分段机制,程序中只需要使用段的相对地址,然后更改段的基址,就方便对程序进行重定位。而且 8086CPU 的地址线宽度是 20 位,可寻址范围可以达到 1MB,但是它们的寄存器都是 16 位,直接使用 1 个 16 位寄存器不可能访存达到 1MB,因此引入了段,引入了段寄存器,段寄存器左移 4 位 + 偏移量就可以生成 20 位的地址,从而达到 1MB 的寻址范围。
以如今的科技水平,其实已经不再需要这种段移位加偏移的方式来访存,分段更多的是一种历史包袱,没有多大实际作用,而且我们经常见到的可执行程序中代码段数据段这些更多是为了在逻辑上能够更清晰有序的构造程序的组织结构。Linux 实际上没有使用分段而只使用了分页管理,这样会更加简单,现在的分段其实更多是为了使逻辑更加清晰。一个公司,为了方便管理都会划分为好多个部门,这其实和分段逻辑相似,没有什么物理意义但是逻辑更加清晰。
分页机制和分段机制的共同点和区别 #
共同点 :
- 分页机制和分段机制都是为了提高内存利用率,减少内存碎片。
- 页和段都是离散存储的,所以两者都是离散分配内存的方式。但是,每个页和段中的内存是连续的。
区别 :
- 页的大小是固定的,由操作系统决定;而段的大小不固定,取决于我们当前运行的程序。
- 分页仅仅是为了满足操作系统内存管理的需求,而段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满足用户的需要。
文件管理篇 #
文件系统的实现 #
提高文件系统性能的方式 #
访问磁盘的效率要比内存慢很多,是时候又祭出这张图了
所以磁盘优化是很有必要的,下面我们会讨论几种优化方式
高速缓存 #
最常用的减少磁盘访问次数的技术是使用 块高速缓存(block cache) 或者 缓冲区高速缓存(buffer cache)。高速缓存指的是一系列的块,它们在逻辑上属于磁盘,但实际上基于性能的考虑被保存在内存中。
管理高速缓存有不同的算法,常用的算法是:检查全部的读请求,查看在高速缓存中是否有所需要的块。如果存在,可执行读操作而无须访问磁盘。如果检查块不再高速缓存中,那么首先把它读入高速缓存,再复制到所需的地方。之后,对同一个块的请求都通过 高速缓存 来完成。
高速缓存的操作如下图所示
由于在高速缓存中有许多块,所以需要某种方法快速确定所需的块是否存在。常用方法是将设备和磁盘地址进行散列操作。然后在散列表中查找结果。具有相同散列值的块在一个链表中连接在一起(这个数据结构是不是很像 HashMap?),这样就可以沿着冲突链查找其他块。
如果高速缓存 已满,此时需要调入新的块,则要把原来的某一块调出高速缓存,如果要调出的块在上次调入后已经被修改过,则需要把它写回磁盘。这种情况与分页非常相似。
块提前读 #
第二个明显提高文件系统的性能是在需要用到块之前试图提前将其写入高速缓存从而提高命中率。许多文件都是 顺序读取。如果请求文件系统在某个文件中生成块 k,文件系统执行相关操作并且在完成之后,会检查高速缓存,以便确定块 k + 1 是否已经在高速缓存。如果不在,文件系统会为 k + 1 安排一个预读取,因为文件希望在用到该块的时候能够直接从高速缓存中读取。
当然,块提前读取策略只适用于实际顺序读取的文件。对随机访问的文件,提前读丝毫不起作用。甚至还会造成阻碍。
减少磁盘臂运动 #
高速缓存和块提前读并不是提高文件系统性能的唯一方法。另一种重要的技术是把有可能顺序访问的块放在一起,当然最好是在同一个柱面上,从而减少磁盘臂的移动次数。当写一个输出文件时,文件系统就必须按照要求一次一次地分配磁盘块。如果用位图来记录空闲块,并且整个位图在内存中,那么选择与前一块最近的空闲块是很容易的。如果用空闲表,并且链表的一部分存在磁盘上,要分配紧邻的空闲块就会困难很多。
不过,即使采用空闲表,也可以使用 块簇 技术。即不用块而用连续块簇来跟踪磁盘存储区。如果一个扇区有 512 个字节,有可能系统采用 1 KB 的块(2 个扇区),但却按每 2 块(4 个扇区)一个单位来分配磁盘存储区。这和 2 KB 的磁盘块并不相同,因为在高速缓存中它仍然使用 1 KB 的块,磁盘与内存数据之间传送也是以 1 KB 进行,但在一个空闲的系统上顺序读取这些文件,寻道的次数可以减少一半,从而使文件系统的性能大大改善。若考虑旋转定位则可以得到这类方法的变体。在分配块时,系统尽量把一个文件中的连续块存放在同一个柱面上。
在使用 inode 或任何类似 inode 的系统中,另一个性能瓶颈是,读取一个很短的文件也需要两次磁盘访问:一次是访问 inode,一次是访问块。通常情况下,inode 的放置如下图所示
其中,全部 inode 放在靠近磁盘开始位置,所以 inode 和它所指向的块之间的平均距离是柱面组的一半,这将会需要较长时间的寻道时间。
一个简单的改进方法是,在磁盘中部而不是开始处存放 inode ,此时,在 inode 和第一个块之间的寻道时间减为原来的一半。另一种做法是:将磁盘分成多个柱面组,每个柱面组有自己的 inode,数据块和空闲表,如上图 b 所示。
当然,只有在磁盘中装有磁盘臂的情况下,讨论寻道时间和旋转时间才是有意义的。现在越来越多的电脑使用 固态硬盘(SSD),对于这些硬盘,由于采用了和闪存同样的制造技术,使得随机访问和顺序访问在传输速度上已经较为相近,传统硬盘的许多问题就消失了。但是也引发了新的问题。
磁盘碎片整理 #
在初始安装操作系统后,文件就会被不断的创建和清除,于是磁盘会产生很多的碎片,在创建一个文件时,它使用的块会散布在整个磁盘上,降低性能。删除文件后,回收磁盘块,可能会造成空穴。
磁盘性能可以通过如下方式恢复:移动文件使它们相互挨着,并把所有的至少是大部分的空闲空间放在一个或多个大的连续区域内。Windows 有一个程序 defrag 就是做这个事儿的。Windows 用户会经常使用它,SSD 除外。
磁盘碎片整理程序会在让文件系统上很好地运行。Linux 文件系统(特别是 ext2 和 ext3)由于其选择磁盘块的方式,在磁盘碎片整理上一般不会像 Windows 一样困难,因此很少需要手动的磁盘碎片整理。而且,固态硬盘并不受磁盘碎片的影响,事实上,在固态硬盘上做磁盘碎片整理反倒是多此一举,不仅没有提高性能,反而磨损了固态硬盘。所以碎片整理只会缩短固态硬盘的寿命。
磁盘调度算法 #
- 先来先服务
- 最短寻道时间:磁盘接收到读命令之后,磁头从当前位置移动到目标位置,所需时间为寻道时间,这个算法就是选择与当前磁头所在轨道距离最近的请求作为下一次服务对象。
- 扫描算法:在磁头的当前移动方向上,找到离磁头最近的磁道
- 循环扫描:规定磁头的单向移动,进行循环扫描
RAID 的不同级别 #
RAID 称为 磁盘冗余阵列,简称 磁盘阵列。利用虚拟化技术把多个硬盘结合在一起,成为一个或多个磁盘阵列组,目的是提升性能或数据冗余。
RAID 有不同的级别
- RAID 0 - 无容错的条带化磁盘阵列
- RAID 1 - 镜像和双工
- RAID 2 - 内存式纠错码
- RAID 3 - 比特交错奇偶校验
- RAID 4 - 块交错奇偶校验
- RAID 5 - 块交错分布式奇偶校验
- RAID 6 - P + Q 冗余
设备管理篇 #
设备控制器:位于 CPU 和 I/O 之间,其接收来自 CPU 的指令,并控制 I/O 设备。
🌟I/O 控制方式 #
- 程序直接控制方式:向 CPU 和 I/O 设备设备控制器发出命令之后,然后就需要一直检测状态寄存器的值,判断是否结束任务,结束之后再去执行下一个任务。
- 中断控制方式:当 CPU 向设备控制器发出启动指令后,则去做其他工作,设备控制器完成任务后,则会发送一个中断指令,告诉他,我已经完成任务了,然后让其继续回来处理任务。但是这样也存在问题,中断过多的话,则会耗费大量 CPU 时间。
- DMA 控制方式:数据传输的基本单位是块,然后传输过程是 DMA 控制器直接于内存交换,仅在传送一个或多个块的开始或结束时,才需 CPU 干预。中断控制方式在每个数据传输完之后中断 CPU,DMA 是一批数据全部传输完才进行中断。
- 通道控制方式:通道控制方式和 DMA 类似,但是所需要的 CPU 干预更少,我们可以将他理解成一个简单的控制器,代理 CPU 进行处理。
关键特性对比 #
#
I/O 软件的层次结构 #
I/O 子系统 #
I/O 核心子系统是设备控制的各类方法,其提供的主要服务就是 I/O调度,高速缓存与缓冲区、设备分配与回收、假脱机。
I/O调度:就是确定一个好的顺序来执行 I/O 请求。因为应用程序所发布系统调用顺序不一定总是最佳选择,所以需要通过调度来改善系统的整体性能。主要是通过重新安排任务队列顺序以改善系统总体调用。
引入缓存:引入缓冲后可以降低设备对 CPU 的中断频率,放宽对中断响应时间的限制。
缓存的分类
- 单缓存
- 双缓存:可以交替使用,提高并行速度
- 循环缓存
假脱机技术 #
这个是经常用到的,我们系统中有一些独占设备,然后某个进程获得了独占设备的使用权,但是却不经常使用,却又卡着让别人用不了,这就造成了资源的浪费,所以我们将独占设备改造成共享设备,提高利用率。
主要原理是,利用输入缓冲区,输入井,输出缓冲区,输出井来完成。
操作系统中的时钟是什么 #
时钟(Clocks) 也被称为 定时器(timers),时钟/定时器对任何程序系统来说都是必不可少的。时钟负责维护时间、防止一个进程长期占用 CPU 时间等其他功能。时钟软件(clock software) 也是一种设备驱动的方式。下面我们就来对时钟进行介绍,一般都是先讨论硬件再介绍软件,采用由下到上的方式,也是告诉你,底层是最重要的。
时钟硬件 #
在计算机中有两种类型的时钟,这些时钟与现实生活中使用的时钟完全不一样。
- 比较简单的一种时钟被连接到 110 V 或 220 V 的电源线上,这样每个
电压周期会产生一个中断,大概是 50 - 60 HZ。这些时钟过去一直占据支配地位。 - 另外的一种时钟由晶体振荡器、计数器和寄存器组成,示意图如下所示
这种时钟称为 可编程时钟 ,可编程时钟有两种模式,一种是 一键式(one-shot mode),当时钟启动时,会把存储器中的值复制到计数器中,然后,每次晶体的振荡器的脉冲都会使计数器 -1。当计数器变为 0 时,会产生一个中断,并停止工作,直到软件再一次显示启动。还有一种模式是 方波(square-wave mode) 模式,在这种模式下,当计数器变为 0 并产生中断后,存储寄存器的值会自动复制到计数器中,这种周期性的中断称为一个时钟周期。
设备控制器的主要功能 #
设备控制器是一个 可编址 的设备,当它仅控制一个设备时,它只有一个唯一的设备地址;如果设备控制器控制多个可连接设备时,则应含有多个设备地址,并使每一个设备地址对应一个设备。
设备控制器主要分为两种:字符设备和块设备
设备控制器的主要功能有下面这些
- 接收和识别命令:设备控制器可以接受来自 CPU 的指令,并进行识别。设备控制器内部也会有寄存器,用来存放指令和参数
- 进行数据交换:CPU、控制器和设备之间会进行数据的交换,CPU 通过总线把指令发送给控制器,或从控制器中并行地读出数据;控制器将数据写入指定设备。
- 地址识别:每个硬件设备都有自己的地址,设备控制器能够识别这些不同的地址,来达到控制硬件的目的,此外,为使 CPU 能向寄存器中写入或者读取数据,这些寄存器都应具有唯一的地址。
- 差错检测:设备控制器还具有对设备传递过来的数据进行检测的功能。
什么是 DMA #
DMA 的中文名称是 直接内存访问,它意味着 CPU 授予 I/O 模块权限在不涉及 CPU 的情况下读取或写入内存。也就是 DMA 可以不需要 CPU 的参与。这个过程由称为 DMA 控制器(DMAC)的芯片管理。由于 DMA 设备可以直接在内存之间传输数据,而不是使用 CPU 作为中介,因此可以缓解总线上的拥塞。DMA 通过允许 CPU 执行任务,同时 DMA 系统通过系统和内存总线传输数据来提高系统并发性。
直接内存访问的特点 #
DMA 方式有如下特点:
- 数据传送以数据块为基本单位
- 所传送的数据从设备直接送入主存,或者从主存直接输出到设备上
- 仅在传送一个或多个数据块的开始和结束时才需 CPU 的干预,而整块数据的传送则是在控制器的控制下完成。
DMA 方式和中断驱动控制方式相比,减少了 CPU 对 I/O 操作的干预,进一步提高了 CPU 与 I/O 设备的并行操作程度。
DMA 方式的线路简单、价格低廉,适合高速设备与主存之间的成批数据传送,小型、微型机中的快速设备均采用这种方式,但其功能较差,不能满足复杂的 I/O 要求。
其它补充 #
Linux 的同步机制 #
🌟I/O 多路复用 #
- 边缘触发
- 水平触发
🌟大端序小端序 #
🌟零拷贝 #
BIO(同步阻塞)、NIO(同步非阻塞)、AIO(异步非阻塞) #
- BIO 堵塞 IO:发现被使用,则一直等待
- NIO:发现被使用,先去干别的,然后每隔一段时间再回来,然后看看用完没。
- AIO:发现被使用,先去干别的,等结束了我通知你,你再回来
并发和并行的区别 #
- 并发(concurrency):指宏观上看起来两个程序在同时运行,比如说在单核 cpu 上的多任务。但是从微观上看两个程序的指令是交织着运行的,指令之间交错执行,在单个周期内只运行了一个指令。这种并发并不能提高计算机的性能,只能提高效率(如降低某个进程的相应时间)。
- 并行(parallelism):指严格物理意义上的同时运行,比如多核 cpu,两个程序分别运行在两个核上,两者之间互不影响,单个周期内每个程序都运行了自己的指令,也就是运行了两条指令。这样说来并行的确提高了计算机的效率。所以现在的 cpu 都是往多核方面发展。
什么是信号 #
一个信号就是一条小消息,它通知进程系统中发生了一个某种类型的事件。 Linux 系统上支持的 30 种不同类型的信号。 每种信号类型都对应于某种系统事件。低层的硬件异常是由内核异常处理程序处理的,正常情况下,对用户进程而言是不可见的。信号提供了一种机制,通知用户进程发生了这些异常。
发送信号:内核通过更新目的进程上下文中的某个状态,发送(递送)一个信号给目的进程。发送信号可以有如下两种原因:
- 内核检测到一个系统事件,比如除零错误或者子进程终止。
- —个进程调用了 kill 函数, 显式地要求内核发送一个信号给目的进程。一个进程可以发送信号给它自己。
接收信号:当目的进程被内核强迫以某种方式对信号的发送做出反应时,它就接收了信号。进程可以忽略这个信号,终止或者通过执行一个称为信号处理程序(signal handler)的用户层函数捕获这个信号。
操作系统中用到了什么排序算法 #
进程调度:堆排序
文件系统排序:快速排序/归并排序
I/O 调度算法:插入排序/归并排序
内存管理:基数排序(变种)
网络协议栈:计数排序应用
了解的 I/O 模型有哪些 #
注:I/O 多路复用中,select/epoll 调用本身是阻塞的,但可监听多个 I/O。
阻塞 I/O
- 调用 I/O 操作时,线程一直等待,直到数据就绪或操作完成。
- 期间线程无法执行其他任务(CPU 闲置)。
非阻塞 I/O
- 调用 I/O 操作时,若数据未就绪,立即返回错误(如
EWOULDBLOCK)。 - 线程需轮询检查数据是否就绪(消耗 CPU)。
- 线程可执行其他任务(但需主动轮询)。
- 调用 I/O 操作时,若数据未就绪,立即返回错误(如
I/O 多路复用
- 使用
select/poll/epoll等系统调用,单线程监听多个 I/O 事件。 - 当某个 I/O 就绪时,通知线程处理。
- 使用
常见的 I/O 多路复用机制 #
select #
跨平台:支持所有主流操作系统(Linux/Windows/macOS)。
基于轮询:通过遍历文件描述符集合(
fd_set)检查就绪状态。限制:
- 单个进程最多监听 1024 个文件描述符(FD)。
- 每次调用需全量拷贝
fd_set到内核。
fd_set read_fds;
FD_ZERO(&read_fds);
FD_SET(fd1, &read_fds); _// 添加监听 fd_
int ret = select(fd1 + 1, &read_fds, NULL, NULL, NULL); _// 阻塞等待_
if (FD_ISSET(fd1, &read_fds)) { _/* 处理就绪的 fd */_ }
- 缺点
- O(n) 时间复杂度:每次遍历所有 FD,性能随 FD 数量线性下降。
- 重复初始化:每次调用需重新设置
fd_set。
poll #
- 改进
select的 FD 数量限制,使用链表存储 FD(理论无上限)。 - 仍需要遍历所有 FD 检查就绪状态(O(n) 时间复杂度)。
struct pollfd fds[2];
fds[0].fd = fd1; fds[0].events = POLLIN;
int ret = poll(fds, 2, timeout); _// 阻塞等待_
if (fds[0].revents & POLLIN) { _/* 处理就绪的 fd */_ }
对比 select
epoll(Linux 专属) #
- 事件驱动:内核通过回调机制直接通知就绪的 FD,无需遍历(O(1) 时间复杂度)。
- 高效内存:使用红黑树管理 FD,支持水平触发(LT)和边缘触发(ET)模式。
核心函数
epoll_create():创建 epoll 实例。epoll_ctl():添加/修改/删除监听的 FD。epoll_wait():等待就绪事件。
int epfd = epoll_create1(0);
struct epoll_event ev, events[10];
ev.events = EPOLLIN; ev.data.fd = fd1;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd1, &ev); _// 注册 fd_
int ret = epoll_wait(epfd, events, 10, timeout); _// 等待事件_
for (int i = 0; i < ret; i++) { _/* 处理 events[i] */_ }
触发模式
- 水平触发:只要 FD 可读/可写,epoll_wait() 会持续通知(默认模式,类似 poll)。
- 边沿触发:仅在 FD 状态变化时通知一次(需一次性处理完数据,否则可能丢失事件)。
优点
- 高性能:支持百万级并发(如 Nginx、Redis)。
- 低开销:无需每次调用传递所有 FD。
kqueue(FreeBSD/macOS 专属) #
- 类似
epoll,但使用事件队列机制,支持更多事件类型(如文件修改、信号)。 - 代码复杂度较高,但功能更强大。
struct kevent ev, events[10];
int kq = kqueue();
EV_SET(&ev, fd1, EVFILT_READ, EV_ADD, 0, 0, NULL);
kevent(kq, &ev, 1, NULL, 0, NULL); _// 注册 fd_
int ret = kevent(kq, NULL, 0, events, 10, &timeout); _// 等待事件_
对比 epoll
IOCP(Windows 专属) #
- 基于异步 I/O 的多路复用模型,与
epoll/kqueue设计哲学不同。 - 需配合完成端口(Completion Port)使用,适合高吞吐场景。
- 线程池从完成端口获取已完成的 I/O 操作,而非主动监听 FD。
总结对比 #
计算机网络综合考点 #
🌟请描述一下 OSI 七层协议 #
物理层(Physical Layer)
物理层是 OSI 模型的最底层,主要负责处理物理介质上的信号传输。它定义了物理连接的机械、电气、功能和规程特性。
数据链路层(Data Link Layer)
数据链路层负责将物理层接收到的原始信号转换为数据帧,并进行差错检测和纠正。它在物理层提供的物理连接基础上,建立相邻节点之间的数据链路
网络层(Network Layer)
网络层负责将数据从源节点传输到目标节点,主要功能是进行路由选择和分组转发。它根据网络的拓扑结构和通信协议,确定数据传输的最佳路径,使得不同网络之间能够相互通信。
网络层协议如 IP(Internet Protocol)协议,为每个连接到网络的设备分配一个唯一的 IP 地址。当一个设备要向另一个设备发送数据时,网络层会根据目标设备的 IP 地址和当前网络的路由信息,选择合适的路径来转发数据包。
在互联网中,数据包可能需要经过多个路由器才能从源主机到达目标主机,网络层的路由器会根据路由表进行数据包的转发决策。
传输层(Transport Layer)
传输层提供端到端的通信服务,确保数据能够正确、有序地从源端应用程序传输到目的端应用程序。
它在不同主机的应用程序之间建立逻辑连接,对上层屏蔽了下层网络的细节,使得应用程序只需要关注数据的传输,而不需要关心网络的具体实现。
传输层有两个主要协议,TCP 和 UDP 是一种面向连接的、可靠的传输协议,它通过三次握手建立连接,使用序列号和确认号来保证数据的可靠传输和顺序性,还提供流量控制和拥塞控制机制。
是一种无连接的、不可靠的传输协议,它不保证数据的顺序和完整性,但具有传输速度快的特点,适用于对实时性要求较高、对数据丢失不太敏感的应用场景,如实时视频流、音频通话等
会话层(Session Layer)
会话层主要负责建立、维护和管理会话。会话是指两个或多个通信实体之间为完成一次完整的通信过程而建立的逻辑连接,包括会话的建立、会话的同步和会话的拆除等操作
这块考差不多
表示层(Presentation Layer)
表示层主要处理数据的表示、转换和加密等功能。它负责将应用层的数据转换为适合在网络上传输的格式,或者将从网络接收到的数据转换为应用层能够理解的格式,同时还可以对数据进行加密、解密、压缩、解压缩等操作。
考察不多
应用层(Application Layer)
应用层是 OSI 模型的最高层,它直接面向用户的应用程序,为用户提供各种网络服务,如文件传输、电子邮件、远程登录、网页浏览等。应用层协议规定了应用程序如何使用网络进行通信,它是用户和网络之间的接口。
常见的应用层协议有 HTTP、FTP、SMTP 等。例如,当用户在浏览器中输入一个网址时,浏览器通过 HTTP 协议与网站服务器进行通信,请求网页内容并将其显示给用户。
在电子邮件应用中,SMTP 协议用于发送邮件,POP3(Post Office Protocol 3)或 IMAP(Internet Message Access Protocol)协议用于接收邮件。
每一层的作用有可能做为单独考点
关键对比维度补充 #
简述 TCP/IP 五层协议 #
这个问题参考上面的回答即可
请说一下 REST API
REST API 是一种软件架构风格,用于构建分布式系统中的网络应用程序。REST API 是基于 REST 架构风格设计的应用程序接口。
它通过使用 HTTP 协议的方法(如 GET、POST、PUT、DELETE)来对资源进行操作,这些资源可以是任何类型的数据,如文本、图像、数据库记录等。
以下是一段 flask 示例
from flask import Flask, request, jsonify
app = Flask(__name__)
books = {}
## 创建书籍(对应POST方法)
@app.route('/books', methods=['POST'])
def create_book():
data = request.get_json()
book_id = data.get('id')
title = data.get('title')
author = data.get('author')
if book_id and title and author:
books[book_id] = {
'title': title,
'author': author
}
return jsonify({"message": "Book created successfully", "book": books[book_id]}), 201
return jsonify({"message": "Invalid data"}), 400
## 获取所有书籍(对应GET方法)
@app.route('/books', methods=['GET'])
def get_books():
return jsonify({"books": list(books.values())})
## 获取单本特定书籍(对应GET方法)
@app.route('/books/<int:book_id>', methods=['GET'])
def get_book(book_id):
if book_id in books:
return jsonify({"book": books[book_id]})
return jsonify({"message": "Book not found"}), 404
## 更新书籍(对应PUT方法)
@app.route('/books/<int:book_id>', methods=['PUT'])
def update_book(book_id):
if book_id in books:
data = request.get_json()
title = data.get('title')
author = data.get('author')
if title:
books[book_id]['title'] = title
if author:
books[book_id]['author'] = author
return jsonify({"message": "Book updated successfully", "book": books[book_id]}), 200
return jsonify({"message": "Book not found"}), 404
## 删除书籍(对应DELETE方法)
@app.route('/books/<int:book_id>', methods=['DELETE'])
def delete_book(book_id):
if book_id in books:
del books[book_id]
return jsonify({"message": "Book deleted successfully"}), 200
return jsonify({"message": "Book not found"}), 404
if __name__ == '__main__':
app.run(debug=True)
应用层 #
HTTP #
🌟请说一下 HTTP 的状态码? #
- 301:永久重定向
- 302:临时重定向
- 400:语法错误
- 401:表示需要认证
- 403:表示请求被拒绝
- 404:没发现资源
- 500:服务器内部出现故障
- 503:服务器正在维护,或者已经超载
🌟请说下转发和重定向的区别? #
先简单说下转发的含义
在 Web 开发领域,转发(Forward)主要是指服务器端的一种操作。
当服务器收到客户端(如浏览器)的请求时,它可以将这个请求从一个 Web 组件(如一个 Servlet 或 JSP 页面)传递到另一个 Web 组件进行处理。
请求次数:
URL 显示:
数据共享范围:
请说一下 HTTP 长连接和短链接 #
- 短链接:每进行一次 HTTP 通信,就要断开一次 TCP 连接
- 持久连接:建立一次 TCP 连接后进行多次请求和响应的交互,HTTP 头部添加以下配置
Connection:keep-alive
🌟GET 和 POST 请求方式有什么不同? #
Http 常用的请求方法共有 8 种,
- 在 HTTP1.0 中,定义了三种请求方法:
GET、POST和HEAD方法。 - 在 HTTP1.1 中,新增了五种请求方法:
OPTIONS、PUT、DELETE、TRACE和CONNECT方法 但我们常用的一般就是GET和POST请求。
我们常用的 GET,POST 的区别:
GET有长度限制POST比GET安全,因为GET的数据是直接在 URL 中暴露出来的。POST数据不会显示在URL中,是放在Request body中。- 参数类型:
GET只支持ASCLL码,POST没有要求。 GET请求会保存在浏览器记录里,POST浏览器也不会保存。GET只支持URL编码,POST则没有限制GET会被浏览器主动缓存,POST则不会GET回退是无害的,POST则是再次发出请求。
GET有没有Request Body呢? #
没有,因为 GET 是直接把参数暴露在外面的,但是浏览器对 URL 的大小限制为 2K,所以如果长度太大,也就是 URL 参数较多,则有可能不被接收。
有人说 POST 比 GET 安全,这是因为 POST 的数据在地址栏 URL 中看不到。它其实在 HTTP 中,他们两个都是不安全的,因为 HTTP 是明文传输。
GET和POST请求发送的数据包有什么不同? #
GET 是一个包将 Header 和 body 同时发送过去,POST 是先发送 head,再发送 body,分两个包发送。
就像是 GET 只需要汽车跑一趟就把货送到了,而 POST 得跑两趟,第一趟,先去和服务器打个招呼老铁,我等下要送一批货来,你们准备接收一下哈,然后第二趟再回头把货送过去。
GET 和参数有没有大小限制呢?
在 HTTP 协议规范本身,并没有严格规定 GET 方法参数大小的限制。
这是因为 HTTP 协议主要关注的是请求 - 响应的通信机制,而不是对参数大小进行强制约束。
理论上,只要网络、服务器和客户端软件等支持,GET 方法可以传递很长的参数。
但是这只是理论上 实际应用中浏览器会对其进行限制,不同的浏览器对 GET 请求的 URL 长度(包括参数部分)有不同的限制。
因为如果 URL 过长,可能会导致浏览器性能下降,如地址栏显示问题、历史记录存储问题等,同时也可能增加安全风险,例如某些恶意的超长 URL 可能用于攻击。
服务器软件也可能对 GET 请求的参数大小进行限制。例如,Apache 服务器默认有一个对 URL 长度的限制设置,虽然这个设置可以通过配置文件进行调整,但在默认情况下,如果 GET 请求的参数过长,可能会导致服务器返回 414(Request - URI Too Long)错误。
网络中的一些中间设备,如代理服务器、防火墙等,也可能对 URL 长度进行限制。这些设备在处理网络流量时,如果遇到过长的 GET 请求 URL,可能会截断请求或者返回错误信息。这是为了防止某些恶意的超长 URL 对网络安全和性能造成威胁,同时也是为了避免这些设备自身的资源被过度占用。
请说一下 HTTP 1.1 的特点 #
HTTP1.0 和 HTTP 1.1 的一些区别
HTTP1.0 最早在网页中使用是在 1996 年,那个时候只是使用一些较为简单的网页上和网络请求上,而 HTTP1.1 则在 1999 年才开始广泛应用于现在的各大浏览器网络请求中,同时 HTTP1.1 也是当前使用最为广泛的 HTTP 协议。 主要区别主要体现在:
- 缓存处理:在 HTTP1.0 中主要使用 header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
- 带宽优化及网络连接的使用,错误通知的管理:在 HTTP1.1 中新增了 24 个错误状态响应码,如 409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
- 长连接:HTTP 1.1 支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个 TCP 连接上可以传送多个 HTTP 请求和响应,减少了建立和关闭连接的消耗和延迟,在 HTTP1.1 中默认开启 Connection: keep-alive,一定程度上弥补了 HTTP1.0 每次请求都要创建连接的缺点。
- Host 头处理:在 HTTP1.0 中认为每台服务器都绑定一个唯一的 IP 地址,因此,请求消息中的 URL 并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个 IP 地址。HTTP1.1 的请求消息和响应消息都应支持 Host 头域,且请求消息中如果没有 Host 头域会报告一个错误(400 Bad Request)。
请说一下 HTTP 2.0 的特点 #
二进制编码:HTTP/2 厉害的地方在于将 HTTP/1 的文本格式改成二进制格式传输数据,极大提高了 HTTP 传输效率,而且二进制数据使用位运算能高效解析,这里一句话总结就是,将侦使用二进制格式传输。 header 压缩:
HTTP/2 没使用常见的 gzip 压缩方式来压缩头部,而是开发了 HPACK 算法,HPACK 算法主要包含三个组成部分:
- 静态字典;
- 动态字典;
- Huffman 编码(压缩算法)
客户端和服务器两端都会建立和维护字典,用长度较小的索引号表示重复的字符串,再用 Huffman 编码压缩数据,可达到 50%~90% 的高压缩率。静态表是保存在 http2 框架里的。
多路复用分侦(server push):HTTP 2.0 其实是将三个请求变成三个流,将数据分成帧,乱序发送到一个 TCP 连接中。将一个请求变成一个流,然后再将流拆分成侦,然后这些侦是可以混杂在一起进行发送。
服务端主动发送:可以在用户请求 html 时,可以主动的推送 css 资源,一次请求,多次发送。
http3.0 QUIC 和之前有不同? #
http 多是基于 TCP 的传输,因为 HTTP 2.0 也是基于 TCP 协议的,TCP 协议在处理包时是有严格顺序的。当其中一个数据包遇到问题,TCP 连接需要等待这个包完成重传之后才能继续进行。
虽然 HTTP 2.0 通过多个 stream,使得逻辑上一个 TCP 连接上的并行内容,进行多路数据的传输,然而这中间并没有关联的数据。一前一后,前面 stream 2 的帧没有收到,后面 stream 1 的帧也会因此阻塞。
基于 UDP 自定义的类似 TCP 的连接
一条 TCP 连接是由四元组标识的,分别是源 IP、源端口、目的 IP、目的端口。ip 改变之后连接断开
QUIC 自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个 64 位的随机数作为 ID 来标识,而且 UDP 是无连接的,所以当 IP 或者端口变化的时候,只要 ID 不变,就不需要重新建立连接。
重发
tcp 的重发是有缺陷的,发送端发送一个数据包,由于网络堵塞,发送失败,进行重传之后,接收端收到包之后,不知道应该如何计算往返时间,不利于我们拥塞控制。
这里加入了,偏移量和 id,重发之后加 1 即可。
HTTP 协议版本对比 #
多路复用
有了自定义的连接和重传机制,我们就可以解决上面 HTTP 2.0 的多路复用问题。同 HTTP 2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求。但是,QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。这样,假如 stream2 丢了一个 UDP 包,后面跟着 stream3 的一个 UDP 包,虽然 stream2 的那个包需要重传,但是 stream3 的包无需等待,就可以发给用户。
流量控制技术
在 TCP 协议中,接收端的窗口的起始点是下一个要接收并且 ACK 的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为 TCP 的 ACK 机制是基于序列号的累计应答,一旦 ACK 了一个序列号,就说明前面的都到了,所以只要前面的没到,后面的到了也不能 ACK,就会导致后面的到了,也有可能超时重传,浪费带宽。
只要收到的,就进行确认,因为后面的到了,前面的肯定已经发送,所以我们可以移动窗口,等待确认前面的和重发即可。
HTTP 的缺点 #
- 明文传输
- 没有校验,有可能被篡改
- 没有验证通信方身份
HTTPS 采用混合加密机制,位于 HTTP/TCP 之间,主要为高层协议服务。
安全性问题
- 数据明文传输:HTTP 协议以明文方式传输数据。在这个过程中,数据包括请求信息(如用户登录的账号和密码、用户提交的各种表单内容)和响应信息(如服务器返回的包含用户敏感信息的内容)都是未经加密的。
- 缺乏身份验证机制:HTTP 本身没有提供足够强大的身份验证机制来确保通信双方的身份真实可靠。当客户端与服务器进行通信时,很难验证对方是否是真正的目标服务器或者合法的客户端。这使得服务器容易受到中间人攻击,攻击者可以伪装成合法的客户端或者服务器,获取和篡改数据。
性能和效率方面的局限
- 无状态性带来的额外开销:HTTP 是无状态协议,这意味着每个请求都是独立的,服务器不会记住之前和同一个客户端的交互情况。为了实现需要状态信息的功能,如用户登录状态的保持、购物车数据的维护等,就需要使用额外的技术,如 Cookie 或者 Session,这增加了系统的复杂性和开销。
- 头信息的限制和开销:HTTP 请求和响应头信息(Header)有一定的格式和大小限制。头信息中包含了很多重要的信息,如请求的方法(GET、POST 等)、资源的类型、缓存控制信息等。
- 然而,这些头信息可能会变得冗长,尤其是在现代复杂的 Web 应用中,可能会包含大量的自定义头信息。过多或过长的头信息会增加网络传输的开销,并且在一些情况下,可能会受到服务器或者代理的限制,影响请求的正常发送和接收。
不适合实时性要求高的场景
- 请求 - 响应模式的延迟:HTTP 采用请求 - 响应的通信模式。这意味着客户端必须先发送请求,然后等待服务器的响应。在一些实时性要求很高的场景中,如实时视频流传输、在线游戏的实时操作等,这种模式会带来明显的延迟。
无法主动推送信息:HTTP 协议本身没有提供服务器主动向客户端推送信息的机制。在很多现代 Web 应用中,如股票行情实时更新、新闻实时推送等场景,需要服务器能够及时地将最新信息发送给客户端,而 HTTP 无法很好地满足这一需求。需要借助其他技术(如长轮询、WebSocket 等)来实现类似的功能。
HTTP 与 HTTPS 核心特性对比 #
HTTP 的固有缺陷详解 #
🌟请说一下 HTTP 请求过程 #
域名解析获取 IP 地址
- 浏览器按顺序查找域名对应的 IP 地址,依次搜索浏览器缓存、系统缓存、路由器缓存、ISP DNS 缓存。
建立 TCP 连接(三次握手)
- 客户端与服务器通过 TCP 的三次握手建立连接,为 HTTP 请求传输做准备。
发送 HTTP 请求
- 请求报文组成:由请求行、请求头部、空行和请求数据(GET 方法一般无请求数据)组成。
- 请求行:包含请求方法(如 GET、POST 等)、URL 和协议版本。
- GET 用于读取文档,请求参数附在 URL 后,有长度限制且不适合私密数据传输;POST 用于向服务器提供较多信息,参数封装在请求数据中,可传输大量数据且不显示在 URL 中。
- URL 由协议、主机、端口(HTTP 默认 80 可省略)、路径和参数组成。
- 协议版本常见有 HTTP/1.0 和 HTTP/1.1。
- 请求头部:由 “名 / 值” 对组成,每行一对,名和值用冒号分隔,最后有空行,包含如 Host、User - Agent 等信息。
- 请求数据(POST 方法):与 Content - Type 和 Content - Length 等请求头部相关,数据格式如 application/x - www - form - urlencoded。
服务器处理请求并响应
- 响应报文组成:由状态行、响应头部、空行和响应数据组成。
- 状态行:包含协议版本、状态码(如 200 表示成功、404 表示未找到等)和状态码描述。
- 响应头部:包含如 Server、Content - Type 等信息。
- 响应数据:存放返回给客户端的数据,如 HTML 代码等。
浏览器后续操作
- 解析 HTML 代码,遇到静态资源则向服务器请求下载。
- 渲染静态资源和 HTML 代码,呈现页面给用户,最后关闭 TCP 连接(通过四次挥手)。
可视化流程 #
🌟能不能详细介绍一下 HTTPS ? #
HTTPS 的基本概念与作用
定义:HTTPS(Hypertext Transfer Protocol Secure)即超文本传输安全协议,是在 HTTP 协议基础上加入 SSL/TLS 协议,通过加密通信和身份认证来保障数据传输安全的网络协议。
作用:主要用于保护用户与网站之间的数据交换安全,防止数据被窃取、篡改或伪造。例如,在网上银行进行交易时,用户输入的账号、密码、交易金额等敏感信息通过 HTTPS 加密后传输,确保只有银行服务器能够解密获取真实信息,有效防止黑客在网络传输过程中截获并窃取用户资金。
加密机制
对称加密与非对称加密结合:
- 对称加密:在 HTTPS 中,对称加密用于加密实际传输的数据内容。它使用相同的密钥进行加密和解密,具有加密和解密速度快的优点,适用于对大量数据进行快速加密处理。例如,在传输一段较长的网页文本内容时,采用对称加密可以高效地对其进行加密保护。常用的对称加密算法有 AES(Advanced Encryption Standard)等。
- 非对称加密:主要用于在客户端和服务器首次建立连接时交换对称加密密钥。非对称加密使用公钥和私钥两个不同的密钥,公钥可以公开,任何人都可以用公钥对数据进行加密,但只有持有私钥的一方才能解密。例如,服务器将自己的公钥发送给客户端,客户端用公钥加密对称加密密钥后发送给服务器,服务器再用私钥解密获取对称加密密钥。这样,即使公钥在传输过程中被黑客获取,黑客也无法解密后续用对称加密密钥加密的数据。常用的非对称加密算法有 RSA 等。
数字证书与证书颁发机构(CA):
- 数字证书:服务器向客户端证明其身份时使用数字证书。数字证书包含服务器的公钥、服务器信息(如域名等)以及证书颁发机构的数字签名等内容。例如,当用户访问一个电商网站时,服务器会向用户的浏览器发送其数字证书,浏览器通过验证证书中的信息来确认是否信任该服务器。
- 证书颁发机构(CA):是可信的第三方机构,负责为服务器颁发数字证书并对其真实性进行验证。CA 使用自己的私钥对服务器的数字证书进行签名,客户端浏览器内置了多个知名 CA 的公钥,用于验证服务器数字证书的签名是否有效。如果签名有效且证书中的服务器信息与实际访问的服务器相符,浏览器就认为服务器是可信的。
工作流程
- 客户端发起 HTTPS 请求:用户在浏览器中输入一个以 “https://” 开头的网址,浏览器向服务器的 443 端口(HTTPS 默认端口)发送连接请求,开始 HTTPS 通信。
- 服务器响应并发送数字证书:服务器收到请求后,将包含公钥的数字证书发送给客户端。
- 客户端验证数字证书:客户端收到数字证书后,使用本地存储的 CA 公钥验证证书的签名是否有效,同时检查证书中的服务器信息(如域名)是否与正在访问的服务器一致。如果验证失败,浏览器会提示用户证书存在问题,可能存在安全风险;如果验证成功,则继续下一步。
- 生成对称加密密钥并交换:客户端生成一个对称加密密钥,用服务器的公钥对其进行加密后发送给服务器。服务器收到后,用自己的私钥解密获取对称加密密钥。
- 使用对称加密进行数据传输:此后,客户端和服务器之间就使用对称加密密钥对传输的数据进行加密和解密,确保数据在网络传输过程中的保密性和完整性。
HTTPS 核心机制详解 #
加密机制 #
数字证书体系 #
HTTPS 工作流程分步解析 #
安全特性对比 #
HTTPS 与 HTTP 的区别 #
- 安全性:HTTP 以明文形式传输数据,容易被窃取和篡改;HTTPS 通过加密和身份认证保障数据安全,有效防止中间人攻击等安全威胁。例如,在未加密的 HTTP 下,黑客可以轻易截获用户在登录页面输入的账号密码;而在 HTTPS 下,这些信息被加密传输,黑客难以获取真实内容。
- 端口号:HTTP 默认使用 80 端口,HTTPS 默认使用 443 端口。
- 搜索引擎优化(SEO)影响:搜索引擎通常更倾向于将使用 HTTPS 的网站排在搜索结果的前列,因为 HTTPS 代表网站更注重用户数据安全,这在一定程度上有助于提高网站的访问量和排名。
DNS #
🌟请说一下在浏览器输入网址显示页面的过程 #
整体流程如图:
- 查询浏览器缓存,如果有直接访问
- 查询本地 host 文件,查询本地缓存,或者使用 cmd ,使用 ipconfig /displaydns 命令查询
- 向 DNS 服务器发送 DNS 请求,查询本地 DNS 服务器(此时用到的是递归查询),这其中用的是 UDP 的协议
- 本地域名服务器会向
根域名服务器发送一个请求,如果根域名服务器也不存在该域名时, - 本地域名会向顶级域名服务器的下一级 DNS 服务器发送一个请求,依次类推下去。直到最后本地域名服务器得到 google 的 IP 地址并把它缓存到本地,供下次查询使用。(上诉的迭代方式是迭代查询)
- 此时我们已经知道了 ip 地址,及其默认的端口号,http 默认的是 80 端口,https 默认的是 https 端口
- 我们首先会尝试使用 http 建立 socket 连接,三次握手之后,开始传送数据,如果是 http 的话,那么则接收数据,如果不是 http,是 https 则会返回 3 开头的重定向,将端口号从 80 端口改成 443 端口,并四次挥手断开之前的连接。
- 再来一遍三次握手,此时还会采用 SSL 的加密技术来保证传输数据的安全性,保证数据传输过程中不被修改或者替换之类的
- 沟通好双方使用的认证算法,加密和检验算法,在此过程中也会检验对方的 CA 安全证书。
- 连接完毕,开始传输数据
🌟 请简单介绍一下 Cookie #
Cookie 是一种存储在用户本地终端(通常是浏览器)上的小文本文件,用于记录用户的某些信息或状态。它由服务器发送给浏览器,浏览器会根据服务器设置的规则(如有效期、作用域等)来存储和发送 Cookie。
当用户第一次访问某个网站时,服务器可以通过在响应头中添加 Set - Cookie 字段来发送 Cookie 信息给浏览器。
之后,当浏览器再次访问该网站的同一域名下的页面时,会在请求头中自动带上存储的 Cookie 信息。服务器通过读取这个 Cookie 信息,就可以识别出用户的身份或者其他相关状态,从而为用户提供个性化的服务,如记住用户登录状态、用户偏好设置等。
Cookie 是为了支持 Web 应用程序(如网页浏览)而设计的一种机制,用于在 HTTP 协议(应用层协议)的请求和响应过程中传递信息,帮助服务器识别和跟踪用户
🌟请简单介绍一下 Session #
Session 是一种服务器端的机制,用于在多个页面请求之间跟踪用户的状态。它是基于会话的概念,一个会话代表了用户与服务器之间的一系列交互过程,从用户开始访问网站到用户离开(如关闭浏览器或者长时间未操作)。
当用户第一次访问服务器时,服务器会为该用户创建一个唯一的会话 ID(Session ID),这个 ID 可以通过多种方式存储在服务器端,如内存、数据库或者文件系统中。
服务器会将这个 Session ID 以某种方式发送给浏览器,通常是通过在响应头中设置 Cookie(将 Session ID 作为 Cookie 的 value)来实现。
在后续的请求中,浏览器会将这个 Session ID 发送回服务器,服务器通过这个 Session ID 来查找对应的会话信息,从而获取用户的状态数据。
例如,在一个购物网站中,用户将商品加入购物车的操作会被记录在服务器端的 Session 数据中,当用户查看购物车或者结算时,服务器通过 Session ID 找到对应的购物车数据,为用户提供服务。
Session 也是工作在应用层,也是为了支持 Web 应用程序的状态管理而存在的,主要用于处理 HTTP 请求和响应过程中的用户状态跟踪。
🌟 请说一下 Cookie 和 Session 的区别与联系 #
区别:
联系
Cookie 和 Session 常常一起使用,Session ID 通常借助 Cookie 来在浏览器和服务器之间传递,使得服务器能够识别用户的会话,从而实现用户状态的跨页面跟踪。
Cookie vs Session 核心对比 #
网络层 #
通过 IP 地址发送请求的过程 #
TCP 层发送每一个报文的时候,都需要加上自己的地址(即源地址)和它想要去的地方(即目标地址)。
将这两个信息放到 IP 头里面,交给 IP 层进行传输。IP 层需要查看目标地址和自己是否是在同一个局域网。如果是,就发送 ARP 协议来请求这个目标地址对应的 MAC 地址,然后将源 MAC 和目标 MAC 放入 MAC 头,发送出去即可;如果不在同一个局域网,就需要发送到网关,还要需要发送 ARP 协议,来获取网关的 MAC 地址,然后将源 MAC 和网关 MAC 放入 MAC 头,发送出去。网关收到包发现 MAC 符合,取出目标 IP 地址,根据路由协议找到下一跳的路由器,获取下一跳路由器的 MAC 地址,将包发给下一跳路由器。
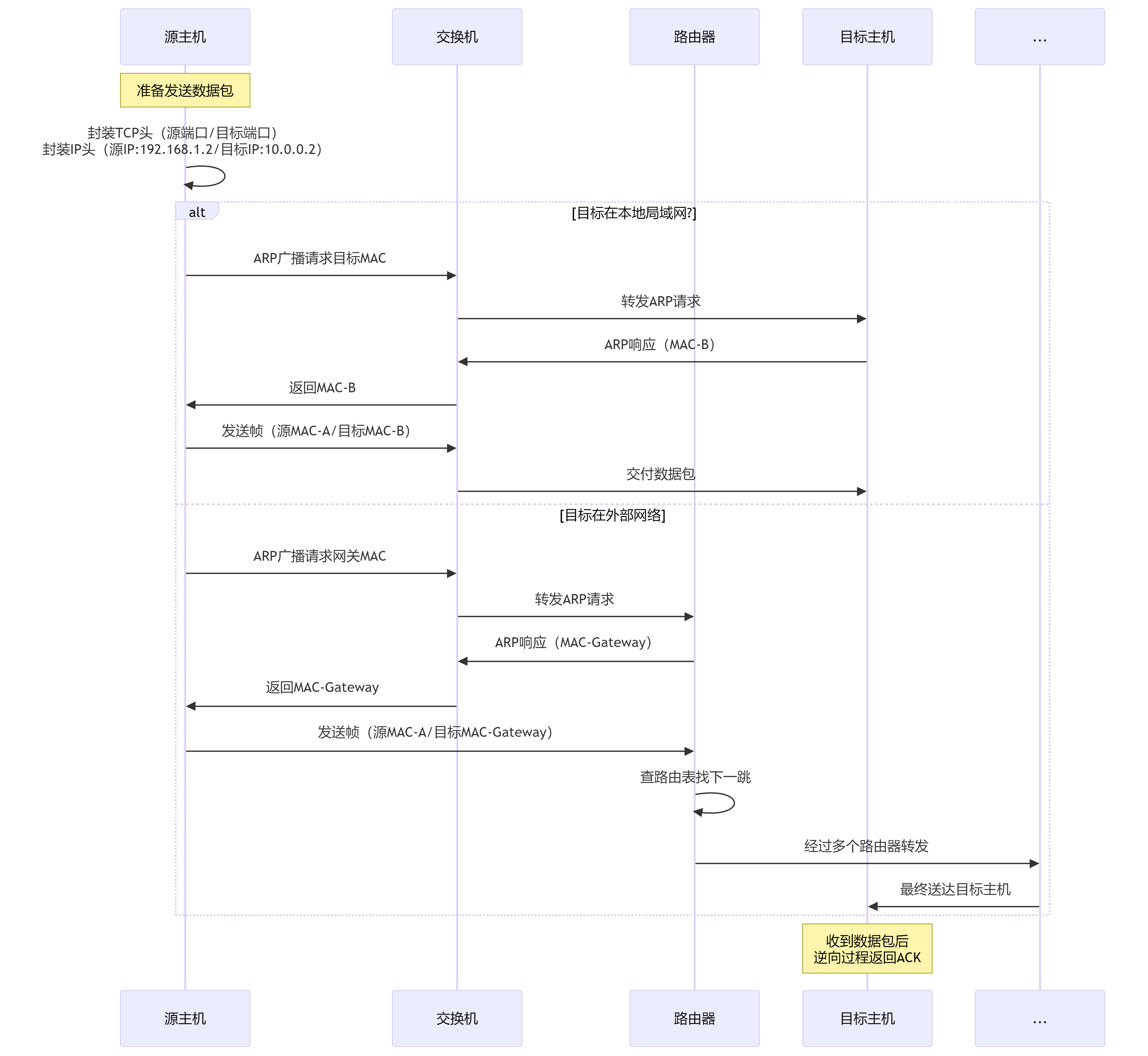
通过 IP 地址发送请求的过程 #
TCP 层发送每一个报文的时候,都需要加上自己的地址(即源地址)和它想要去的地方(即目标地址)。
将这两个信息放到 IP 头里面,交给 IP 层进行传输。IP 层需要查看目标地址和自己是否是在同一个局域网。如果是,就发送 ARP 协议来请求这个目标地址对应的 MAC 地址,然后将源 MAC 和目标 MAC 放入 MAC 头,发送出去即可;如果不在同一个局域网,就需要发送到网关,还要需要发送 ARP 协议,来获取网关的 MAC 地址,然后将源 MAC 和网关 MAC 放入 MAC 头,发送出去。网关收到包发现 MAC 符合,取出目标 IP 地址,根据路由协议找到下一跳的路由器,获取下一跳路由器的 MAC 地址,将包发给下一跳路由器。
🌟 有了 IP 地址,为什么还要用 MAC 地址? #
简而言之,标识网络中的一台计算机,比较常用的就是 IP 地址和 MAC 地址,但计算机的 IP 地址可由用户自行更改,管理起来就相对困难,而 MAC 地址不可更改,所以一般会把 IP 地址和 MAC 地址组合起来使用。
那只使用 MAC 地址不用 IP 地址行不行呢?不行的!因为最早就是 MAC 地址先出现的,并且当时并不用 IP 地址,只用 MAC 地址,后来随着网络中的设备越来越多,整个路由过程越来越复杂,便出现了子网的概念。对于目的地址在其他子网的数据包,路由只需要将数据包送到那个子网即可。
那为什么要用 IP 地址呢?是因为 IP 地址是和地域相关的,对于同一个子网上的设备,IP 地址的前缀都是一样的,这样路由器通过 IP 地址的前缀就知道设备在在哪个子网上了,而只用 MAC 地址的话,路由器则需要记住每个 MAC 地址在哪个子网,这需要路由器有极大的存储空间,是无法实现的。
IP 地址可以比作为地址,MAC 地址为收件人,在一次通信过程中,两者是缺一不可的。
传输层 #
TCP #
🌟 请你说一下 TCP 的粘包和拆包? #
在网络通信中,TCP 是一种面向连接的、可靠的、基于字节流的传输层通信协议。而 TCP 的“粘包”和“拆包”是在使用 TCP 进行数据传输时可能会遇到的现象。
一、粘包
定义
- 粘包是指在接收数据时,由于 TCP 是面向流的协议,接收方不知道消息之间的界限,可能会将多个发送方发送的数据包合并成一个数据包接收,从而导致一次接收的数据包含了多个逻辑消息。
产生原因
- 发送方发送数据的速度较快,接收方接收数据的速度相对较慢,导致多个数据包在接收方的缓冲区中被合并。
- 发送方发送的数据包较小,TCP 为了提高传输效率,可能会将多个小数据包合并成一个较大的数据包进行发送。
影响
- 如果接收方不能正确地处理粘包问题,可能会导致数据解析错误,影响程序的正常运行。
二、拆包
定义
- 拆包是指在发送数据时,由于 TCP 协议对数据长度没有限制,一个较大的数据包可能会被拆分成多个小数据包进行发送,接收方在接收数据时需要将这些小数据包重新组合成完整的数据包。
产生原因
- 发送的数据大小超过了 TCP 协议的最大传输单元(MTU),TCP 会将数据包进行拆分,以适应网络传输的要求。
- 网络拥塞等原因导致数据包丢失或延迟,接收方可能需要等待一段时间才能收到完整的数据包。
影响
- 接收方需要进行额外的处理来组合拆分后的数据包,增加了程序的复杂性。如果处理不当,可能会导致数据丢失或不完整。
总结:TCP 是面向流,没有界限的一串数据。TCP 底层并不了解上层业务数据的具体含义,它会根据 TCP 缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被 TCP 拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的 TCP 粘包和拆包问题。
TCP 粘包 vs 拆包对比 #
为什么会产生粘包和拆包呢,如何解决呢? #
要发送的数据小于 TCP 发送缓冲区的大小,TCP 将多次写入缓冲区的数据一次发送出去,将会发生粘包;接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包;
要发送的数据大于 TCP 发送缓冲区剩余空间大小,将会发生拆包;待发送数据大于 MSS(最大报文长度),TCP 在传输前将进行拆包。即 TCP 报文长度-TCP 头部长度 >MSS。
解决方案:发送端将每个数据包封装为固定长度在数据尾部增加特殊字符进行分割将数据分为两部分,一部分是头部,一部分是内容体;其中头部结构大小固定,且有一个字段声明内容体的大小。
- MTU:一个网络包的最大长度
- MSS:除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度;
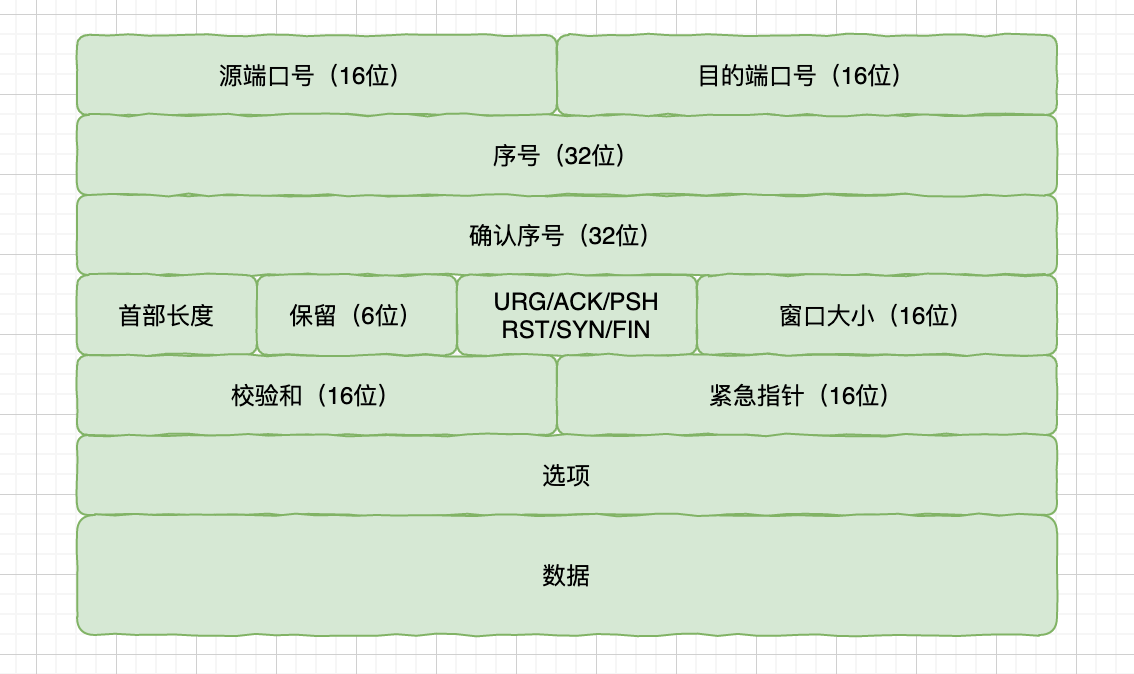
解决方法
- 定长消息:发送方和接收方约定好每个数据包的固定长度,接收方按照固定长度读取数据,不足长度的部分用特定字符填充。
- 特殊字符分隔:在发送的数据中添加特殊字符作为消息的分隔符,接收方根据分隔符来区分不同的消息。
- 消息长度前缀:在每个消息的开头添加一个表示消息长度的字段,接收方先读取长度字段,再根据长度读取相应的数据。
🌟 请说下三次握手的目的? #
TCP 三次握手主要是为了以下几个目的:
一、建立连接
确保通信双方都有发送和接收数据的能力,建立起可靠的双向连接。具体过程如下:
- 第一次握手:客户端向服务器发送一个
SYN(同步)包,该包中包含客户端选择的初始序列号(seq)。此时客户端进入SYN_SENT状态。这个步骤表明客户端有发送数据的意愿。 - 第二次握手:服务器收到客户端的
SYN包后,向客户端发送一个SYN/ACK(同步确认)包,该包中包含服务器选择的初始序列号和对客户端序列号的确认(ack = 客户端序列号 + 1)。此时服务器进入SYN_RCVD状态。这个步骤表明服务器有接收和发送数据的能力。 - 第三次握手:客户端收到服务器的
SYN/ACK包后,向服务器发送一个ACK(确认)包,该包中确认号为服务器序列号加一(ack = 服务器序列号 + 1)。此时客户端进入ESTABLISHED状态。服务器收到这个 ACK 包后也进入ESTABLISHED状态。这个步骤表明客户端确认了服务器的接收和发送能力,连接正式建立。
二、协商初始序列号
通过三次握手,双方可以确定初始序列号,确保数据传输的有序性。在后续的数据传输中,每一个数据包都有一个序列号,接收方可以根据序列号来判断数据包的顺序,并进行排序和组装。
三、防止过期连接请求的干扰
假设没有三次握手,客户端发送的一个连接请求在网络中延迟了,一段时间后这个延迟的连接请求到达服务器,服务器误以为是新的连接请求并进行响应。
如果只有两次握手,此时连接就会建立,但实际上客户端可能已经不需要这个连接了,这就会导致资源的浪费和错误的连接建立。
通过三次握手,客户端在收到服务器的响应后会再次确认,如果客户端没有发送新的连接请求,就不会进行第三次确认,服务器在一段时间后没有收到确认就会关闭连接,从而避免了这种错误情况的发生。
🌟请说下 TCP 三次握手过程 #
TCP 三次握手的过程如下:
第一次握手
客户端向服务器发送一个带有 SYN 标志的数据包。这个数据包中还会包含一个随机生成的初始序列号(sequence number,记为 seq=x),用来标识本次连接中客户端发送的数据字节流的起始位置。此时客户端进入 SYN_SENT 状态,表示客户端已准备好建立连接并等待服务器的确认。
第二次握手
服务器接收到客户端的 SYN 数据包后,知道客户端想要建立连接。服务器会向客户端发送一个带有 SYN 和 ACK 标志的数据包作为回应。这个数据包中也有一个随机生成的初始序列号(记为 seq=y),同时确认号记为 ack=x+1 是对客户端初始序列号加一,表示服务器已经接收到了客户端的 SYN 数据包,并期望下一个收到的数据包的序列号是 x+1。此时服务器进入 SYN_RCVD 状态,表示服务器正在等待客户端的确认以完成连接的建立。
第三次握手
客户端收到服务器的 SYN+ACK 数据包后,检查确认号是否正确(即确认号是否为自己发送的初始序列号加一)。如果正确,客户端会向服务器发送一个带有 ACK 标志的数据包,确认号为服务器的序列号加一(ack=y+1)。此时客户端进入 ESTABLISHED 状态,表示连接已建立成功。
服务器收到客户端的 ACK 数据包后,也进入 ESTABLISHED 状态。至此,TCP 三次握手完成,客户端和服务器之间可以开始进行数据传输。
下面是举例说明及图片描述
发送端:我发送 syn(同步序列编号)的数据包给你啦。
接收端:我已经收到你的数据包啦,我将 syn/ack 编号发送给你啦
发送端:明白,我同时将 ack 的包发送给你啦。
握手情况如下

🌟三次握手中,第二次握手的时候为什么还要传回 SYN ? #
为了确认连接请求:SYN 标志的数据包是服务器对客户端连接请求的明确确认。
当服务器收到客户端发送的 SYN 包后,回传带有 SYN 标志的数据包,表示服务器已经接收到了客户端的连接请求,并同意建立连接,让客户端知道其连接请求已被服务器认可
🌟为什么要三次握手,4 次握手可以吗? #
- 三次握手才可以阻止重复历史连接的初始化(主要原因)
- 三次握手才可以同步双方的初始序列号
- 三次握手才可以避免资源浪费
重复连接问题
因为网络会堵塞,所以有可能因为网络堵塞,第一个客户端发出第一个 SYN = 10 包之后,迟迟收不到 SYN/ACK,所以就进行补发 SYN = 20,此时服务端收到了 SYN = 10 的旧包,然后发送 ACK 和 SYN,但是呢?此时客户端发现我应该接收的是 SYN = 20 的 ACK,而不是历史的连接,所以就会发送 RST 拒绝连接,等 SYN= 20 的 ACK 来了之后,再进行连接。三次握手可以让客户端通过上下文来进行判断。
同步双方的初始序列号
序列号同步是可靠传输的基础,通过三次握手可以保证双方的序列号同步,其实四次握手也可以,只不过第二次握手把两个包合成一个了。
避免资源浪费
防止历史连接的建立,如果使用两次握手的话,现在已经连接成功,但是之前因为网络问题延迟传输的报文,再一次发到服务器则有可能再次造成连接。
TCP 建立连接时,通过三次握手能防止历史连接的建立,能减少双方不必要的资源开销,能帮助双方同步初始化序列号。序列号能够保证数据包不重复、不丢弃和按序传输。
🌟为什么不使用「两次握手」和「四次握手」? #
- 两次握手:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
- 四次握手:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
请简要介绍一下 websocket #
Websocket是一种建立在TCP协议之上的网络通信协议。TCP协议作为一种可靠的传输层协议,为Websocket提供了稳定的底层连接基础,确保数据能够准确无误地在客户端与服务器端之间传输。Websocket与 HTTP 协议有良好的兼容性。默认端口的设置上,它与HTTP协议常用的端口保持一致,即 80(用于非加密通信)和 443(用于加密通信)在网络环境中,Websocket的部署和使用无需额外为其开辟特殊端口,降低了网络配置的复杂性。Websocket的数据格式具有轻量的特点。它不像一些其他协议那样数据结构臃肿,而是以一种简洁高效的方式对要传输的数据进行封装。这种轻量的数据格式在网络传输过程中,能够减少不必要的开销,使得数据能够以更快的速度在客户端和服务器端之间传递。Websocket具备强大的数据类型支持能力,它既可以发送文本数据,也可以发送二进制数据Websocket赋予了客户端极大的通信灵活性,客户端可以与任意服务器通信。这意味着只要服务器端支持Websocket协议,客户端就可以与其建立连接并进行通信。Websocket的协议标识符是 ws(如果加密,则为 wss),这是用于在网络请求和标识中明确表示所采用的协议类型。同时,服务器网址就是 URL。在实际应用中,当客户端要与服务器建立Websocket连接时,就可以通过指定带有 ws 或 wss 协议标识符的 URL 来实现。
🌟为什么要四次挥手? #
如图
TCP 连接的双向性决定
TCP 连接是全双工通信,这意味着数据可以在两个方向上同时传输。因此,当要关闭连接时,需要考虑两个方向的数据通道的关闭。
例如,在一个网络文件传输场景中,客户端可能在向服务器上传文件的同时,服务器也在向客户端发送文件的校验信息。每个方向都有自己独立的发送和接收缓存,所以需要分别关闭这两个方向的通信通道。
确保数据传输完整
- 第一次挥手(主动关闭方发起):主动关闭连接的一方(如客户端)发送一个 FIN(结束标志)数据包,表示自己已经没有数据要发送给对方了。但是,此时它还可以接收对方(服务器)发送的数据。这就好比在一个对话中,一方先说 “我说完了”,但还可以听对方说话。
- 第二次挥手(被动关闭方回应):被动关闭方(服务器)收到 FIN 后,会发送一个 ACK(确认)数据包给主动关闭方。这是告诉主动关闭方,“我已经知道你没有数据要发送了”。不过,此时被动关闭方可能还有数据没发送完,所以它不能立刻关闭连接。就像在对话中,听到对方说 “我说完了” 后,回应 “我知道了”,但自己可能还没说完。
- 第三次挥手(被动关闭方发起):当被动关闭方(服务器)也发送完自己的数据后,它会发送一个 FIN 数据包给主动关闭方,表示自己也没有数据要发送了。这类似于对话中,自己也说完了,告诉对方 “我也说完了”。
- 第四次挥手(主动关闭方回应):主动关闭方收到被动关闭方的 FIN 后,发送一个 ACK 数据包进行确认。这样,双方都确认了彼此的数据传输已经完成,连接可以安全关闭。这就好比在对话结束时,双方都确认了彼此都已经说完,然后结束对话。
防止数据丢失和错误关闭
如果只有三次挥手,可能会出现这样的情况:被动关闭方还没来得及发送完所有数据,就收到了主动关闭方最后的确认,导致数据丢失。
四次挥手通过明确双方的数据发送状态,确保在连接关闭时,不会有数据丢失或者被错误截断的情况。
🌟为什么建立连接是三次握手,关闭连接却是四次挥手呢? #
建立连接的时候, 服务器在 LISTEN 状态下,收到建立连接请求的 SYN 报文后,把 ACK 和 SYN 放在一个报文里发送给客户端。
而关闭连接时,服务器收到对方的 FIN 报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送 FIN 报文给对方来表示同意现在关闭连接。
因此,己方 ACK 和 FIN 一般都会分开发送,从而导致多了一次.
如果已经建立了连接,但是客户端突然出现故障了怎么办? #
在 TCP 协议中,设有一个保活计时器机制来应对可能出现的客户端异常情况。当客户端与服务器建立连接后,如果长时间没有数据交互,可能会导致服务器资源的无效占用。
此时,保活计时器开始发挥作用,其初始时长通常设置为 2 小时。
在正常的数据传输过程中,每当服务器收到客户端发送的请求,保活计时器就会被重置,重新开始计时。
如果在长达 2 小时的时间内,服务器都未收到客户端传来的任何数据,此时服务器便会主动向客户端发送一个探测报文段。此后,每隔 75 秒,服务器会持续向客户端发送探测报文段,以此来检测客户端是否仍处于正常连接状态。
若服务器连续发送了 10 个探测报文段,但始终未得到客户端的任何回应,那么服务器就会判定客户端出现了故障。基于这种判断,服务器为了合理利用资源,会将与该客户端相关的连接关闭,释放相应的资源,从而避免因等待一个可能已经故障的客户端而造成资源浪费。
这种机制有效保障了服务器在面对客户端异常情况时的资源管理和连接维护。
TCP 的特点 #
提供可靠传输,实行顺序控制或重发控制机制。具有流控制、拥塞控制、提高网络利用率等众多功能。
充分实现了数据传输时各种控制功能,可以进行丢包时的重发机制,还可以对次序乱掉的分包进行顺序控制。
TCP 通过 检验和、连接管理、确认应答、 重发超时机制、序列号机制、以段为单位发送数据、窗口控制、流控制 等机制进行可靠传输。
检验和:这个原理相当于 MD5 校验,目检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
连接管理:采用三次握手的方式建立可靠的通信传输,
确认应答 : 确认应答就是会发送一条已经收到段的应答消息。
重发超时机制:这个含义在上面的序列号机制已经提到,当发送端长时间没有接收到,确认信息时,则会对该条报文进行确认,因为此时他认为,是报文发送失败。所以这个超时时间的设定就显得尤为重要。TCP 采用了一个很巧妙的方法,那就是每次发包时都会,计算往返时间及其偏差,重传的时间就是比两者之和稍大一点的值。
- RTT:往返时间
- RTO:重发时间,重发时间略大于多次 RTT 的平均值
序列号机制:当发送的数据到达接收主机时,接收端主机会返回已经收到的 ACK 确认号,确认应答。但是确认应答有可能出现以下这种情况,报文发送时丢失,确认应答信息丢失。这样就可能会导致发送端一直重发报文。
- 一般情况下,就发送端会等待一段时间后,如果没有收到确认应答,则会进行重发,但是我们也会遇到这种情况,当我们因为网络延迟之后,在我们发送方重传了报文之后,才接收到确认应答的信息,所以这样接收端就会收到无休止的重复包,所以这时候我们需要引入序列号机制,就是给每一个 TCP 报文添加一个序列号,告知发送方,我收到了哪条信息,下次传输时应该传输哪个报文。
以 MSS 为单位发送数据:建立 TCP 连接的同时,也可以确定发送数据包的单位,我们称其为最大发送长度 MSS,该值是在三次握手时计算得出的,会在两者之间选择一个都可接受的最小值,TCP 在发送数据时,重发时是以 MSS 为单位进行发送的。
流量控制,利用窗口控制提高速度:上面我们提到的,每次都要进行确认,如果往返时间较长,这会大大降低效率,所以 TCP 引入了窗口的概念,这样我们就可以使确认的不是每个分段,而是以最大的单位进行确认,就是发完一个段之后,不用等到确认信息,继续发段。
- 窗口大小就是无需等待确认应答, 而可以发送数据的最大值。当然这种情况也会出现丢失段的情况,因为 TCP 有序列号机制,所以知道哪些段需要重发,发送方的缓冲区,会将待重发的段保存到缓冲区内,知道收到确认应答。
流控制:可以让发送端根据接收端的接收实力进行发送。接收端会向发送端发送可以接收的数据大小。另外为了防止接收不到窗口更新通知,发送端则会时不时发送一个窗口探测的数据来获取窗口信息。
拥塞控制:为了进行拥塞控制,TCP 发送方要维持一个 拥塞窗口(cwnd) 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
- TCP 的拥塞控制采用了四种算法,即 慢开始 、 拥塞避免 、快重传 和 快恢复。 慢开始: 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。
cwnd初始值为 1,每经过一个传播轮次,cwnd加倍 2,4,8,16,呈指数型增长。 - 当然慢开始的
cwnd的大小不是无限制增长的,当小于 ssthresh 时,使用慢启动算法,大于等于时则启动拥塞避免算法。- 拥塞避免: 那么进入拥塞避免算法后,它的规则是:每当收到一个 ACK 时,cwnd 增加 1/cwnd。此时则变成了线性增长。
- 当报文就这么一直增长着后,网络就会慢慢进入了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。
- 当触发了重传机制,也就进入了拥塞发生算法
- 此时则采用两种方法解决丢包问题
- 超时重传:当发生了「超时重传」,则就会使用拥塞发生算法。
- 这个时候,ssthresh 和 cwnd 的值会发生变化:
ssthresh设为cwnd/2,cwnd重置为1
- 然后就重新慢启动,这大起大落不太行。
- 这个时候,ssthresh 和 cwnd 的值会发生变化:
- 快速重传:还有更好的方式,前面我们讲过「快速重传算法」。当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。
- TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,则 ssthresh 和 cwnd 变化如下:
cwnd = cwnd/2,也就是设置为原来的一半;ssthresh = cwnd;进入快速恢复算法。 - 快速恢复:快速重传和快速恢复算法一般同时使用,快速恢复算法是认为,你还能收到 3 个重复 ACK 说明网络也不那么糟糕,所以没有必要像 RTO 超时那么强烈。正如前面所说,进入快速恢复之前,cwnd 和 ssthresh 已被更新了:
cwnd = cwnd/2 ,也就是设置为原来的一半; ssthresh = cwnd;- 进入快速恢复算法如下:拥塞窗口
cwnd = ssthresh + 3( 3 的意思是确认有 3 个数据包被收到了); 重传丢失的数据包; 如果再收到重复的 ACK,那么 cwnd 增加 1; - 如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的
ssthresh的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
- 进入快速恢复算法如下:拥塞窗口
- TCP 的拥塞控制采用了四种算法,即 慢开始 、 拥塞避免 、快重传 和 快恢复。 慢开始: 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。
简单总结
- 可靠性:TCP 通过序号、确认和重传机制来确保数据的可靠传输,能够检测丢失的数据包并进行重传,保证数据的完整性和正确性。
- 面向连接:TCP 在通信双方建立连接后才能进行数据传输,连接的建立和释放都需要经过三次握手和四次挥手的过程,保证了通信的可靠性。
- 有序性:TCP 保证数据包的顺序传输和接收,接收端会按照发送端发送的顺序重新组装数据包,保证数据的有序性。
- 流量控制:TCP 通过滑动窗口机制来控制数据的传输速率,避免发送方发送过多数据导致接收方无法处理。
- 拥塞控制:TCP 通过拥塞窗口和拥塞避免算法来控制网络拥塞,避免网络过载导致数据丢失和延迟增加。
请详细说一下 TCP 的滑动窗口 #
TCP 的滑动窗口是一种流量控制机制,用于协调发送端和接收端之间的数据传输速度。
它基于窗口的概念,窗口大小代表了在不需要等待对方确认的情况下,发送端可以发送的数据量。
发送窗口主要由四个部分组成,分别是已发送并已确认、已发送但未确认、未发送但允许发送和不允许发送。
窗口大小的动态调整:发送窗口的大小不是固定不变的,它会根据接收端的反馈进行动态调整。
接收端会在确认信息(ACK)中告知发送端自己的接收窗口大小,发送端根据这个信息来调整自己的发送窗口。
滑动窗口的作用与优势
流量控制:滑动窗口机制有效地实现了发送端和接收端之间的流量控制。
通过动态调整窗口大小,发送端可以根据接收端的接收能力发送适量的数据,避免接收端缓冲区溢出导致数据丢失。例如,在网络拥塞或者接收端处理能力有限的情况下,接收端可以减小接收窗口,从而使发送端降低发送速度,保证数据传输的稳定性。
提高传输效率:滑动窗口允许发送端在收到确认信息之前发送多个数据包,不需要等待每个数据包的确认后再发送下一个,大大提高了数据传输的效率。这在高带宽、低延迟的网络环境下尤其明显,可以充分利用网络带宽,加快数据传输速度。同时,接收端也可以根据自己的处理能力和缓冲区状态灵活地接收和处理数据,进一步提高了整个传输过程的效率。

请详细说一下 TCP 的拥塞控制 #
拥塞控制是一种在计算机网络中用于防止过多的数据注入网络,避免网络性能下降的机制。
在网络中,当注入网络的流量超过网络的处理能力时,就会出现拥塞现象。
拥塞控制的目标是在网络出现拥塞时,通过合理地调整发送端的数据发送速率,使得网络能够保持良好的性能,避免死锁和网络崩溃。
拥塞产生的原因主要有以下几种,网络资源有限、拓扑和路由选择的复杂性、突发流量和流量模式的不均
拥塞控制的主要算法
慢启动(Slow - Start)
在连接建立初期,发送端不知道网络的拥塞状况,因此采用慢启动算法来逐渐增加发送窗口的大小
发送端从一个较小的初始发送窗口开始(通常为一个或几个最大报文段长度 MSS)发送数据,每当收到一个确认(ACK),就将发送窗口大小加倍。
例如,初始窗口大小为 1MSS,收到一个 ACK 后,窗口大小变为 2MSS,再收到一个 ACK,窗口大小变为 4MSS,以此类推。这种指数增长的方式可以快速探测网络的可用带宽。
慢启动的目的是在不引起网络拥塞的前提下,尽快地增加发送数据的速率。
它通过逐渐增加发送窗口大小来试探网络的承载能力,避免一开始就发送大量数据导致网络拥塞
另外为了防止发送窗口无限制地增长,设置了一个慢启动阈值(ssthresh)。当发送窗口大小超过这个阈值时,就会进入拥塞避免阶段。
拥塞避免(Congestion - Avoidance)
当发送窗口大小超过慢启动阈值后,进入拥塞避免阶段,在这个阶段,发送窗口不再是指数增长,而是线性增长。
发送端每收到一个 ACK,就将发送窗口大小增加一个 MSS 的一小部分(通常为 1/MSS)。
例如,发送窗口大小为 16MSS,每收到一个 ACK,窗口大小增加 1/16MSS,这样发送窗口会以较为缓慢的速度增长,避免过快地占用网络资源。
拥塞避免阶段的主要目的是在网络已经有一定负载的情况下,更加谨慎地增加发送数据的速率,以防止网络出现拥塞。
通过线性增长发送窗口大小,可以更好地利用网络的剩余带宽,同时降低拥塞的风险。
快重传(Fast - Retransmit)
当接收端收到一个失序的报文段时,会立即发送重复的 ACK,通知发送端这个报文段可能丢失。
如果发送端连续收到三个重复的 ACK,就会认为这个报文段确实丢失了,不等超时定时器超时,就立即重传这个丢失的报文段。
例如,发送端发送了报文段 1、2、3,接收端收到了报文段 1 和 3,但没有收到报文段 2,此时认为 2 丢失了,因为已经收到了 3,但是未收到 2,接收端就会连续发送针对报文段 1 的 ACK,当发送端收到三个这样的重复 ACK 时,就会快速重传报文段 2。
目的:快重传机制可以避免发送端等待较长的超时时间才重传丢失的报文段,从而减少数据传输的延迟,提高网络的传输效率。它能够在网络出现少量丢包的情况下,快速地恢复数据传输。
快恢复(Fast - Recovery)
快恢复机制可以在网络出现少量丢包的情况下,更快地恢复数据传输的正常速率,避免了重新进行慢启动导致的发送速率过度降低,从而提高了网络的整体性能和传输效率。
与传统的慢启动过程相比,它不需要从一个很小的初始窗口重新开始增长,而是基于网络可能还有一定传输能力的判断,发送端将慢启动阈值(ssthresh)设置为当前发送窗口大小的一半,然后将发送窗口大小设置为新的 ssthresh 加上 3 个 MSS(这是因为收到了三个重复的 ACK,说明网络可能还可以传输一定的数据)。
之后,发送端在拥塞避免阶段的规则下继续增加发送窗口大小。
请详细说一下 TCP 的拥塞控制 #
拥塞控制是一种在计算机网络中用于防止过多的数据注入网络,避免网络性能下降的机制。
在网络中,当注入网络的流量超过网络的处理能力时,就会出现拥塞现象。
拥塞控制的目标是在网络出现拥塞时,通过合理地调整发送端的数据发送速率,使得网络能够保持良好的性能,避免死锁和网络崩溃。
拥塞产生的原因主要有以下几种,网络资源有限、拓扑和路由选择的复杂性、突发流量和流量模式的不均
拥塞控制的主要算法
慢启动(Slow - Start)
在连接建立初期,发送端不知道网络的拥塞状况,因此采用慢启动算法来逐渐增加发送窗口的大小
发送端从一个较小的初始发送窗口开始(通常为一个或几个最大报文段长度 MSS)发送数据,每当收到一个确认(ACK),就将发送窗口大小加倍。
例如,初始窗口大小为 1MSS,收到一个 ACK 后,窗口大小变为 2MSS,再收到一个 ACK,窗口大小变为 4MSS,以此类推。这种指数增长的方式可以快速探测网络的可用带宽。
慢启动的目的是在不引起网络拥塞的前提下,尽快地增加发送数据的速率。
它通过逐渐增加发送窗口大小来试探网络的承载能力,避免一开始就发送大量数据导致网络拥塞
另外为了防止发送窗口无限制地增长,设置了一个慢启动阈值(ssthresh)。当发送窗口大小超过这个阈值时,就会进入拥塞避免阶段。
拥塞避免(Congestion - Avoidance)
当发送窗口大小超过慢启动阈值后,进入拥塞避免阶段,在这个阶段,发送窗口不再是指数增长,而是线性增长。
发送端每收到一个 ACK,就将发送窗口大小增加一个 MSS 的一小部分(通常为 1/MSS)。
例如,发送窗口大小为 16MSS,每收到一个 ACK,窗口大小增加 1/16MSS,这样发送窗口会以较为缓慢的速度增长,避免过快地占用网络资源。
拥塞避免阶段的主要目的是在网络已经有一定负载的情况下,更加谨慎地增加发送数据的速率,以防止网络出现拥塞。
通过线性增长发送窗口大小,可以更好地利用网络的剩余带宽,同时降低拥塞的风险。
快重传(Fast - Retransmit)
当接收端收到一个失序的报文段时,会立即发送重复的 ACK,通知发送端这个报文段可能丢失。
如果发送端连续收到三个重复的 ACK,就会认为这个报文段确实丢失了,不等超时定时器超时,就立即重传这个丢失的报文段。
例如,发送端发送了报文段 1、2、3,接收端收到了报文段 1 和 3,但没有收到报文段 2,此时认为 2 丢失了,因为已经收到了 3,但是未收到 2,接收端就会连续发送针对报文段 1 的 ACK,当发送端收到三个这样的重复 ACK 时,就会快速重传报文段 2。
目的:快重传机制可以避免发送端等待较长的超时时间才重传丢失的报文段,从而减少数据传输的延迟,提高网络的传输效率。它能够在网络出现少量丢包的情况下,快速地恢复数据传输。
快恢复(Fast - Recovery)
快恢复机制可以在网络出现少量丢包的情况下,更快地恢复数据传输的正常速率,避免了重新进行慢启动导致的发送速率过度降低,从而提高了网络的整体性能和传输效率。
与传统的慢启动过程相比,它不需要从一个很小的初始窗口重新开始增长,而是基于网络可能还有一定传输能力的判断,发送端将慢启动阈值(ssthresh)设置为当前发送窗口大小的一半,然后将发送窗口大小设置为新的 ssthresh 加上 3 个 MSS(这是因为收到了三个重复的 ACK,说明网络可能还可以传输一定的数据)。
之后,发送端在拥塞避免阶段的规则下继续增加发送窗口大小。
说一下什么是半连接队列 #
在 TCP(Transmission Control Protocol)三次握手建立连接的过程中,服务器端会维护一个队列,这个队列用来保存处于 SYN_RECV 状态(即接收到客户端的 SYN 报文并已回复 SYN + ACK 报文,但还未收到客户端的 ACK 报文)的连接请求,这个队列就被称为半连接队列。
半连接队列在 TCP 三次握手过程中的作用
半连接队列的大小设置及影响因素
什么是 SYN 攻击? #
SYN 攻击(SYN Flood 攻击)是一种典型的分布式拒绝服务(DDoS)攻击方式。
它利用了 TCP(Transmission Control Protocol)三次握手协议的机制,通过向目标服务器发送大量伪造的 TCP SYN(同步序列号)请求报文,使服务器的资源耗尽,从而无法正常处理合法用户的连接请求。
SYN 攻击的原理
正常的 TCP 三次握手过程
SYN 攻击过程
SYN 攻击的危害
如何防范 SYN 攻击
UDP #
UDP 的特点 #
- 无连接:UDP 是无连接的协议,不需要进行握手和断开连接的操作,因此传输效率较高。
- 不可靠:UDP 不保证数据的可靠传输,数据包可能会丢失、重复或乱序。对于一些对数据完整性要求较高的应用场景,不适合使用 UDP。
- 面向数据报:UDP 是面向数据报的协议,每个数据包都是独立的,没有先后顺序的要求。
- 没有拥塞控制:UDP 没有拥塞控制机制,当网络拥塞时可能会导致数据包丢失或延迟。
- 适用于实时性要求高的应用:由于 UDP 传输速度快,适用于对实时性要求高的应用,如音视频传输、在线游戏等。
- 简单轻量:UDP 的头部较小,传输效率高,适用于一些对传输延迟要求较高的应用场景。
🌟TCP 和 UDP 的区别 #
🌟TCP 的应用场景 #
- TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。
- TCP 不提供广播或多播服务。
- 由于 TCP 要提供可靠的面向连接的传输服务,TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制。在数据传完后,还会断开连接用来节约系统资源,难以避免增加了许多开销,如消息确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
🌟UDP 的应用场景 #
- 广播:因为其可以一对多进行发送,所以可用于广播
- 实时游戏:因为
TCP如果丢包,则会等待这个包进行重发,这样就会卡住,有可能出现,恢复传输后,游戏角色已经死亡的情况 - 网页或者 app 的访问:如 QUIC
- 实时视频和音频传输:如视频会议、游戏语音聊天。
TCP/IP 数据包格式和端口 #
网络层功能 #
OSI 网络层具有以下功能:
- 逻辑寻址:将数据包从一个网络发送到另一个网络需要逻辑寻址。它有助于区分源系统和目标系统。网络层会在来自上层的数据上添加一个头部,包含发送方和接收方的逻辑地址。网络中的每个主机都必须有一个唯一的地址,以确定其位置。这个地址通常是从一个分层系统中分配的。
- 路由:由于网络被划分为子网并连接到其他网络以进行广域通信,网络使用网关或路由器来路由数据包到它们的最终目的地。这也被称为转发数据包(第 3 层协议数据单元)的过程。
- 路由协议:路由器用于动态了解网络中地址的协议,以便在路由或转发过程中进行决策。
IP 数据包 #
IP 数据包由一个头部和有效载荷组成,如图所示。
IP 头部 #
IPv4 数据包头部包含以下内容:
- 4 位版本号:指定这是 IPv4 还是 IPv6 数据包。
- 4 位互联网头部长度:头部的长度,以 4 字节的倍数表示(例如,5 表示 20 字节)。
- 8 位服务类型:也称为服务质量(QoS),描述数据包应具有的优先级。
- 16 位数据包长度:数据包的长度,以字节为单位。
- 16 位标识符:帮助从多个片段中重建数据包的标识标签。
- 3 位标志:第一位为 0,第二位表示数据包是否允许被分片(DF 或不分片),第三位表示是否还有更多数据包片段(MF 或更多片段)。
- 13 位片段偏移量:用于标识片段在原始数据包中的位置。
- 8 位生存时间(TTL):数据包允许通过的跳数(路由器、计算机或网络中的设备)。例如,TTL 为 16 的数据包将被允许通过 16 个路由器到达目的地,然后才会被丢弃。
- 8 位协议:(TCP、UDP、ICMP 等)。
- 16 位头部校验和:用于错误检测的数字。
- 32 位源 IP 地址。
- 32 位目标地址。
在这些 160 位之后,可以根据使用的协议添加可变长度的可选标志,然后是数据包携带的数据。IP 数据包没有尾部。然而,IP 数据包通常作为有效载荷被封装在以太网帧中,以太网帧有自己的头部和尾部。
IPV6 数据格式如图:
IP 路由 #
数据包通过一个或多个路由器和网络从源路由到目的地。IP 路由协议使路由器能够建立一个转发表,将最终目标地址与下一跳地址关联起来。用于路由的各种协议包括边界网关协议(BGP)、中间系统 - 中间系统(IS-IS)、开放最短路径优先(OSPF)和路由信息协议(RIP)。
IP 路由是逐跳进行的。IP 不知道到任何目的地的完整路径(除了直接连接的)。IP 路由提供下一跳路由器的 IP 地址,数据将被发送到该路由器,假设下一跳路由器更接近目的地。IP 路由执行以下操作:
- 在路由表中查找与完整目标 IP 地址(匹配网络 ID 和主机 ID)匹配的条目。如果找到,将数据包发送到指定的下一跳路由器或直接连接的接口。
- 在路由表中查找仅与目标网络 ID 匹配的条目。如果找到,将数据包发送到指定的下一跳路由器或直接连接的接口。目标网络上的所有主机都可以通过这一条路由表条目来处理。
- 在路由表中查找标记为“默认”的条目。如果找到,将数据包发送到指定的下一跳路由器。
如果以上步骤都无法完成,数据报将无法投递。如果无法投递的数据报是在本主机生成的,则通常会向生成数据报的应用程序返回“主机不可达”或“网络不可达”错误。路由表中的每个条目包括以下内容:
- 数据报应通过哪个网络接口进行传输。
- 目标 IP 地址。它是一个主机地址或网络地址,由标志字段指定。主机地址的主机 ID 非零,标识特定的主机,而网络地址的主机 ID 为 0,标识该网络上的所有主机。
- 下一跳路由器的 IP 地址或直接连接的网络。下一跳路由器不是最终目的地,但它会将数据转发到最终目的地。
- 一个标志指定目标 IP 地址是网络地址还是主机地址。另一个标志说明下一跳路由器字段是否真的是下一跳路由器,还是直接连接的接口。
IP 路由协议将有效的、无环路的路由加载到路由表中,涉及以下功能:
- 如果到一个子网有多个路由可用,则放置最佳路由。
- 从路由表中移除无效路由。
- 动态学习并为所有子网加载路由表。
- 快速用最佳可用路由替换丢失的路由,这也被称为收敛时间。
- 防止路由环路。
每个路由协议都会发布其路由,如下所示:
- 为直接连接到它的每个子网添加一条路由。
- 更新邻居路由器关于所有直接连接和已学习的路由的信息。
- 从邻居那里添加新路由。
IP 寻址 #
IP 地址是一个 32 位二进制数,如下所示:
00000100 10000000 00000011 00000001
它被分成四个 8 位块,称为八位组,并以十进制数字表示,以便人类理解,例如 4.128.3.1。IP 地址由两部分组成:
- 最左边的位指定网络地址部分,称为网络 ID。
- 最右边的位指定主机地址部分,称为主机 ID。
同一网络中的主机可以通过 MAC 地址相互通信,但对于不同网络,需要一个路由器来移动数据。每个局域网都有一个唯一的网络 ID,该网络上的所有主机都有相同的网络 ID,但主机 ID 不同。网络 ID 使路由器能够将数据包放到正确的网络段上。为了决定哪个网络是正确的,路由器会查找路由表,这是一个包含网络地址(网络 ID + 所有主机位都设为 0)的条目的表。每个网络接口使用一个唯一的 IP 地址。
A、B 和 C 类网络 #
IP 地址被划分为不同的类别,以适应不同规模的网络,如下所示:
- A 类(1-126):它支持非常大的网络,只使用第一个八位组作为网络地址,其余三个八位组用于主机地址。A 类地址的第一个位始终为 0,但最低数字表示的是 00000000(十进制 0),最高数字是 01111111(十进制 127),这两个数字都被保留,不能用作网络地址。任何以 127 开头的地址都保留用于环回。
- B 类(128-191):它支持中型和大型网络,前两个八位组用于网络地址,其余两个八位组用于主机地址。B 类地址的前两位是二进制数 10;因此,最低数字表示的是 10000000(十进制 128),最高数字是 1011111(十进制 191)。
- C 类(192-223):它支持小型网络,前三个八位组用于网络地址,剩下的一个八位组用于主机地址。C 类地址的前三位是二进制数 110,因此,最低数字表示的是 11000000(十进制 192),最高数字是 11011111(十进制 223)。
- D 类:224-239 保留用于多播,允许一个站点同时向多个接收者发送数据报。它的前四位是二进制数 1110。
- E 类:240-255 是实验地址,由 IETF 保留用于研究。
每个类别的开头和结尾的块分别称为网络地址和广播地址。这两个特殊的 IP 地址被保留,详细说明如下:
- 网络地址:所有主机位都设为 0,以标识网络本身,不能被分配,例如 46.0.0.0 是包含主机 46.4.64.
21 的网络的网络地址。
- 广播地址:所有主机位都设为 1,用于向网络上的所有设备发送数据,例如 46.255.255.255 是包含主机 46.4.64.21 的网络的广播地址。路由器会在所有接口上转发广播数据包,但通常路由器会禁用广播转发。
A、B、C、D、E 类 IP 地址的列表总结如下:
互联网名称与数字地址分配机构(ICANN,www.icann.org)负责全球 IP 地址的分配,ICANN 将区域权限分配给其他合作组织。
传输控制协议 #
TCP 是一种面向连接的、可靠的协议。TCP 必须在两端用户应用程序之间建立连接(虚拟电路),然后才能进行数据传输。TCP 提供的服务运行在两端的主机计算机上,而不是在网络中。因此,TCP 协议管理端到端的连接。TCP 在 RFC 793 中定义,并完成以下功能:
- 将从会话层传递下来的消息分割成多个段。
- 为每个段添加序列号以进行排序。
- 验证从网络层传递到目标端的每个段。
- 重新组装接收到的段以形成消息。
- 将消息传递到会话层。
无论端点的位置如何,TCP 都以相同的方式执行其功能。TCP 段结构如下图所示:
TCP 头部包含 11 个字段,其中只有 10 个是必需的。第十一个字段是可选的,称为“选项”。TCP 头部字段的详细信息如下:
- 源端口(16 位):标识发送端口。
- 目标端口(16 位):标识接收端口。
- 序列号(32 位):确保到达数据的正确排序。
- 确认号(32 位):下一个期望的 TCP 字节。
- 保留(4 位):保留供将来使用,设为零。
- 标志(8 位)(或控制位):包含 8 个 1 位标志。
- 窗口(16 位):接收方目前愿意接收的字节数。
- 校验和(16 位):用于头部和数据的错误检查。
- 紧急指针(16 位):指示紧急数据的结束位置。
- 选项(可变 0-320 位,以 32 为倍数):其长度由数据偏移字段决定。选项 0 和 1 的长度为一个字节(8 位)。其余选项在第二个字节中指示总长度(以字节为单位)。
TCP 报头标志位(Flags) #
NS(Nonce Sum,1 位)
- 作用:用于 ECN(显式拥塞通知)的非隐蔽保护,防止恶意利用 ECN 机制(RFC 3540)。
- 扩展功能:属于 TCP 扩展选项,实验性字段。
CWR(Congestion Window Reduced,1 位)
- 作用:发送方设置此标志,表示已收到带有 ECE 标志的报文,并已通过减少拥塞窗口来响应拥塞(RFC 3168)。
- 场景:用于显式拥塞控制(ECN)。
ECE(ECN-Echo,1 位)
- 作用:
- 在建立连接(SYN=1 时)时,表示支持 ECN 功能。
- 在数据传输(SYN=0 时)时,表示接收到了拥塞通知(IP 头部 ECN=11 的报文)。
- 扩展功能:与 CWR 配合实现显式拥塞控制(RFC 3168)。
- 作用:
URG(Urgent,1 位)
- 作用:紧急指针有效标志。若置 1,表示数据中包含紧急数据,需优先处理。
- 关联字段:紧急指针(Urgent Pointer)指定紧急数据的位置。
ACK(Acknowledgment,1 位)
- 作用:确认号有效标志。若置 1,表示报文的确认号(Acknowledgment Number)有效。
- 场景:除初始 SYN 报文外,所有报文 ACK 标志通常置 1。
PSH(Push,1 位)
- 作用:要求接收方立即将数据提交给应用层,无需等待缓冲区填满。
- 应用:适用于实时性要求高的场景(如 Telnet)。
RST(Reset,1 位)
- 作用:强制重置连接。用于拒绝非法连接请求或异常中断连接。
- 场景:服务端拒绝连接或检测到严重错误时发送 RST 报文。
SYN(Synchronize,1 位)
- 作用:同步序列号,用于建立 TCP 连接。
- 三次握手:在 SYN 报文中携带初始序列号(ISN)。
FIN(Finish,1 位)
- 作用:终止连接标志。发送方数据已传输完毕,请求释放连接。
- 四次挥手:双方各发送一次 FIN 报文以关闭连接。
TCP 错误恢复、流量控制和数据分段 #
错误恢复 #
TCP 通过在头部使用序列号和确认号字段为可靠的数据传输或可靠性或错误恢复提供支持。TCP 被设计为能够从节点或线路故障中恢复,其中网络会将路由表更改传播到所有路由器节点,但 TCP 在启动恢复时相对较慢。
TCP 将数据视为字节流。它逻辑上为每个字节分配一个序列号。TCP 数据包的头部会说明,“这个数据包从字节 379642 开始,包含 200 个字节的数据。”接收方可以检测到丢失或排序错误的数据包。TCP 会确认已接收的数据,并重新传输丢失的数据。错误恢复是在客户端和服务器之间端到端进行的。例如,服务器向客户端发送 1000 个字节的数据,TCP 头部使用序列号 1000。服务器又发送了 1000 个字节的数据,序列号为 2000,然后又发送了 1000 个字节的数据,序列号为 3000。接下来,客户端向服务器发送确认,确认已成功接收 3000 个字节。确认字段中的 4000 表示下一个要接收的字节。
使用滑动窗口的流量控制 #
TCP 通过在头部使用序列号、确认号和窗口字段实现流量控制。窗口字段指定在任何时间点允许未确认的字节数的最大值。窗口最初较小,然后会不断增大,直到出现错误,因此也被称为动态窗口。随着实际的序列号和确认号随时间增长,窗口也被称为滑动窗口。其工作方式如下:
- 当失败的确认提示发送方放慢速度或停止发送时,丢弃数据段。
- 设置较小的窗口大小,因为每个 TCP 确认都包含一个名为窗口大小的字段,该字段指定接收 TCP 当前准备接收的字节数。将窗口大小设置为较小的值允许在未来处理较少的数据。更具体地说,窗口大小是发送方在
从接收方获得确认之前允许发送的数据段的数量。较小的窗口大小意味着发送 TCP 必须等待更多的确认才能发送相同数量的数据,因此,这些额外的确认所导致的时间延迟会减慢数据传输过程。
如果在窗口完成之前收到确认,将开始一个新的窗口,发送方将继续发送数据,直到当前窗口完成。滑动窗口机制也被称为正确认证和重传(PAR)。
数据分段和有序数据传输 #
不同的数据链路协议对可以在数据链路层帧内发送的最大传输单元(MTU)有不同的限制。因此,MTU 是可以放入帧的数据字段中的最大第 3 层数据包的大小,例如,对于以太网,IP 数据包小于 1500 字节,因此,TCP 将数据分段成较小的部分,称为段,通常为 1460 字节的块,并为它们分配序列号。在接收端,TCP 重新组装段,并恢复丢失的段。
在传输过程中,段可能会以错误的顺序到达,因此,接收端的 TCP 执行有序数据传输,通过重新组装数据到原始顺序来实现,例如,如果段以 1500、3500 和 2500 的序列号到达,每个段都包含 1000 字节的数据,接收方可以在不重新传输的情况下重新排序它们。TCP 头部和数据字段一起被称为 TCP 段或 L4 PDU,因为 TCP 是第 4 层协议。
TCP 连接建立和终止 #
连接建立指的是初始化序列号和确认号字段,并就使用哪个端口号达成一致的过程。这是一个三步过程,连接建立使用 TCP 头部中的两个标志位,即 SYN 和 ACK 标志。SYN 表示“同步序列号”,用于初始化序列号,ACK 字段表示“此头部中的确认字段有效”,用于确认收到的序列号。要建立连接,两个终端站必须对彼此的初始 TCP 序列号进行同步。这种初始交换确保了可以恢复丢失的数据。同步的步骤如下:
- A → B SYN - 我的序列号是 X
- A ← B ACK - 你的序列号是 X - 1;期望下一个为 X + 1
- A ← B SYN - 我的序列号是 Y
- A → B ACK - 你的序列号是 Y - 1;期望下一个为 Y + 1
由于步骤 2 和 3 被合并成一条消息,因此被称为三次握手。TCP 连接终止是一个四步过程,使用了一个额外的标志,称为 FIN 位(或“完成”)。TCP 在端点之间建立和终止连接,而 UDP 则不这样做,因此,根据连接管理协议,可以分为以下两类:
- 面向连接的协议:一种需要在数据传输开始之前进行消息交换的协议,或者在两个端点之间有一个必需的预先建立的关联。
- 无连接协议:一种不需要进行消息交换且不需要在两个端点之间预先建立关联的协议。
UDP(用户数据报协议) #
UDP 是一种无连接且不确认的协议,以“尽力而为”的方式传输消息,不对段的投递进行检查。UDP 依赖上层协议来实现可靠性。在网络中,广播和单播消息由 UDP 携带,使用 UDP 的协议包括 TFTP、SNMP、NFS 和 DNS。UDP 头部仅包含 4 个字段,其中两个是可选的(已突出显示),如下图所示:
- 源端口:调用端的标识符。
- 目标端口:被调用端的标识符。
- 长度:UDP 头部和 UDP 数据的长度。
- 校验和:头部和数据字段的计算校验和。
UDP 没有重新排序或恢复机制。然而,UDP 与 TCP 一样使用端口号进行数据传输和多路复用,但 UDP 使用的字节开销和处理量比 TCP 少。因此,使用 UDP 的应用程序应该能够容忍数据丢失。VoIP 使用 UDP,因为发现并重新传输丢失的语音数据包所需的时间会增加太多延迟。同样,任何 DNS 请求失败都会被重新尝试。
网络安全篇 #
什么是 XSS 攻击? #
它指的是恶意攻击者往 Web 页面里插入恶意 html 代码,当用户浏览该页之时,嵌入其中 Web 里面的 html 代码会被执行,从而达到恶意攻击用户的特殊目的。
XSS 的攻击方式就是想办法“教唆”用户的浏览器去执行一些这个网页中原本不存在的前端代码。
相信以上的解释也不难理解,但为了再具体些,这里举一个简单的例子,就是留言板。
我们知道留言板通常的任务就是把用户留言的内容展示出来。
正常情况下,用户的留言都是正常的语言文字,留言板显示的内容也就没毛病。然而这个时候如果有人不按套路出牌,在留言内容中丢进去一行
<script>alert(“hey!you are attacked”)</script>
那么这个时候问题就来了,当浏览器解析到用户输入的代码那一行时会发生什么呢?答案很显然,浏览器并不知道这些代码改变了原本程序的意图,会照做弹出一个信息框。就像这样
<html>
<head>
<title>留言板</title>
</head>
<body>
<div id=”board”
<script>alert(“hey!you are attacked”)</script>
</div>
</body>
</html>
如何解决 xss 攻击? #
- 不相信用户输入:除了不相信用户输入,还应对所有输入进行严格的验证和清理。可以使用白名单原则,只允许符合特定格式的输入。
- 限制输入长度:不同类型的输入设定合理的长度限制,以防止缓冲区溢出等攻击。
- HTML 转义:在输出到网页之前,确保对所有用户输入进行 HTML 转义。可以使用现有的库(如 OWASP Java Encoder 或 JavaScript 的 DOM API)来处理转义,以减少出错的可能性。
- 对跳转型链接进行特殊对待:对于跳转链接,建议使用相对路径而非绝对路径,并确保目标链接的域名在允许的白名单中。此外,可以考虑使用 rel=“noopener noreferrer” 属性来防止潜在的安全风险。
- 使用内容安全策略(CSP):实施 CSP 可以帮助限制哪些资源可以被加载,降低 XSS 攻击的风险。通过配置 CSP,可以阻止不受信任的脚本执行。
- 使用安全库和框架:使用经过审计的安全库和框架来处理用户输入和输出。许多现代框架(如 React、Angular、Vue)内置了防护机制,可以减少 XSS 风险。
🌟半连接队列和 SYN Flood 攻击的关系 #
TCP 进入三次握手前,服务端会从 CLOSED 状态变为 LISTEN 状态,同时在内部创建了两个队列:半连接队列(SYN 队列)和全连接队列(ACCEPT 队列)。
什么是半连接队列(SYN 队列) 呢? 什么是全连接队列(ACCEPT 队列) 呢?回忆下 TCP 三次握手的图:
- TCP 三次握手时,客户端发送 SYN 到服务端,服务端收到之后,便回复 ACK 和 SYN,状态由 LISTEN 变为 SYN_RCVD,此时这个连接就被推入了 SYN 队列,即半连接队列。
- 当客户端回复 ACK, 服务端接收后,三次握手就完成了。这时连接会等待被具体的应用取走,在被取走之前,它被推入 ACCEPT 队列,即全连接队列。
SYN Flood 是一种典型的 DoS (Denial of Service,拒绝服务) 攻击,它在短时间内,伪造不存在的 IP 地址,向服务器大量发起 SYN 报文。当服务器回复 SYN+ACK 报文后,不会收到 ACK 回应报文,导致服务器上建立大量的半连接半连接队列满了,这就无法处理正常的 TCP 请求啦。
主要有 syn cookie 和 SYN Proxy 防火墙 等方案应对:
- syn cookie:在收到 SYN 包后,服务器根据一定的方法,以数据包的源地址、端口等信息为参数计算出一个 cookie 值作为自己的 SYNACK 包的序列号,回复 SYN+ACK 后,服务器并不立即分配资源进行处理,等收到发送方的 ACK 包后,重新根据数据包的源地址、端口计算该包中的确认序列号是否正确,如果正确则建立连接,否则丢弃该包。
- SYN Proxy 防火墙:服务器防火墙会对收到的每一个 SYN 报文进行代理和回应,并保持半连接。等发送方将 ACK 包返回后,再重新构造 SYN 包发到服务器,建立真正的 TCP 连接。
socket 的执行过程 #
有几个关键点:
- 在
connect位置进行三次握手 - IO 多路复用发生在
accept函数之后 - 监听的是已经建立好连接准备发送数据的
socket - 说 TCP 的
socket就是一个文件流,是非常准确的。因为,socket在 Linux 中就是以文件的形式存在的。除此之外,还存在文件描述符,写入和读出,也是通过文件描述符。 socket是一个文件,那么就有文件描述符,socket对应的文件不是存在磁盘中的,是存在内存中的,方便快速传输。- 服务端一般是
listen一个端口,然后理论上的最大连接数,则和客户端 ip 地址的数目和端口号的数目有关,则是2^32 * 2^16次方。但是现实中不能够连接那么多,因为 socket 文件是存储在内存中的,有内存限制,而且文件描述符的个数也有所限制。